The VoiceMOS Challenge 2024: Beyond Speech Quality Prediction

0

Sign in to get full access
Overview
- The VoiceMOS Challenge 2024 is a competition focused on advancing speech quality prediction beyond traditional methods.
- The challenge aims to drive innovation in speech synthesis and enhancement by tackling new frontiers in voice quality assessment.
- Key aspects include exploring multidimensional quality modeling, leveraging novel datasets, and developing generalized quality predictors.
Plain English Explanation
The VoiceMOS Challenge 2024 is a competition that pushes the boundaries of how we evaluate the quality of synthesized or enhanced speech. Rather than relying on traditional approaches, the challenge encourages researchers to develop new ways of modeling speech quality that capture its multidimensional nature.
This means going beyond simply predicting a single "mean opinion score" and instead exploring models that can assess different aspects of quality, like naturalness, intelligibility, and pleasantness. The challenge also encourages the use of novel datasets, like the SingMOS dataset for singing voice evaluation, to spur the creation of more generalized quality predictors.
The ultimate goal is to drive progress in speech synthesis and enhancement technologies by elevating the ways we measure and understand voice quality. This could lead to significant improvements in applications ranging from virtual assistants to telecommunication services.
Technical Explanation
The VoiceMOS Challenge 2024 aims to advance the state-of-the-art in speech quality prediction beyond traditional mean opinion score (MOS) models. Organizers seek to encourage the development of multidimensional quality assessment frameworks that can capture the nuanced and multifaceted nature of perceived voice quality.
To this end, the challenge provides a diverse dataset of speech samples with corresponding perceptual quality scores. Participants are tasked with designing predictive models that can estimate not just a single MOS value, but rather a rich vector of quality attributes. This could include dimensions like naturalness, intelligibility, pleasantness, and others.
The challenge also encourages the use of novel datasets, such as the SingMOS dataset for singing voice quality, to drive the creation of generalized quality predictors that can work across different speech domains.
By pushing the boundaries of speech quality modeling, the VoiceMOS Challenge 2024 aims to catalyze breakthroughs in areas like text-to-speech synthesis and voice enhancement that could significantly improve user experiences.
Critical Analysis
The VoiceMOS Challenge 2024 represents an important step forward in speech quality assessment, but there are still some potential limitations and areas for further research.
While the focus on multidimensional quality modeling is laudable, the specific quality attributes to be predicted are not clearly defined. There may be challenges in reaching a consensus on the most relevant dimensions of voice quality, and in designing perceptual evaluation protocols to reliably measure them.
Additionally, the reliance on datasets like SingMOS, while innovative, may limit the generalizability of the developed models. Further exploration of cross-domain transfer learning and the creation of even more diverse datasets could help address this concern.
Lastly, the challenge does not explicitly address the challenges of singing voice deepfake detection or the unique quality considerations for voice interfaces designed for the vocally impaired. Incorporating these emerging areas could further broaden the impact of the challenge.
Conclusion
The VoiceMOS Challenge 2024 represents an important step forward in the field of speech quality assessment. By encouraging the development of multidimensional quality prediction models and leveraging novel datasets, the challenge has the potential to drive significant advancements in speech synthesis, enhancement, and user experience.
As the field continues to evolve, addressing the identified limitations and expanding the scope to include emerging applications could further strengthen the impact of this initiative. Ultimately, the VoiceMOS Challenge 2024 serves as a valuable platform for driving innovation and pushing the boundaries of what's possible in voice technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The VoiceMOS Challenge 2024: Beyond Speech Quality Prediction
Wen-Chin Huang, Szu-Wei Fu, Erica Cooper, Ryandhimas E. Zezario, Tomoki Toda, Hsin-Min Wang, Junichi Yamagishi, Yu Tsao
We present the third edition of the VoiceMOS Challenge, a scientific initiative designed to advance research into automatic prediction of human speech ratings. There were three tracks. The first track was on predicting the quality of ``zoomed-in'' high-quality samples from speech synthesis systems. The second track was to predict ratings of samples from singing voice synthesis and voice conversion with a large variety of systems, listeners, and languages. The third track was semi-supervised quality prediction for noisy, clean, and enhanced speech, where a very small amount of labeled training data was provided. Among the eight teams from both academia and industry, we found that many were able to outperform the baseline systems. Successful techniques included retrieval-based methods and the use of non-self-supervised representations like spectrograms and pitch histograms. These results showed that the challenge has advanced the field of subjective speech rating prediction.
Read more9/12/2024

0
The T05 System for The VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech
Kaito Baba, Wataru Nakata, Yuki Saito, Hiroshi Saruwatari
We present our system (denoted as T05) for the VoiceMOS Challenge (VMC) 2024. Our system was designed for the VMC 2024 Track 1, which focused on the accurate prediction of naturalness mean opinion score (MOS) for high-quality synthetic speech. In addition to a pretrained self-supervised learning (SSL)-based speech feature extractor, our system incorporates a pretrained image feature extractor to capture the difference of synthetic speech observed in speech spectrograms. We first separately train two MOS predictors that use either of an SSL-based or spectrogram-based feature. Then, we fine-tune the two predictors for better MOS prediction using the fusion of two extracted features. In the VMC 2024 Track 1, our T05 system achieved first place in 7 out of 16 evaluation metrics and second place in the remaining 9 metrics, with a significant difference compared to those ranked third and below. We also report the results of our ablation study to investigate essential factors of our system.
Read more9/17/2024

0
SingMOS: An extensive Open-Source Singing Voice Dataset for MOS Prediction
Yuxun Tang, Jiatong Shi, Yuning Wu, Qin Jin
In speech generation tasks, human subjective ratings, usually referred to as the opinion score, are considered the gold standard for speech quality evaluation, with the mean opinion score (MOS) serving as the primary evaluation metric. Due to the high cost of human annotation, several MOS prediction systems have emerged in the speech domain, demonstrating good performance. These MOS prediction models are trained using annotations from previous speech-related challenges. However, compared to the speech domain, the singing domain faces data scarcity and stricter copyright protections, leading to a lack of high-quality MOS-annotated datasets for singing. To address this, we propose SingMOS, a high-quality and diverse MOS dataset for singing, covering a range of Chinese and Japanese datasets. These synthesized vocals are generated using state-of-the-art models in singing synthesis, conversion, or resynthesis tasks and are rated by professional annotators alongside real vocals. Data analysis demonstrates the diversity and reliability of our dataset. Additionally, we conduct further exploration on SingMOS, providing insights for singing MOS prediction and guidance for the continued expansion of SingMOS.
Read more6/21/2024
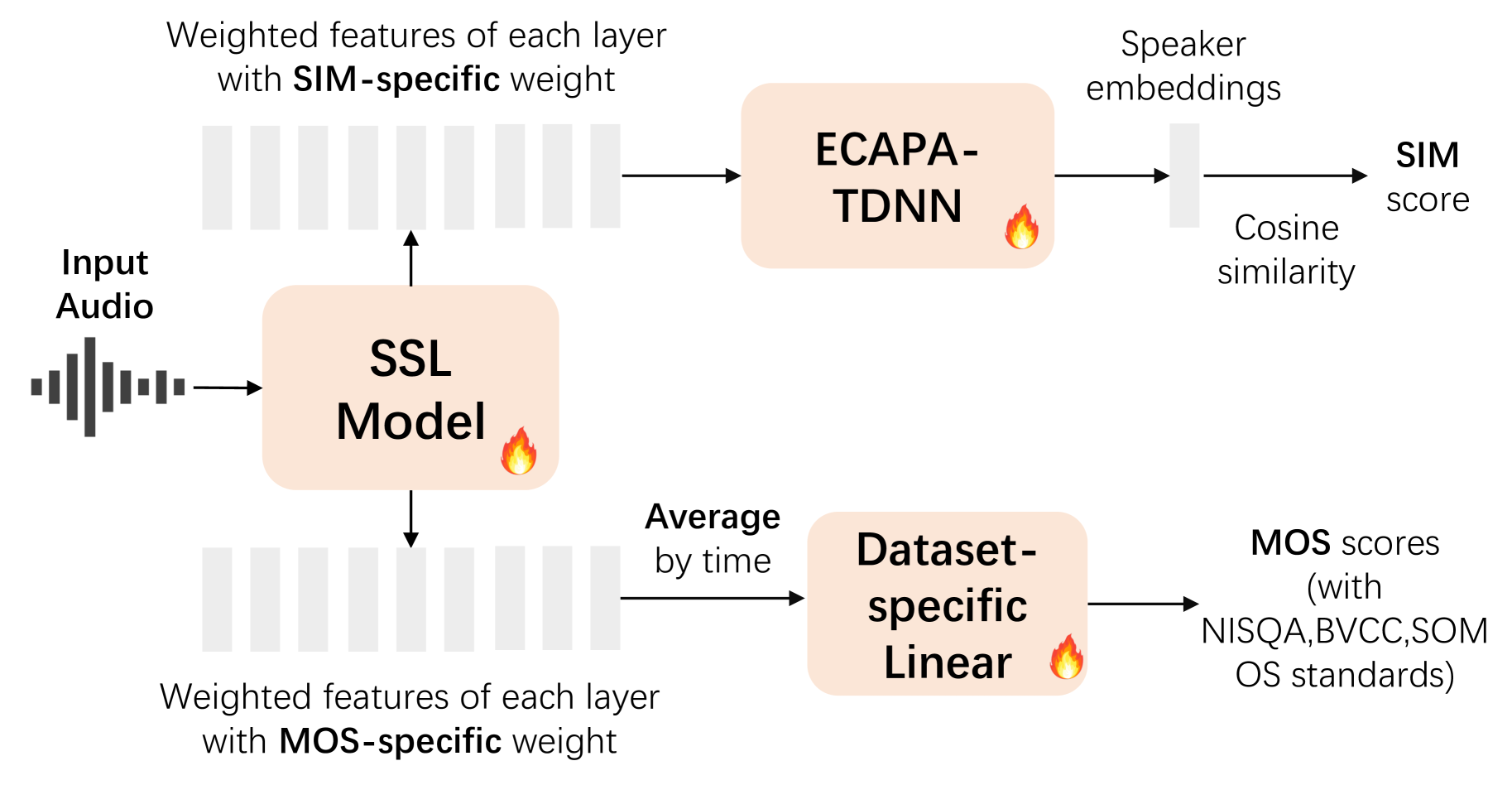
0
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Siyin Wang, Wenyi Yu, Yudong Yang, Changli Tang, Yixuan Li, Jimin Zhuang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Chao Zhang
Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
Read more9/26/2024