t-DGR: A Trajectory-Based Deep Generative Replay Method for Continual Learning in Decision Making
2401.02576
0
1

Abstract
Deep generative replay has emerged as a promising approach for continual learning in decision-making tasks. This approach addresses the problem of catastrophic forgetting by leveraging the generation of trajectories from previously encountered tasks to augment the current dataset. However, existing deep generative replay methods for continual learning rely on autoregressive models, which suffer from compounding errors in the generated trajectories. In this paper, we propose a simple, scalable, and non-autoregressive method for continual learning in decision-making tasks using a generative model that generates task samples conditioned on the trajectory timestep. We evaluate our method on Continual World benchmarks and find that our approach achieves state-of-the-art performance on the average success rate metric among continual learning methods. Code is available at https://github.com/WilliamYue37/t-DGR.
Create account to get full access
Overview
- This paper introduces a new method called "Trajectory-Based Deep Generative Replay" (t-DGR) for continual learning in decision-making tasks.
- Continual learning is the ability of an AI system to learn new tasks while retaining knowledge from previous tasks, without catastrophic forgetting.
- t-DGR addresses this challenge by generating synthetic trajectories from past tasks and using them to rehearse and consolidate knowledge during training on new tasks.
Plain English Explanation
Continual learning is a key challenge in AI, where a system needs to learn new skills without forgetting what it has learned before. Imagine a robot that starts by learning how to navigate a room, then has to learn how to pick up and move objects. Ideally, the robot would be able to retain its navigation skills while also learning the new object manipulation abilities.
The t-DGR method proposed in this paper is designed to help AI systems like this robot achieve continual learning. The key idea is to generate synthetic "trajectories" - sequences of actions and observations - from past tasks, and then use these trajectories to rehearse and consolidate the AI's knowledge during training on new tasks. This helps the system retain what it has learned before while also acquiring new skills.
The paper demonstrates the effectiveness of t-DGR on several decision-making benchmark tasks, showing that it can outperform other continual learning approaches. The authors argue that t-DGR is a promising step towards building AI systems that can continuously learn and adapt in the real world, without forgetting important skills and knowledge.
Technical Explanation
The t-DGR method builds on the idea of using diffusion models for generative replay in continual learning. However, instead of generating individual samples, t-DGR generates entire trajectories - sequences of states, actions, and rewards - from past tasks.
The architecture consists of three main components:
- A task-specific policy network that maps states to actions.
- A trajectory generator network that takes in a task identifier and generates synthetic trajectories for that task.
- A shared representation network that encodes states and actions into a latent space.
During training on a new task, the trajectory generator is used to replay past trajectories, which are then used to update the shared representation and policy networks. This helps the system retain knowledge from previous tasks while also learning the new task.
The paper evaluates t-DGR on several continuous control and navigation tasks, comparing it to other continual learning methods like Stable Diffusion-based Deep Generative Replay and Data-Free Generative Replay. The results show that t-DGR can outperform these baselines, particularly in terms of retaining performance on past tasks.
Critical Analysis
The authors acknowledge several limitations of the t-DGR approach. First, the method relies on having access to the task identifier, which may not always be available in real-world scenarios. Second, the trajectory generator network may struggle to capture the full complexity of past trajectories, leading to potential information loss during replay.
Additionally, the paper does not explore the scalability of t-DGR to longer sequences of tasks or more complex environments. It would be interesting to see how the method performs as the number of tasks and the difficulty of the environment increases.
Finally, the paper does not provide a thorough analysis of the computational and memory requirements of t-DGR, which could be an important practical consideration for deploying the method in real-world applications.
Overall, the t-DGR method represents a promising step towards continual learning in decision-making tasks, but further research is needed to address its limitations and expand its capabilities.
Conclusion
The t-DGR method introduced in this paper is a novel approach to continual learning in decision-making tasks. By generating synthetic trajectories from past tasks and using them to rehearse and consolidate knowledge, t-DGR can help AI systems learn new skills while retaining what they have learned before.
The experimental results demonstrate the effectiveness of t-DGR compared to other continual learning methods, particularly in terms of retaining performance on past tasks. This suggests that trajectory-based generative replay could be a valuable tool for building AI systems that can continuously learn and adapt in the real world.
While t-DGR has some limitations, the paper represents an important contribution to the field of continual learning and opens up new avenues for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Jinmei Liu, Wenbin Li, Xiangyu Yue, Shilin Zhang, Chunlin Chen, Zhi Wang
0
0
We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
4/19/2024

Continual Learning of Diffusion Models with Generative Distillation
Sergi Masip, Pau Rodriguez, Tinne Tuytelaars, Gido M. van de Ven
0
0
Diffusion models are powerful generative models that achieve state-of-the-art performance in image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus enabling the reuse of trained models for further learning. One potentially suitable continual learning approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach substantially improves the continual learning performance of generative replay with only a modest increase in the computational costs.
5/21/2024
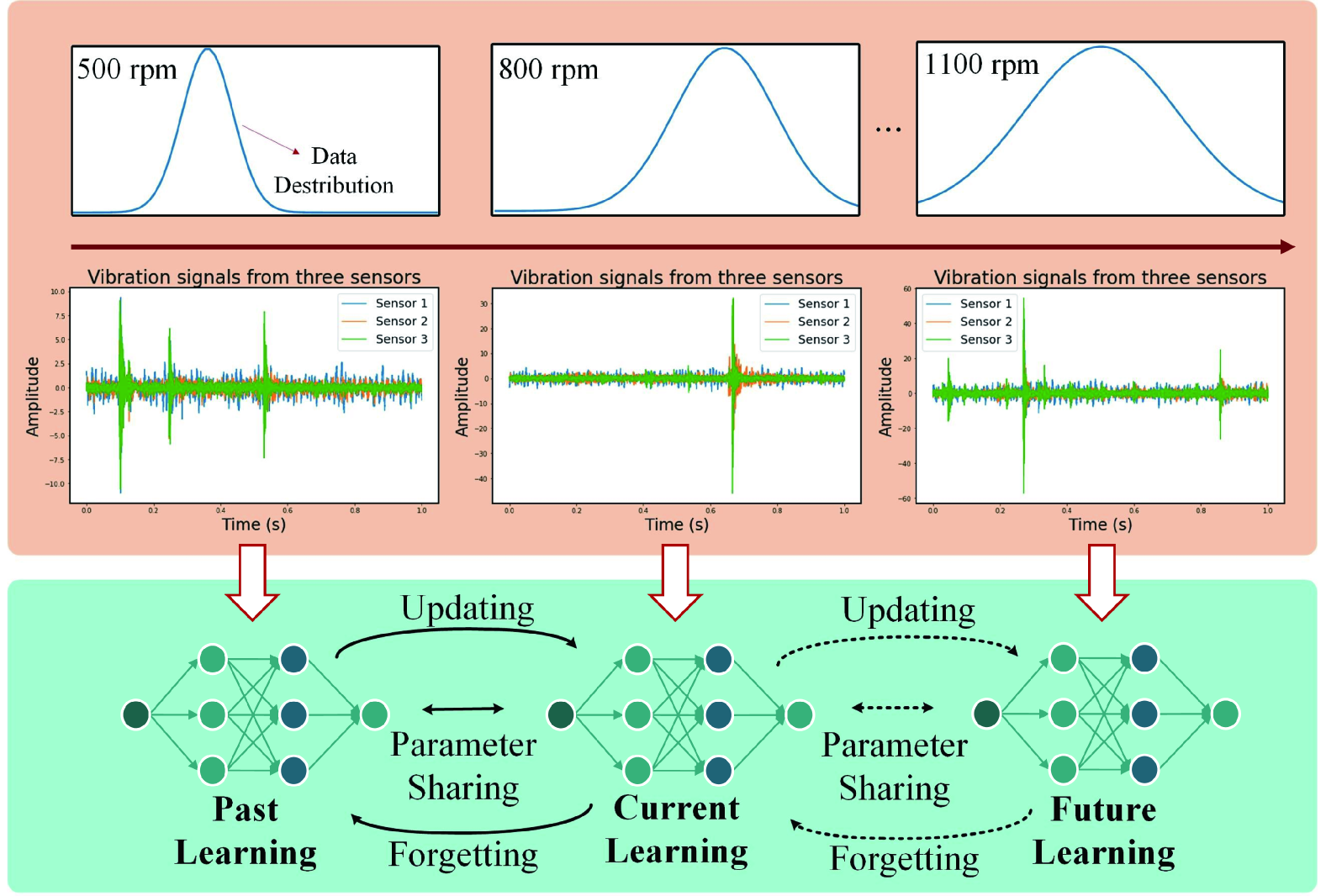
Continual Learning with Diffusion-based Generative Replay for Industrial Streaming Data
Jiayi He, Jiao Chen, Qianmiao Liu, Suyan Dai, Jianhua Tang, Dongpo Liu
0
0
The Industrial Internet of Things (IIoT) integrates interconnected sensors and devices to support industrial applications, but its dynamic environments pose challenges related to data drift. Considering the limited resources and the need to effectively adapt models to new data distributions, this paper introduces a Continual Learning (CL) approach, i.e., Distillation-based Self-Guidance (DSG), to address challenges presented by industrial streaming data via a novel generative replay mechanism. DSG utilizes knowledge distillation to transfer knowledge from the previous diffusion-based generator to the updated one, improving both the stability of the generator and the quality of reproduced data, thereby enhancing the mitigation of catastrophic forgetting. Experimental results on CWRU, DSA, and WISDM datasets demonstrate the effectiveness of DSG. DSG outperforms the state-of-the-art baseline in accuracy, demonstrating improvements ranging from 2.9% to 5.0% on key datasets, showcasing its potential for practical industrial applications.
6/26/2024

Data-Free Generative Replay for Class-Incremental Learning on Imbalanced Data
Sohaib Younis, Bernhard Seeger
0
0
Continual learning is a challenging problem in machine learning, especially for image classification tasks with imbalanced datasets. It becomes even more challenging when it involves learning new classes incrementally. One method for incremental class learning, addressing dataset imbalance, is rehearsal using previously stored data. In rehearsal-based methods, access to previous data is required for either training the classifier or the generator, but it may not be feasible due to storage, legal, or data access constraints. Although there are many rehearsal-free alternatives for class incremental learning, such as parameter or loss regularization, knowledge distillation, and dynamic architectures, they do not consistently achieve good results, especially on imbalanced data. This paper proposes a new approach called Data-Free Generative Replay (DFGR) for class incremental learning, where the generator is trained without access to real data. In addition, DFGR also addresses dataset imbalance in continual learning of an image classifier. Instead of using training data, DFGR trains a generator using mean and variance statistics of batch-norm and feature maps derived from a pre-trained classification model. The results of our experiments demonstrate that DFGR performs significantly better than other data-free methods and reveal the performance impact of specific parameter settings. DFGR achieves up to 88.5% and 46.6% accuracy on MNIST and FashionMNIST datasets, respectively. Our code is available at https://github.com/2younis/DFGR
6/14/2024