CTSyn: A Foundational Model for Cross Tabular Data Generation

0
Sign in to get full access
Overview
- The paper introduces a foundational model called CTSyn for generating cross-tabular synthetic data that preserves the statistical properties of the original data.
- CTSyn aims to address limitations in existing tabular data synthesis approaches by modeling complex dependencies and relationships within the data.
- The model is designed to be customizable, allowing users to control the generation process and fine-tune the synthetic data to their specific needs.
Plain English Explanation
In the world of data analysis and machine learning, there is often a need to work with sensitive or proprietary datasets that cannot be shared publicly. CTSyn: A Foundational Model for Cross Tabular Data Generation introduces a technique called CTSyn that can generate synthetic versions of these datasets, which can be used for tasks like model training or testing without compromising the privacy of the original data.
The key idea behind CTSyn is to create artificial data that looks and behaves very similarly to the real data, but without containing any of the original sensitive information. This is achieved by modeling the complex relationships and dependencies within the data, which can be challenging for some existing synthetic data generation approaches.
CTSyn allows users to customize the generation process, giving them control over the properties of the synthetic data. For example, they can fine-tune the model to ensure that the generated data maintains important statistical characteristics of the original dataset, such as the distributions of individual variables or the correlations between them.
By providing a flexible and powerful tool for synthetic data generation, CTSyn aims to unlock new possibilities for data-driven research and development, while also safeguarding the privacy and security of sensitive information.
Technical Explanation
CTSyn: A Foundational Model for Cross Tabular Data Generation introduces a novel approach for generating synthetic tabular data that preserves the statistical properties of the original dataset. The key innovation of CTSyn is its ability to model complex dependencies and relationships within the data, which can be challenging for some existing tabular data synthesis techniques like CUTS: Customizable Tabular Synthetic Data Generation, Mixed-Type Tabular Data Synthesis via Score-Based Generative Modeling, or Supervised Generative Optimization Approach for Tabular Data.
The CTSyn model consists of several key components:
-
Conditional Generative Model: CTSyn uses a conditional generative model to capture the complex relationships between the variables in the tabular data. This allows the model to generate new samples that preserve the statistical properties of the original data.
-
Customization Mechanisms: CTSyn provides a range of customization mechanisms that enable users to fine-tune the synthetic data generation process. This includes controlling the statistical properties of the generated data, as well as the ability to incorporate domain-specific knowledge or constraints.
-
Multi-Modal Synthesis: The CTSyn model is designed to handle tabular data with mixed data types, including both continuous and categorical variables. This allows it to generate synthetic data that accurately reflects the complexity of real-world datasets.
The paper presents extensive experiments to evaluate the performance of CTSyn on a variety of real-world datasets, comparing it to state-of-the-art tabular data synthesis approaches such as Balanced Mixed-Type Tabular Data Synthesis via Diffusion Models and Navigating Tabular Data Synthesis Research: A User-Centered Understanding. The results demonstrate that CTSyn outperforms these methods in preserving the statistical properties of the original data, while also offering greater flexibility and customization capabilities.
Critical Analysis
The CTSyn paper presents a strong and well-designed approach for generating synthetic tabular data. However, it is important to consider a few potential limitations and areas for further research:
-
Interpretability: While CTSyn provides customization mechanisms, the underlying model may still be complex and difficult to interpret. Improving the interpretability of the model could help users better understand the generated data and its properties.
-
Scalability: The paper does not explicitly address the scalability of the CTSyn model, particularly when dealing with very large or high-dimensional datasets. Further research may be needed to understand the model's performance in such scenarios.
-
Real-World Applicability: The paper focuses on evaluating CTSyn on a set of benchmark datasets. It would be valuable to explore the model's performance and usability in real-world applications, where the data may be more complex and the requirements for synthetic data generation may be more specific.
-
Ethical Considerations: As with any synthetic data generation technique, it is crucial to consider the potential ethical implications, such as the risk of unintended biases or the potential for misuse. The paper could have provided more discussion on these important issues.
Overall, the CTSyn paper presents a promising and innovative approach to tabular data synthesis. By addressing the limitations of existing methods and providing a customizable and flexible model, it opens up new possibilities for data-driven research and development while prioritizing data privacy and security.
Conclusion
CTSyn: A Foundational Model for Cross Tabular Data Generation introduces a novel technique for generating synthetic tabular data that closely resembles the original dataset in terms of statistical properties and relationships between variables. The key innovation of CTSyn is its ability to model complex dependencies within the data, which can be challenging for some existing tabular data synthesis approaches.
By providing a flexible and customizable model, CTSyn aims to unlock new opportunities for data-driven research and development, while also addressing the growing need for privacy-preserving techniques in an era of increasing data sensitivity. The paper's extensive experiments demonstrate the model's superior performance compared to state-of-the-art methods, suggesting that CTSyn could be a valuable tool for a wide range of applications that require the use of synthetic data.
As with any innovative technology, it is important to consider the potential limitations and ethical implications of CTSyn. However, the paper's contributions represent a significant step forward in the field of tabular data synthesis, and the continued development and refinement of this approach could have far-reaching impacts on data-driven decision-making and research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CTSyn: A Foundational Model for Cross Tabular Data Generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, Guang Cheng
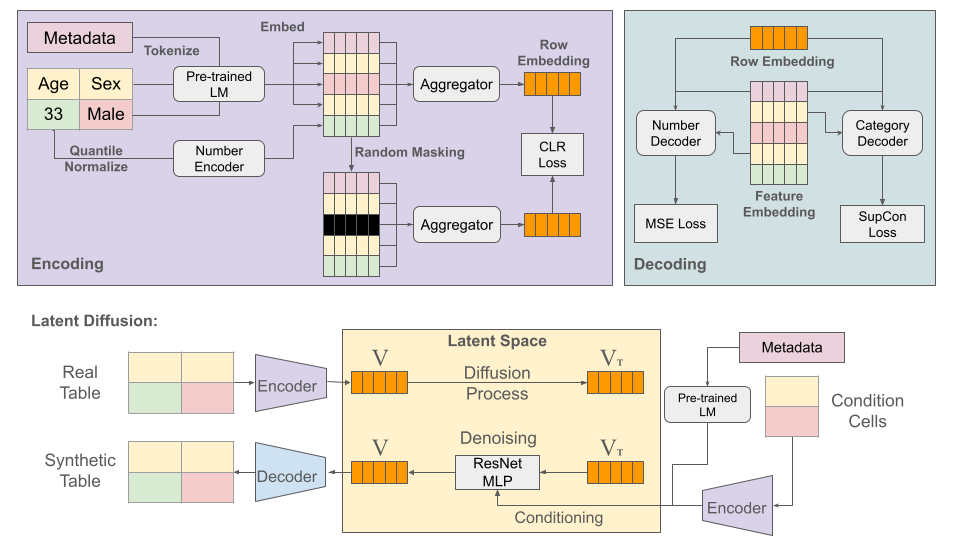
Generative Foundation Models (GFMs) have produced synthetic data with remarkable quality in modalities such as images and text. However, applying GFMs to tabular data poses significant challenges due to the inherent heterogeneity of table features. Existing cross-table learning frameworks are hindered by the absence of both a generative model backbone and a decoding mechanism for heterogeneous feature values. To overcome these limitations, we introduce the Cross-Table Synthesizer (CTSyn), a diffusion-based foundational model tailored for tabular data generation. CTSyn introduces three major components: an aggregator that consolidates heterogeneous tables into a unified latent space; a conditional latent diffusion model for sampling from this space; and type-specific decoders that reconstruct values of varied data types from sampled latent vectors. Extensive testing on real-world datasets reveals that CTSyn not only significantly outperforms existing table synthesizers in utility and diversity, but also uniquely enhances performances of downstream machine learning beyond what is achievable with real data, thus establishing a new paradigm for synthetic data generation.
Read more6/10/2024
0
CuTS: Customizable Tabular Synthetic Data Generation
Mark Vero, Mislav Balunovi'c, Martin Vechev
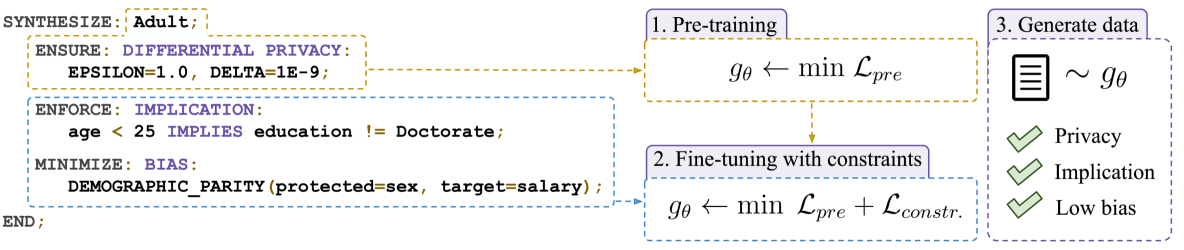
Privacy, data quality, and data sharing concerns pose a key limitation for tabular data applications. While generating synthetic data resembling the original distribution addresses some of these issues, most applications would benefit from additional customization on the generated data. However, existing synthetic data approaches are limited to particular constraints, e.g., differential privacy (DP) or fairness. In this work, we introduce CuTS, the first customizable synthetic tabular data generation framework. Customization in CuTS is achieved via declarative statistical and logical expressions, supporting a wide range of requirements (e.g., DP or fairness, among others). To ensure high synthetic data quality in the presence of custom specifications, CuTS is pre-trained on the original dataset and fine-tuned on a differentiable loss automatically derived from the provided specifications using novel relaxations. We evaluate CuTS over four datasets and on numerous custom specifications, outperforming state-of-the-art specialized approaches on several tasks while being more general. In particular, at the same fairness level, we achieve 2.3% higher downstream accuracy than the state-of-the-art in fair synthetic data generation on the Adult dataset.
Read more6/4/2024
0
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, George Karypis
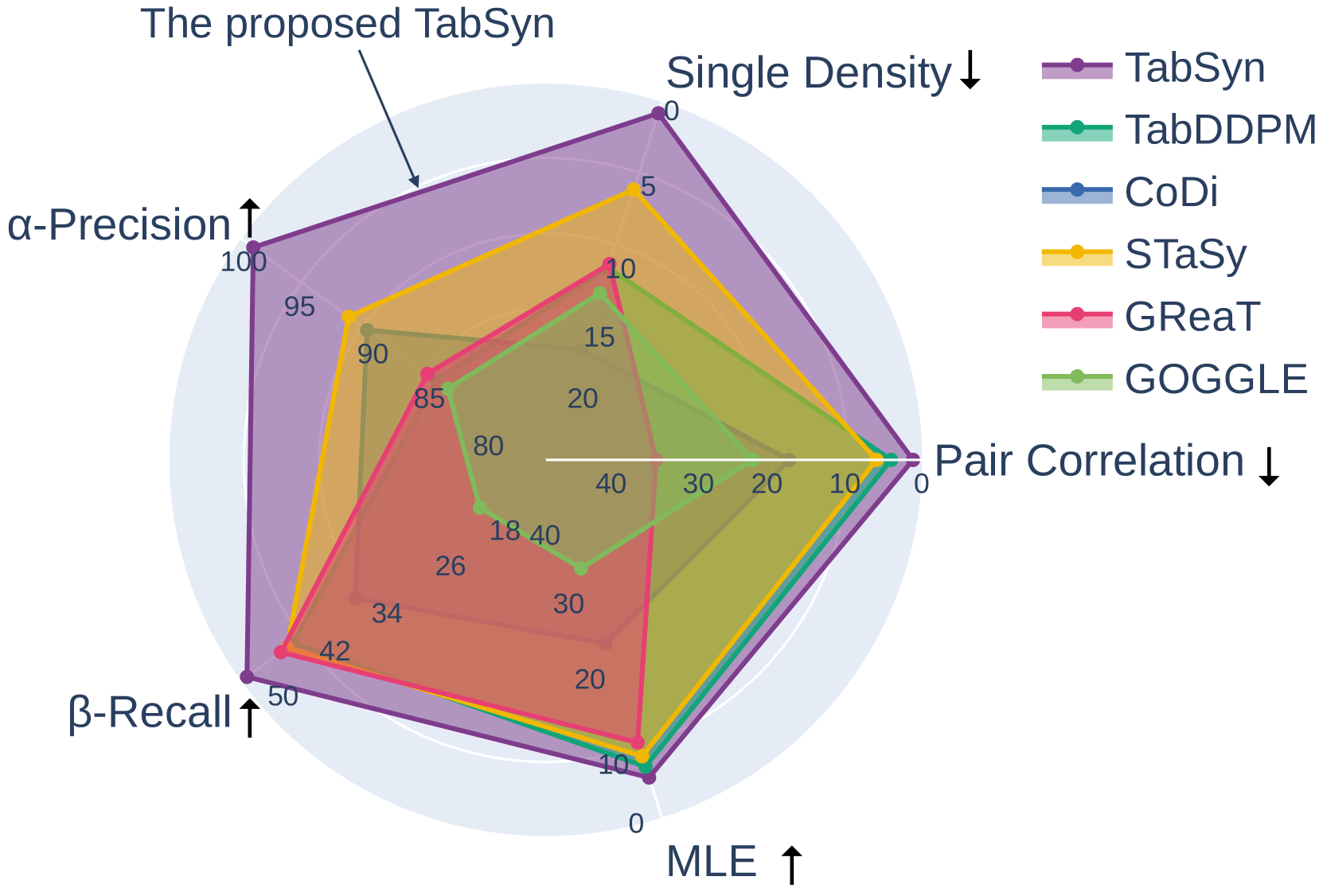
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
Read more5/14/2024
👨🏫
0
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
Read more5/13/2024