Synthesizing Realistic Data for Table Recognition

0
Sign in to get full access
Overview
• This paper presents a method for synthesizing realistic table data to improve table recognition models. • The authors develop a data augmentation approach that can generate synthetic tables with realistic layout, content, and formatting. • The synthetic tables are used to train a table recognition model, which achieves improved performance on real-world datasets.
Plain English Explanation
The goal of this research is to make it easier for AI systems to accurately recognize and understand tables in documents. Tables can be challenging for AI to process because they have complex structures and formats that vary widely.
To address this, the researchers developed a way to automatically generate artificial tables that look and behave like real tables. They call this "data augmentation" - creating new training data to help the AI learn.
The key insight is that by training on a mix of real and synthetic tables, the model can learn more robust features for table recognition. The synthetic tables are designed to capture the diversity and nuances of real-world tables, so the model becomes better equipped to handle the messiness of tables found in the wild.
The authors show that using this synthetic data improves the performance of table recognition models compared to training only on real data. This suggests it is a promising approach for advancing table understanding in AI systems. The synthetic tables can serve as a sort of "data amplifier" to compensate for the limited availability of annotated table examples.
Technical Explanation
The paper introduces a method for synthesizing realistic table data to augment training data for table recognition models. The synthetic tables are generated to mimic the layout, content, and formatting characteristics of real-world tables.
Key components of the approach include:
- A generative model that can produce diverse table layouts, including nested structures and varied alignment/spacing
- A content model that generates realistic textual and numeric cell values, drawing from relevant distributions
- A formatting model that applies realistic styling (fonts, borders, backgrounds) to the tables
The synthetic tables are used to train a table recognition model in a data augmentation setup. Experiments show that this improves performance on real-world table datasets compared to training only on the limited available annotated data.
Critical Analysis
The authors acknowledge that their synthetic tables may not fully capture the complexity and diversity of real-world tables. There is a risk of the model overfitting to the characteristics of the generated data, limiting its ability to generalize.
Additionally, the paper does not provide a thorough analysis of the trade-offs between data quantity and data quality. It's unclear whether generating large volumes of lower-fidelity synthetic data would be more beneficial than a smaller set of high-quality examples.
Further research could explore ways to better model the nuances of real tables, perhaps by incorporating insights from existing table recognition systems. Evaluating the generalization of the trained models across a broader range of table types and use cases would also be valuable.
Conclusion
This paper presents a promising approach for generating synthetic table data to improve the performance of table recognition models. By creating realistic-looking tables, the researchers are able to augment the limited training data available and boost the robustness of the models.
While the synthetic tables may not fully capture the complexity of real-world tables, this work represents an important step towards more accurate and reliable table understanding in AI systems. The insights and techniques developed here could have broad applicability in document analysis, scientific literature processing, and other domains that rely on tabular data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synthesizing Realistic Data for Table Recognition
Qiyu Hou, Jun Wang, Meixuan Qiao, Lujun Tian
To overcome the limitations and challenges of current automatic table data annotation methods and random table data synthesis approaches, we propose a novel method for synthesizing annotation data specifically designed for table recognition. This method utilizes the structure and content of existing complex tables, facilitating the efficient creation of tables that closely replicate the authentic styles found in the target domain. By leveraging the actual structure and content of tables from Chinese financial announcements, we have developed the first extensive table annotation dataset in this domain. We used this dataset to train several recent deep learning-based end-to-end table recognition models. Additionally, we have established the inaugural benchmark for real-world complex tables in the Chinese financial announcement domain, using it to assess the performance of models trained on our synthetic data, thereby effectively validating our method's practicality and effectiveness. Furthermore, we applied our synthesis method to augment the FinTabNet dataset, extracted from English financial announcements, by increasing the proportion of tables with multiple spanning cells to introduce greater complexity. Our experiments show that models trained on this augmented dataset achieve comprehensive improvements in performance, especially in the recognition of tables with multiple spanning cells.
Read more7/10/2024

0
Latent Diffusion for Guided Document Table Generation
Syed Jawwad Haider Hamdani, Saifullah Saifullah, Stefan Agne, Andreas Dengel, Sheraz Ahmed
Obtaining annotated table structure data for complex tables is a challenging task due to the inherent diversity and complexity of real-world document layouts. The scarcity of publicly available datasets with comprehensive annotations for intricate table structures hinders the development and evaluation of models designed for such scenarios. This research paper introduces a novel approach for generating annotated images for table structure by leveraging conditioned mask images of rows and columns through the application of latent diffusion models. The proposed method aims to enhance the quality of synthetic data used for training object detection models. Specifically, the study employs a conditioning mechanism to guide the generation of complex document table images, ensuring a realistic representation of table layouts. To evaluate the effectiveness of the generated data, we employ the popular YOLOv5 object detection model for training. The generated table images serve as valuable training samples, enriching the dataset with diverse table structures. The model is subsequently tested on the challenging pubtables-1m testset, a benchmark for table structure recognition in complex document layouts. Experimental results demonstrate that the introduced approach significantly improves the quality of synthetic data for training, leading to YOLOv5 models with enhanced performance. The mean Average Precision (mAP) values obtained on the pubtables-1m testset showcase results closely aligned with state-of-the-art methods. Furthermore, low FID results obtained on the synthetic data further validate the efficacy of the proposed methodology in generating annotated images for table structure.
Read more8/20/2024
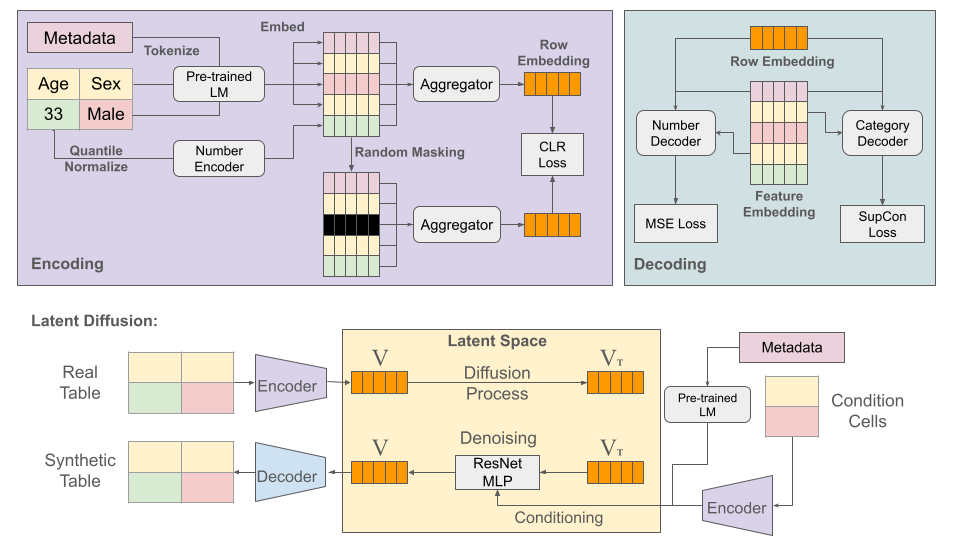
0
CTSyn: A Foundational Model for Cross Tabular Data Generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, Guang Cheng
Generative Foundation Models (GFMs) have produced synthetic data with remarkable quality in modalities such as images and text. However, applying GFMs to tabular data poses significant challenges due to the inherent heterogeneity of table features. Existing cross-table learning frameworks are hindered by the absence of both a generative model backbone and a decoding mechanism for heterogeneous feature values. To overcome these limitations, we introduce the Cross-Table Synthesizer (CTSyn), a diffusion-based foundational model tailored for tabular data generation. CTSyn introduces three major components: an aggregator that consolidates heterogeneous tables into a unified latent space; a conditional latent diffusion model for sampling from this space; and type-specific decoders that reconstruct values of varied data types from sampled latent vectors. Extensive testing on real-world datasets reveals that CTSyn not only significantly outperforms existing table synthesizers in utility and diversity, but also uniquely enhances performances of downstream machine learning beyond what is achievable with real data, thus establishing a new paradigm for synthetic data generation.
Read more6/10/2024
👨🏫
0
ClusterTabNet: Supervised clustering method for table detection and table structure recognition
Marek Polewczyk, Marco Spinaci
We present a novel deep-learning-based method to cluster words in documents which we apply to detect and recognize tables given the OCR output. We interpret table structure bottom-up as a graph of relations between pairs of words (belonging to the same row, column, header, as well as to the same table) and use a transformer encoder model to predict its adjacency matrix. We demonstrate the performance of our method on the PubTables-1M dataset as well as PubTabNet and FinTabNet datasets. Compared to the current state-of-the-art detection methods such as DETR and Faster R-CNN, our method achieves similar or better accuracy, while requiring a significantly smaller model.
Read more5/24/2024