Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition

0

Sign in to get full access
Overview
- Micro-expression analysis is important for understanding human emotions and behavior
- This paper proposes a new approach called "Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition"
- The approach involves jointly spotting and recognizing micro-expressions in long video sequences
- It uses a state space model to capture the temporal dynamics of micro-expressions
Plain English Explanation
Micro-expressions are subtle facial movements that can reveal a person's true emotions, even if they are trying to hide them. Analyzing micro-expressions is valuable for applications like psychology, security, and human-computer interaction. However, it can be challenging to accurately detect and classify micro-expressions, especially in long video recordings.
The researchers developed a new technique that addresses these challenges. Their approach involves two key steps:
-
Spotting: The system first identifies the specific moments in a video where a micro-expression is occurring. This is known as "spotting" the micro-expression.
-
Recognition: Once a micro-expression has been spotted, the system then classifies it into one of the basic emotion categories (e.g., happiness, anger, disgust, etc.).
The key innovation is that the spotting and recognition steps are performed together, in a "synergistic" manner. This allows the system to take advantage of the relationships between the timing and appearance of micro-expressions to improve the overall accuracy.
The technique uses a state space model to capture the temporal dynamics of micro-expressions. This helps the system better understand how micro-expressions evolve over time, which is important for handling long video sequences.
Overall, this research provides a more robust and accurate way to analyze micro-expressions, with applications in fields like psychology, security, and human-computer interaction.
Technical Explanation
The proposed "Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition" approach consists of three main components:
-
Micro-Expression Spotting: The system first uses a convolutional neural network (CNN) to process the input video frames and generate spatial-temporal feature maps. These features are then fed into a state space model that captures the temporal dynamics of micro-expressions. This state space model is used to identify the specific frames where a micro-expression is occurring.
-
Micro-Expression Recognition: Once a micro-expression has been spotted, the system then classifies it into one of the basic emotion categories. This is done using a separate CNN-based classifier, which takes the spotted micro-expression region as input and outputs the predicted emotion label.
-
Synergistic Learning: The spotting and recognition components are trained jointly in an end-to-end manner, allowing them to benefit from each other's outputs. This "synergistic" approach helps improve the overall accuracy compared to performing the two tasks separately.
The experiments in the paper demonstrate that this approach outperforms previous state-of-the-art methods for micro-expression analysis on several benchmark datasets, especially when dealing with long video sequences.
Critical Analysis
The paper provides a comprehensive and well-designed approach for micro-expression analysis, addressing the challenges of accurately spotting and recognizing micro-expressions in long video recordings.
One potential limitation is that the system relies on a pre-defined set of basic emotion categories for the recognition task. In real-world scenarios, people may exhibit more complex or nuanced emotional states that may not fit neatly into these categories. Further research could explore techniques for more fine-grained or open-ended micro-expression recognition.
Additionally, the paper does not discuss the computational efficiency or real-time performance of the proposed approach. For applications that require rapid micro-expression analysis, such as security or human-computer interaction, the system's inference speed would be an important consideration.
Overall, the research represents a significant advance in the field of micro-expression analysis and provides a solid foundation for future work in this area.
Conclusion
This paper presents a novel approach called "Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition" for analyzing micro-expressions in long video sequences. The key innovation is the joint optimization of the micro-expression spotting and recognition tasks, which allows the system to leverage the temporal dynamics of micro-expressions to improve overall accuracy.
The proposed technique outperforms previous state-of-the-art methods and demonstrates promising results for applications in psychology, security, and human-computer interaction. While the paper has some limitations, it represents an important step forward in the field of micro-expression analysis and opens up new avenues for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition
Bochao Zou, Zizheng Guo, Wenfeng Qin, Xin Li, Kangsheng Wang, Huimin Ma
Micro-expressions are involuntary facial movements that cannot be consciously controlled, conveying subtle cues with substantial real-world applications. The analysis of micro-expressions generally involves two main tasks: spotting micro-expression intervals in long videos and recognizing the emotions associated with these intervals. Previous deep learning methods have primarily relied on classification networks utilizing sliding windows. However, fixed window sizes and window-level hard classification introduce numerous constraints. Additionally, these methods have not fully exploited the potential of complementary pathways for spotting and recognition. In this paper, we present a novel temporal state transition architecture grounded in the state space model, which replaces conventional window-level classification with video-level regression. Furthermore, by leveraging the inherent connections between spotting and recognition tasks, we propose a synergistic strategy that enhances overall analysis performance. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The codes and pre-trained models are available at https://github.com/zizheng-guo/ME-TST.
Read more9/17/2024

0
SpotFormer: Multi-Scale Spatio-Temporal Transformer for Facial Expression Spotting
Yicheng Deng, Hideaki Hayashi, Hajime Nagahara
Facial expression spotting, identifying periods where facial expressions occur in a video, is a significant yet challenging task in facial expression analysis. The issues of irrelevant facial movements and the challenge of detecting subtle motions in micro-expressions remain unresolved, hindering accurate expression spotting. In this paper, we propose an efficient framework for facial expression spotting. First, we propose a Sliding Window-based Multi-Resolution Optical flow (SW-MRO) feature, which calculates multi-resolution optical flow of the input image sequence within compact sliding windows. The window length is tailored to perceive complete micro-expressions and distinguish between general macro- and micro-expressions. SW-MRO can effectively reveal subtle motions while avoiding severe head movement problems. Second, we propose SpotFormer, a multi-scale spatio-temporal Transformer that simultaneously encodes spatio-temporal relationships of the SW-MRO features for accurate frame-level probability estimation. In SpotFormer, our proposed Facial Local Graph Pooling (FLGP) and convolutional layers are applied for multi-scale spatio-temporal feature extraction. We show the validity of the architecture of SpotFormer by comparing it with several model variants. Third, we introduce supervised contrastive learning into SpotFormer to enhance the discriminability between different types of expressions. Extensive experiments on SAMM-LV and CAS(ME)^2 show that our method outperforms state-of-the-art models, particularly in micro-expression spotting.
Read more7/31/2024
0
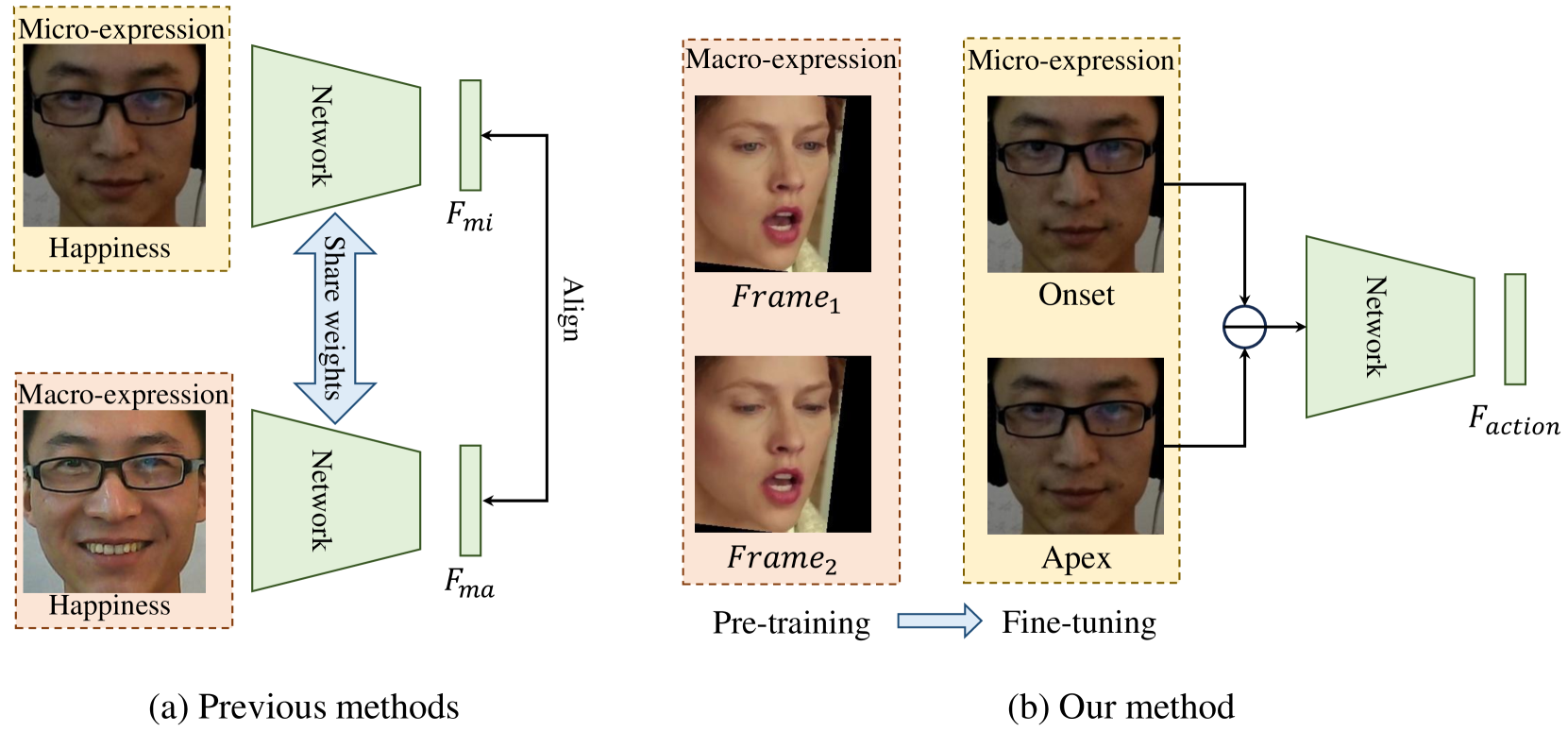
From Macro to Micro: Boosting micro-expression recognition via pre-training on macro-expression videos
Hanting Li, Hongjing Niu, Feng Zhao
Micro-expression recognition (MER) has drawn increasing attention in recent years due to its potential applications in intelligent medical and lie detection. However, the shortage of annotated data has been the major obstacle to further improve deep-learning based MER methods. Intuitively, utilizing sufficient macro-expression data to promote MER performance seems to be a feasible solution. However, the facial patterns of macro-expressions and micro-expressions are significantly different, which makes naive transfer learning methods difficult to deploy directly. To tacle this issue, we propose a generalized transfer learning paradigm, called textbf{MA}cro-expression textbf{TO} textbf{MI}cro-expression (MA2MI). Under our paradigm, networks can learns the ability to represent subtle facial movement by reconstructing future frames. In addition, we also propose a two-branch micro-action network (MIACNet) to decouple facial position features and facial action features, which can help the network more accurately locate facial action locations. Extensive experiments on three popular MER benchmarks demonstrate the superiority of our method.
Read more6/5/2024
0
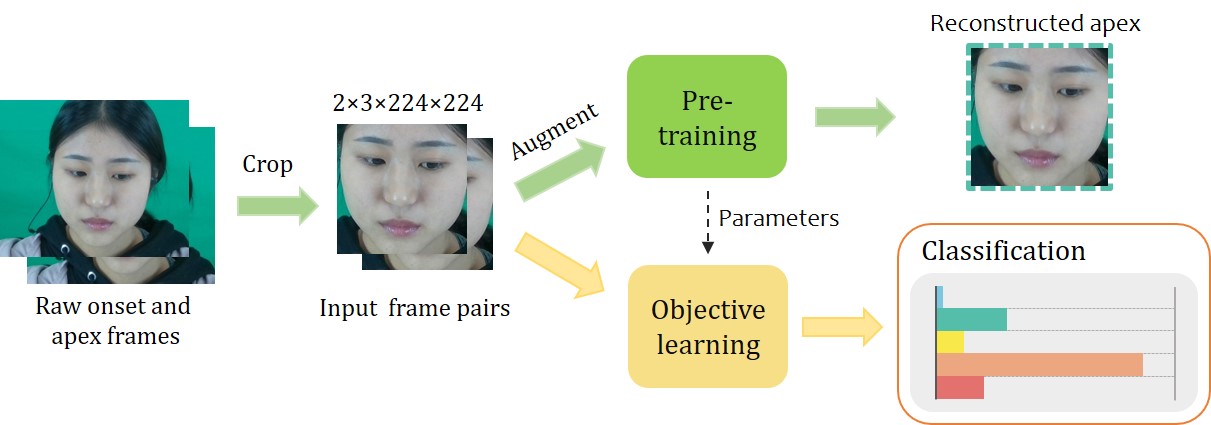
Micro-Expression Recognition by Motion Feature Extraction based on Pre-training
Ruolin Li, Lu Wang, Tingting Yang, Lisheng Xu, Bingyang Ma, Yongchun Li, Hongchao Wei
Micro-expressions (MEs) are spontaneous, unconscious facial expressions that have promising applications in various fields such as psychotherapy and national security. Thus, micro-expression recognition (MER) has attracted more and more attention from researchers. Although various MER methods have emerged especially with the development of deep learning techniques, the task still faces several challenges, e.g. subtle motion and limited training data. To address these problems, we propose a novel motion extraction strategy (MoExt) for the MER task and use additional macro-expression data in the pre-training process. We primarily pretrain the feature separator and motion extractor using the contrastive loss, thus enabling them to extract representative motion features. In MoExt, shape features and texture features are first extracted separately from onset and apex frames, and then motion features related to MEs are extracted based on the shape features of both frames. To enable the model to more effectively separate features, we utilize the extracted motion features and the texture features from the onset frame to reconstruct the apex frame. Through pre-training, the module is enabled to extract inter-frame motion features of facial expressions while excluding irrelevant information. The feature separator and motion extractor are ultimately integrated into the MER network, which is then fine-tuned using the target ME data. The effectiveness of proposed method is validated on three commonly used datasets, i.e., CASME II, SMIC, SAMM, and CAS(ME)3 dataset. The results show that our method performs favorably against state-of-the-art methods.
Read more7/11/2024