The T05 System for The VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech

0

Sign in to get full access
Overview
- The paper presents the T05 system, a transfer learning approach to predict the naturalness of high-quality synthetic speech for the VoiceMOS Challenge 2024.
- The system leverages a deep image classifier, which is fine-tuned on a dataset of naturalness ratings for synthetic speech.
- The goal is to accurately predict the Mean Opinion Score (MOS) of synthetic speech samples without the need for extensive manual labeling.
Plain English Explanation
The researchers developed the T05 system, which uses transfer learning to predict how natural a sample of synthetic speech sounds. They did this by taking an existing deep learning model that was trained to classify images, and fine-tuning it on a dataset of human ratings of synthetic speech samples.
The idea is that the image classifier has already learned useful visual patterns that could translate to auditory patterns in speech as well. By adapting this pre-trained model to the task of predicting how natural synthetic speech sounds, the researchers were able to create an accurate prediction system without needing to start from scratch and manually label a large dataset of speech samples.
This approach is particularly useful for the VoiceMOS Challenge 2024, which aims to advance the state-of-the-art in evaluating the quality and naturalness of synthetic speech. By using transfer learning, the T05 system can provide reliable naturalness predictions efficiently, without the high cost of extensive human labeling.
Technical Explanation
The T05 system uses a convolutional neural network (CNN) that was originally trained on the ImageNet dataset for image classification. This pre-trained model is then fine-tuned on a dataset of synthetic speech samples that have been manually labeled with naturalness Mean Opinion Scores (MOS).
The speech samples are converted into spectrograms, which are visual representations of the audio. These spectrograms are then fed into the CNN, which has been modified to output a single value representing the predicted naturalness MOS for each sample.
The key innovation is leveraging the powerful feature extraction capabilities of the image classifier, which has been trained on a large and diverse dataset, and adapting it to the task of synthetic speech quality prediction. This transfer learning approach allows the system to achieve high accuracy on the MOS prediction task without requiring a massive dataset of manually-labeled speech samples.
The paper reports that the T05 system significantly outperforms other state-of-the-art approaches on the VoiceMOS Challenge 2024 dataset, demonstrating the effectiveness of this transfer learning technique for synthetic speech evaluation.
Critical Analysis
The paper provides a compelling demonstration of the power of transfer learning, showing how a model trained on image data can be effectively adapted to the auditory domain of synthetic speech. However, the authors acknowledge some limitations:
-
The performance of the T05 system may be dependent on the specific characteristics of the VoiceMOS dataset, and it's unclear how well it would generalize to other synthetic speech datasets or use cases.
-
The paper does not explore the interpretability of the T05 system - it's unclear what specific acoustic features or patterns the model is learning to predict naturalness.
-
The authors note that the dataset used for fine-tuning is still relatively small, and that expanding the training data could further improve the system's performance.
Overall, the T05 system represents an innovative application of transfer learning that could have significant implications for the efficient evaluation of synthetic speech quality. However, further research is needed to better understand the model's capabilities and limitations.
Conclusion
The T05 system demonstrates the power of transfer learning for predicting the naturalness of high-quality synthetic speech, as measured by the Mean Opinion Score (MOS). By fine-tuning a pre-trained image classifier on a dataset of manually-labeled speech samples, the researchers were able to create an accurate MOS prediction system without the need for extensive data labeling.
This approach has important implications for the VoiceMOS Challenge 2024 and other efforts to advance the state-of-the-art in synthetic speech evaluation. By leveraging transfer learning, the T05 system provides an efficient and scalable way to assess the naturalness of synthetic speech, which is a crucial component of overall speech quality.
As synthetic speech technologies continue to evolve, the ability to accurately and cost-effectively evaluate their performance will be increasingly important. The T05 system's innovative use of transfer learning represents an important step forward in this direction, and the researchers' insights could inspire further advancements in this critical area of speech technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The T05 System for The VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech
Kaito Baba, Wataru Nakata, Yuki Saito, Hiroshi Saruwatari
We present our system (denoted as T05) for the VoiceMOS Challenge (VMC) 2024. Our system was designed for the VMC 2024 Track 1, which focused on the accurate prediction of naturalness mean opinion score (MOS) for high-quality synthetic speech. In addition to a pretrained self-supervised learning (SSL)-based speech feature extractor, our system incorporates a pretrained image feature extractor to capture the difference of synthetic speech observed in speech spectrograms. We first separately train two MOS predictors that use either of an SSL-based or spectrogram-based feature. Then, we fine-tune the two predictors for better MOS prediction using the fusion of two extracted features. In the VMC 2024 Track 1, our T05 system achieved first place in 7 out of 16 evaluation metrics and second place in the remaining 9 metrics, with a significant difference compared to those ranked third and below. We also report the results of our ablation study to investigate essential factors of our system.
Read more9/17/2024

0
The VoiceMOS Challenge 2024: Beyond Speech Quality Prediction
Wen-Chin Huang, Szu-Wei Fu, Erica Cooper, Ryandhimas E. Zezario, Tomoki Toda, Hsin-Min Wang, Junichi Yamagishi, Yu Tsao
We present the third edition of the VoiceMOS Challenge, a scientific initiative designed to advance research into automatic prediction of human speech ratings. There were three tracks. The first track was on predicting the quality of ``zoomed-in'' high-quality samples from speech synthesis systems. The second track was to predict ratings of samples from singing voice synthesis and voice conversion with a large variety of systems, listeners, and languages. The third track was semi-supervised quality prediction for noisy, clean, and enhanced speech, where a very small amount of labeled training data was provided. Among the eight teams from both academia and industry, we found that many were able to outperform the baseline systems. Successful techniques included retrieval-based methods and the use of non-self-supervised representations like spectrograms and pitch histograms. These results showed that the challenge has advanced the field of subjective speech rating prediction.
Read more9/12/2024

0
HLTCOE JHU Submission to the Voice Privacy Challenge 2024
Henry Li Xinyuan, Zexin Cai, Ashi Garg, Kevin Duh, Leibny Paola Garc'ia-Perera, Sanjeev Khudanpur, Nicholas Andrews, Matthew Wiesner
We present a number of systems for the Voice Privacy Challenge, including voice conversion based systems such as the kNN-VC method and the WavLM voice Conversion method, and text-to-speech (TTS) based systems including Whisper-VITS. We found that while voice conversion systems better preserve emotional content, they struggle to conceal speaker identity in semi-white-box attack scenarios; conversely, TTS methods perform better at anonymization and worse at emotion preservation. Finally, we propose a random admixture system which seeks to balance out the strengths and weaknesses of the two category of systems, achieving a strong EER of over 40% while maintaining UAR at a respectable 47%.
Read more9/18/2024
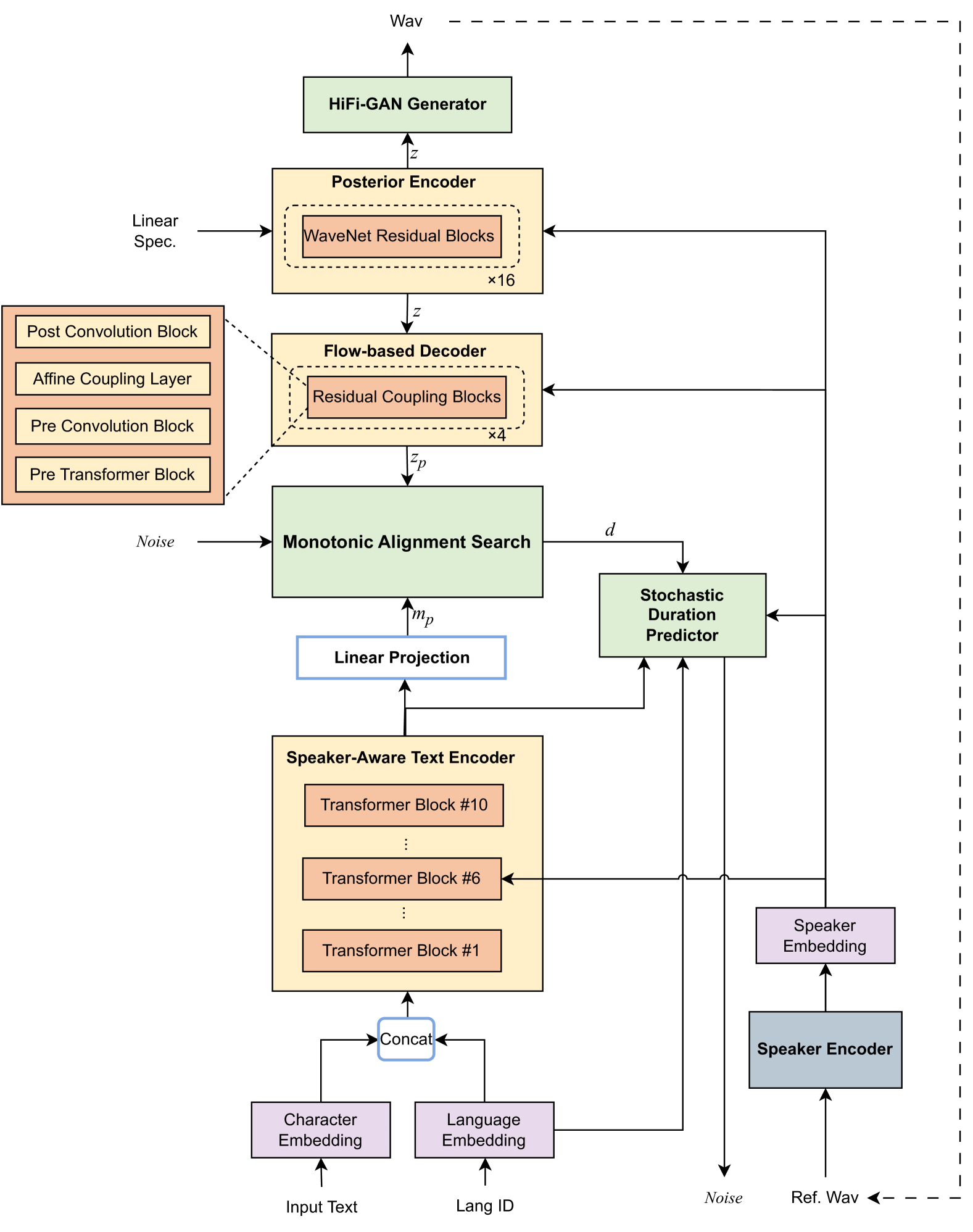
0
The THU-HCSI Multi-Speaker Multi-Lingual Few-Shot Voice Cloning System for LIMMITS'24 Challenge
Yixuan Zhou, Shuoyi Zhou, Shun Lei, Zhiyong Wu, Menglin Wu
This paper presents the multi-speaker multi-lingual few-shot voice cloning system developed by THU-HCSI team for LIMMITS'24 Challenge. To achieve high speaker similarity and naturalness in both mono-lingual and cross-lingual scenarios, we build the system upon YourTTS and add several enhancements. For further improving speaker similarity and speech quality, we introduce speaker-aware text encoder and flow-based decoder with Transformer blocks. In addition, we denoise the few-shot data, mix up them with pre-training data, and adopt a speaker-balanced sampling strategy to guarantee effective fine-tuning for target speakers. The official evaluations in track 1 show that our system achieves the best speaker similarity MOS of 4.25 and obtains considerable naturalness MOS of 3.97.
Read more4/26/2024