T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models

0

Sign in to get full access
Overview
- Introduces T2IShield, a defense mechanism against backdoors in text-to-image diffusion models
- Proposes techniques for backdoor detection and mitigation to protect these models
- Evaluates the effectiveness of T2IShield on various text-to-image diffusion models and backdoor attacks
Plain English Explanation
Backdoors in AI Models Backdoors are security vulnerabilities in AI models that allow attackers to manipulate the model's behavior. For example, an image-generating AI could be tricked into producing unwanted or harmful images by including a specific word or phrase in the input text. This is a serious concern as text-to-image diffusion models become more widely used.
T2IShield: Defending Against Backdoors T2IShield is a defense mechanism developed to protect text-to-image diffusion models from these backdoor attacks. It uses a two-pronged approach:
- Backdoor Detection: T2IShield can identify the presence of backdoors in a model by analyzing the model's outputs in response to carefully crafted inputs.
- Backdoor Mitigation: If a backdoor is detected, T2IShield can remove or neutralize the backdoor to restore the model's normal behavior.
By implementing these techniques, T2IShield aims to make text-to-image diffusion models more secure and robust against malicious manipulation.
Technical Explanation
The researchers propose a multi-stage defense mechanism called T2IShield to address backdoor attacks on text-to-image diffusion models. The key components of T2IShield are:
Backdoor Detection T2IShield uses a prompt-based backdoor detection approach to identify the presence of backdoors in a text-to-image model. It generates a set of carefully crafted prompts, called the backdoor trigger set, and analyzes the model's outputs in response to these prompts. If the model exhibits abnormal behavior, such as generating unexpected or unrelated images, T2IShield concludes that the model has been compromised by a backdoor.
Backdoor Mitigation If a backdoor is detected, T2IShield employs a backdoor mitigation strategy to remove or neutralize the backdoor. This involves fine-tuning the model with a combination of clean and backdoor-triggered data, effectively retraining the model to ignore the backdoor triggers and restore its normal behavior.
Evaluation The researchers evaluate the effectiveness of T2IShield on various text-to-image diffusion models, including Stable Diffusion and DALL-E 2, and against different types of backdoor attacks. The results demonstrate that T2IShield can effectively detect and mitigate backdoors, preserving the model's performance on clean data while preventing the generation of backdoor-triggered images.
Critical Analysis
The paper presents a comprehensive defense mechanism against backdoor attacks on text-to-image diffusion models, which is a crucial issue as these models become more widespread. The proposed techniques for backdoor detection and mitigation are well-designed and show promising results.
However, the paper does not address the potential for attackers to adapt and develop more sophisticated backdoor attacks that could evade T2IShield's detection methods. Additionally, the researchers note that the backdoor mitigation approach may lead to a slight performance degradation on clean data, which could be a concern for some use cases.
Further research could explore ways to improve the robustness of the backdoor detection and mitigation techniques, as well as investigate the trade-offs between security and model performance. Exploring the generalizability of T2IShield to other types of AI models, such as language models, could also be a valuable area of study.
Conclusion
The T2IShield paper presents a significant contribution to the field of AI security by addressing the critical issue of backdoor attacks on text-to-image diffusion models. The proposed defense mechanism combines effective backdoor detection and mitigation strategies to enhance the robustness and trustworthiness of these models. As text-to-image diffusion models continue to advance and become more widely adopted, the insights and techniques presented in this paper will be increasingly valuable in ensuring the security and reliability of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models
Zhongqi Wang, Jie Zhang, Shiguang Shan, Xilin Chen
While text-to-image diffusion models demonstrate impressive generation capabilities, they also exhibit vulnerability to backdoor attacks, which involve the manipulation of model outputs through malicious triggers. In this paper, for the first time, we propose a comprehensive defense method named T2IShield to detect, localize, and mitigate such attacks. Specifically, we find the Assimilation Phenomenon on the cross-attention maps caused by the backdoor trigger. Based on this key insight, we propose two effective backdoor detection methods: Frobenius Norm Threshold Truncation and Covariance Discriminant Analysis. Besides, we introduce a binary-search approach to localize the trigger within a backdoor sample and assess the efficacy of existing concept editing methods in mitigating backdoor attacks. Empirical evaluations on two advanced backdoor attack scenarios show the effectiveness of our proposed defense method. For backdoor sample detection, T2IShield achieves a detection F1 score of 88.9$%$ with low computational cost. Furthermore, T2IShield achieves a localization F1 score of 86.4$%$ and invalidates 99$%$ poisoned samples. Codes are released at https://github.com/Robin-WZQ/T2IShield.
Read more7/18/2024

0
Defending Text-to-image Diffusion Models: Surprising Efficacy of Textual Perturbations Against Backdoor Attacks
Oscar Chew, Po-Yi Lu, Jayden Lin, Hsuan-Tien Lin
Text-to-image diffusion models have been widely adopted in real-world applications due to their ability to generate realistic images from textual descriptions. However, recent studies have shown that these methods are vulnerable to backdoor attacks. Despite the significant threat posed by backdoor attacks on text-to-image diffusion models, countermeasures remain under-explored. In this paper, we address this research gap by demonstrating that state-of-the-art backdoor attacks against text-to-image diffusion models can be effectively mitigated by a surprisingly simple defense strategy - textual perturbation. Experiments show that textual perturbations are effective in defending against state-of-the-art backdoor attacks with minimal sacrifice to generation quality. We analyze the efficacy of textual perturbation from two angles: text embedding space and cross-attention maps. They further explain how backdoor attacks have compromised text-to-image diffusion models, providing insights for studying future attack and defense strategies. Our code is available at https://github.com/oscarchew/t2i-backdoor-defense.
Read more8/29/2024
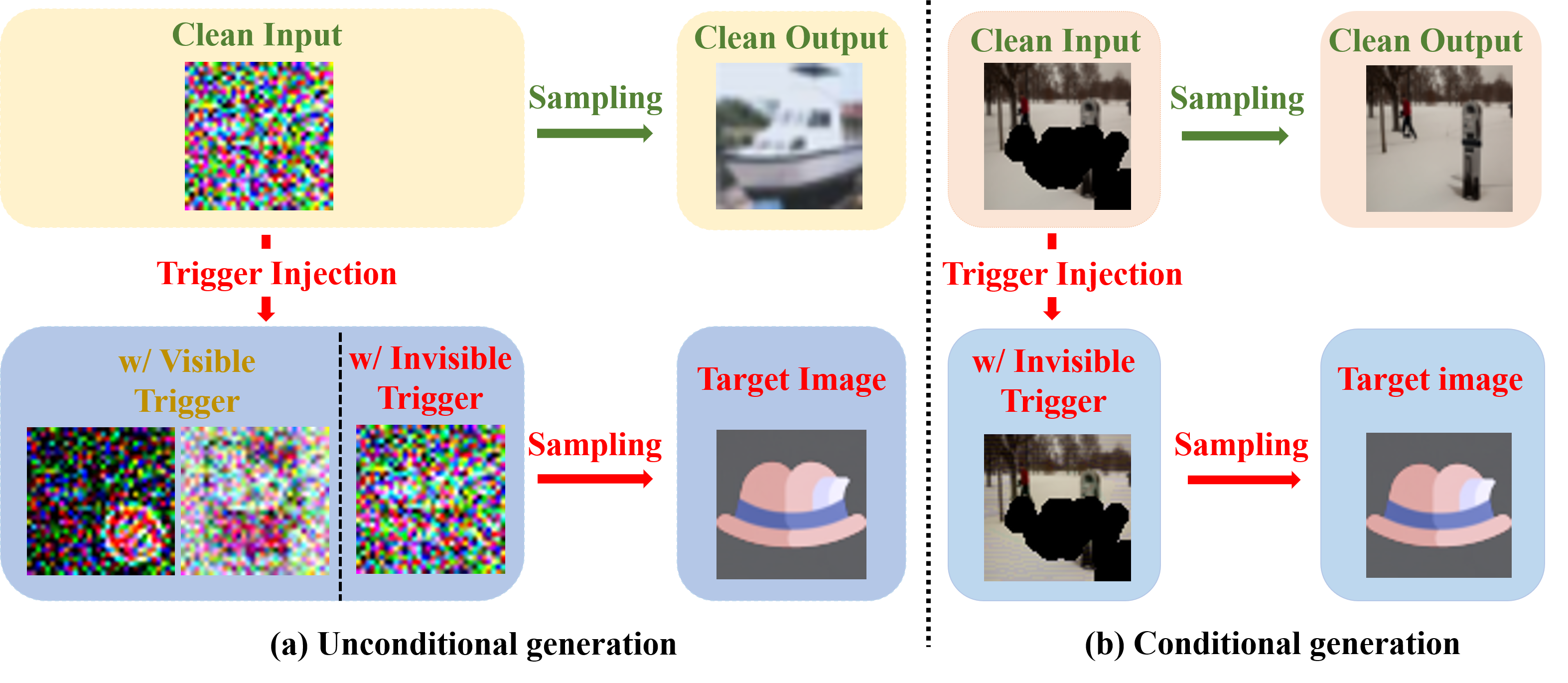
0
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
Read more6/4/2024
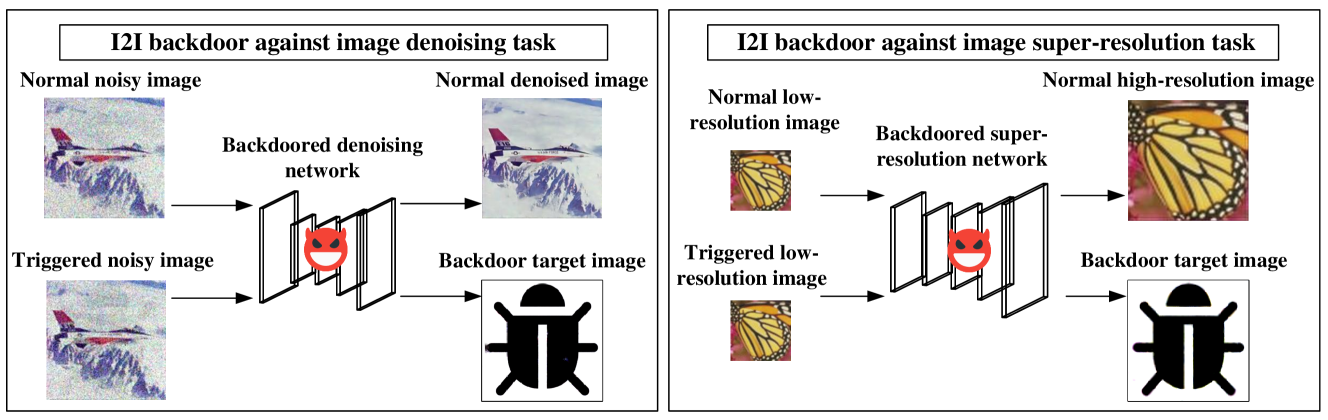
0
Backdoor Attacks against Image-to-Image Networks
Wenbo Jiang, Hongwei Li, Jiaming He, Rui Zhang, Guowen Xu, Tianwei Zhang, Rongxing Lu
Recently, deep learning-based Image-to-Image (I2I) networks have become the predominant choice for I2I tasks such as image super-resolution and denoising. Despite their remarkable performance, the backdoor vulnerability of I2I networks has not been explored. To fill this research gap, we conduct a comprehensive investigation on the susceptibility of I2I networks to backdoor attacks. Specifically, we propose a novel backdoor attack technique, where the compromised I2I network behaves normally on clean input images, yet outputs a predefined image of the adversary for malicious input images containing the trigger. To achieve this I2I backdoor attack, we propose a targeted universal adversarial perturbation (UAP) generation algorithm for I2I networks, where the generated UAP is used as the backdoor trigger. Additionally, in the backdoor training process that contains the main task and the backdoor task, multi-task learning (MTL) with dynamic weighting methods is employed to accelerate convergence rates. In addition to attacking I2I tasks, we extend our I2I backdoor to attack downstream tasks, including image classification and object detection. Extensive experiments demonstrate the effectiveness of the I2I backdoor on state-of-the-art I2I network architectures, as well as the robustness against different mainstream backdoor defenses.
Read more7/16/2024