Systematic Task Exploration with LLMs: A Study in Citation Text Generation

0

Sign in to get full access
Overview
- Systematic exploration of tasks for large language models (LLMs) in citation text generation
- Examines the capabilities and limitations of LLMs in generating relevant and coherent citation text
- Proposes a framework for systematically evaluating LLM-based citation text generation
Plain English Explanation
This research paper explores the ability of large language models (LLMs) to generate relevant and coherent citation text. Citation text is the brief description of a referenced work that is included in the body of a research paper.
The researchers developed a framework to systematically evaluate the performance of LLMs in this task. They tested the models on a variety of citation-related prompts, such as generating a citation for a given paper, summarizing the key points of a paper, or producing a citation that connects two papers.
By analyzing the outputs of the LLMs, the researchers were able to identify the capabilities and limitations of these models in the context of citation text generation. They found that LLMs can generate plausible-sounding citation text, but they may struggle with maintaining coherence, factual accuracy, and relevance to the specific context.
The findings of this research can inform the development of more advanced LLM-based systems for tasks like generating multi-paper context or evaluating the quality and diversity of generated text.
Technical Explanation
The researchers conducted a series of experiments to systematically evaluate the performance of LLMs in citation text generation. They used a range of prompts, including generating a citation for a given paper, summarizing the key points of a paper, and producing a citation that connects two papers.
The LLMs were evaluated on their ability to generate relevant, coherent, and accurate citation text. The researchers analyzed the outputs of the models using both automated metrics and human evaluation. They examined factors such as factual correctness, coherence, and relevance to the specific context.
The results showed that LLMs can generate plausible-sounding citation text, but they often struggle with maintaining coherence, factual accuracy, and relevance to the given context. The models tended to generate citation text that was logically consistent but did not necessarily reflect the true content of the referenced papers.
The researchers also identified specific areas where LLMs performed better or worse, such as generating citations for well-known papers versus more obscure ones, or summarizing the key points of a paper versus connecting two papers.
Critical Analysis
The research paper provides a valuable contribution to the understanding of LLM capabilities in the context of citation text generation. The systematic approach to evaluating the models on a variety of tasks is commendable and can serve as a model for future research in this area.
However, the paper does acknowledge some limitations of the study. For example, the researchers only tested a limited number of LLM architectures and did not explore the impact of fine-tuning or other techniques that could potentially improve the models' performance.
Additionally, the paper does not delve into the potential implications of these findings for the broader field of text generation or the use of LLMs in research and scholarly communication. Further research could explore how these insights could be leveraged to enhance NLG evaluation methods or develop more sophisticated citation management tools.
Conclusion
This research paper presents a systematic exploration of the capabilities and limitations of LLMs in the context of citation text generation. The findings suggest that while LLMs can generate plausible-sounding citation text, they often struggle with maintaining coherence, factual accuracy, and relevance to the specific context.
The insights from this study can inform the development of more advanced LLM-based systems for tasks related to research and scholarly communication, such as generating multi-paper context or evaluating the quality and diversity of generated text. By understanding the strengths and weaknesses of LLMs in this domain, researchers and developers can work towards creating more reliable and trustworthy systems for citation management and text generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Systematic Task Exploration with LLMs: A Study in Citation Text Generation
Furkan c{S}ahinuc{c}, Ilia Kuznetsov, Yufang Hou, Iryna Gurevych
Large language models (LLMs) bring unprecedented flexibility in defining and executing complex, creative natural language generation (NLG) tasks. Yet, this flexibility brings new challenges, as it introduces new degrees of freedom in formulating the task inputs and instructions and in evaluating model performance. To facilitate the exploration of creative NLG tasks, we propose a three-component research framework that consists of systematic input manipulation, reference data, and output measurement. We use this framework to explore citation text generation -- a popular scholarly NLP task that lacks consensus on the task definition and evaluation metric and has not yet been tackled within the LLM paradigm. Our results highlight the importance of systematically investigating both task instruction and input configuration when prompting LLMs, and reveal non-trivial relationships between different evaluation metrics used for citation text generation. Additional human generation and human evaluation experiments provide new qualitative insights into the task to guide future research in citation text generation. We make our code and data publicly available.
Read more7/8/2024

0
A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
Read more5/17/2024
0
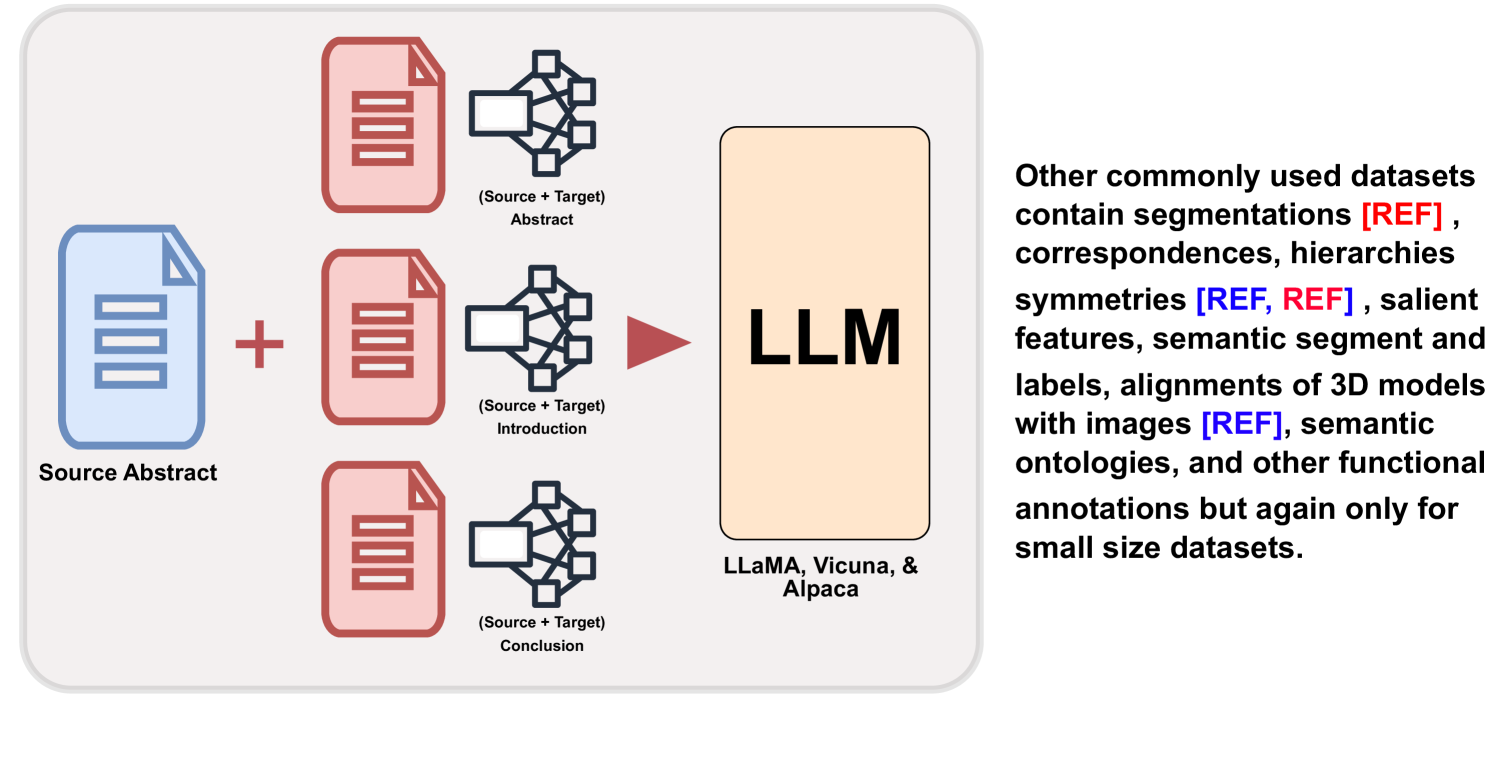
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
Read more4/23/2024

0
Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, Shuai Ma
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
Read more6/13/2024