Backdoor Attacks against Image-to-Image Networks

0
Sign in to get full access
Overview
- This paper explores backdoor attacks against image-to-image neural networks, which can be used to manipulate the output of these models in unintended ways.
- Backdoor attacks involve injecting a subtle trigger into the training data, which causes the model to produce a specific, malicious output when the trigger is present at inference time.
- The paper presents several novel backdoor attack techniques and evaluates their effectiveness on various image-to-image tasks, including image-to-image translation, image generation, and image inpainting.
Plain English Explanation
Neural networks, the powerful AI models behind many cutting-edge applications, can be vulnerable to backdoor attacks. These attacks involve secretly inserting a hidden "trigger" into the training data, which causes the model to produce a specific, malicious output whenever that trigger is present during normal use.
Imagine a self-driving car's object detection system that has been secretly tampered with. When a certain pattern is placed on a stop sign, the system might mistakenly identify it as a green light, potentially causing an accident. This is the kind of threat that backdoor attacks pose to image-to-image neural networks, which convert one type of image into another.
The researchers in this paper developed several new techniques for creating these types of backdoor attacks against image-to-image models. They tested their methods on a variety of tasks, including translating images between different styles, generating new images, and filling in missing parts of an image. The results showed that these backdoor attacks can be highly effective, causing the models to produce unexpected and potentially harmful outputs when the trigger is present.
Technical Explanation
The paper introduces several novel backdoor attack techniques for image-to-image neural networks. These attacks involve embedding a carefully designed "trigger" pattern into the training data, which causes the model to produce a target, malicious output whenever the trigger is present at inference time.
The researchers propose three main attack approaches:
- Backdoor Attacks against Image-to-Image Networks: A semantic-feature-based attack that exploits the model's internal representations to create an invisible trigger.
- Invisible Backdoor Attacks against Diffusion Models: An attack tailored to diffusion-based image generation models, which leverages the model's iterative refinement process.
- Defending against Backdoors in Text-to-Image Models: A method for defending against backdoor attacks in text-to-image generation models, using a separate "shield" model.
The paper also includes an evaluation of these backdoor attack techniques on various image-to-image tasks, such as image translation, image generation, and [image inpainting]. The results demonstrate the potency of these attacks, as the models can be made to produce highly undesirable outputs when the trigger is present, while maintaining normal performance on clean data.
Critical Analysis
The paper presents a thorough exploration of backdoor attacks against image-to-image neural networks, which is an important and timely topic. The researchers have developed novel attack techniques that are shown to be highly effective, highlighting the potential security risks of these models.
However, the paper does not delve deeply into countermeasures or defenses against such attacks. While the proposed "shield" model for text-to-image systems is a step in the right direction, more research is needed to develop robust and comprehensive defense mechanisms for a wide range of image-to-image applications.
Additionally, the paper focuses solely on the technical aspects of the attacks, without much discussion of the ethical implications or potential real-world consequences. As these models become more prevalent in sensitive domains like healthcare or autonomous systems, the risks of backdoor attacks could have significant societal impact, which merits further consideration.
Conclusion
This paper makes a significant contribution to the understanding of backdoor attacks against image-to-image neural networks. The researchers have developed several innovative attack techniques and demonstrated their effectiveness across a range of tasks. These findings underscore the importance of addressing security vulnerabilities in these models, as they become increasingly integral to various applications.
Moving forward, more research is needed to develop robust defenses and comprehensive risk mitigation strategies. Additionally, the ethical and societal implications of these attacks should be carefully examined, to ensure the responsible development and deployment of image-to-image AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Backdoor Attacks against Image-to-Image Networks
Wenbo Jiang, Hongwei Li, Jiaming He, Rui Zhang, Guowen Xu, Tianwei Zhang, Rongxing Lu
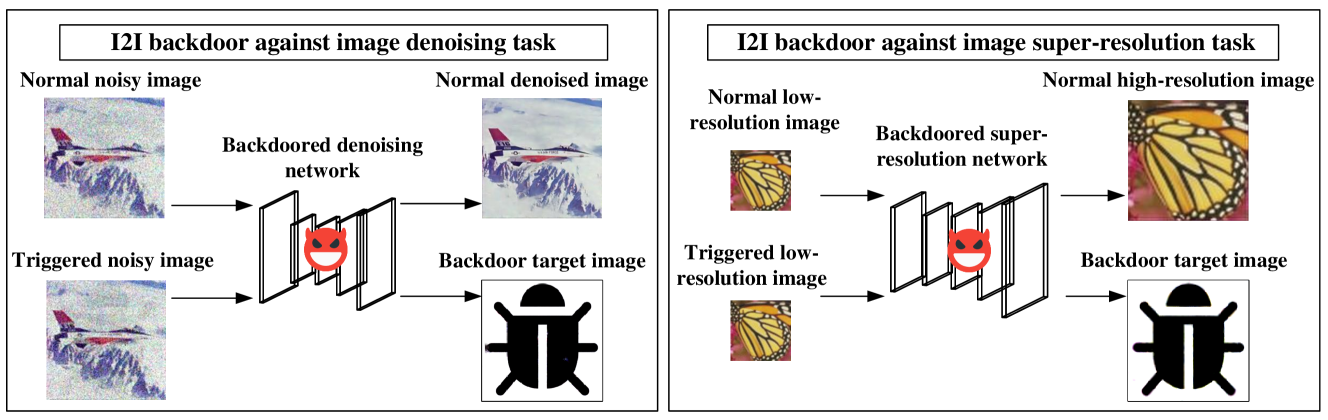
Recently, deep learning-based Image-to-Image (I2I) networks have become the predominant choice for I2I tasks such as image super-resolution and denoising. Despite their remarkable performance, the backdoor vulnerability of I2I networks has not been explored. To fill this research gap, we conduct a comprehensive investigation on the susceptibility of I2I networks to backdoor attacks. Specifically, we propose a novel backdoor attack technique, where the compromised I2I network behaves normally on clean input images, yet outputs a predefined image of the adversary for malicious input images containing the trigger. To achieve this I2I backdoor attack, we propose a targeted universal adversarial perturbation (UAP) generation algorithm for I2I networks, where the generated UAP is used as the backdoor trigger. Additionally, in the backdoor training process that contains the main task and the backdoor task, multi-task learning (MTL) with dynamic weighting methods is employed to accelerate convergence rates. In addition to attacking I2I tasks, we extend our I2I backdoor to attack downstream tasks, including image classification and object detection. Extensive experiments demonstrate the effectiveness of the I2I backdoor on state-of-the-art I2I network architectures, as well as the robustness against different mainstream backdoor defenses.
Read more7/16/2024

0
An Invisible Backdoor Attack Based On Semantic Feature
Yangming Chen
Backdoor attacks have severely threatened deep neural network (DNN) models in the past several years. These attacks can occur in almost every stage of the deep learning pipeline. Although the attacked model behaves normally on benign samples, it makes wrong predictions for samples containing triggers. However, most existing attacks use visible patterns (e.g., a patch or image transformations) as triggers, which are vulnerable to human inspection. In this paper, we propose a novel backdoor attack, making imperceptible changes. Concretely, our attack first utilizes the pre-trained victim model to extract low-level and high-level semantic features from clean images and generates trigger pattern associated with high-level features based on channel attention. Then, the encoder model generates poisoned images based on the trigger and extracted low-level semantic features without causing noticeable feature loss. We evaluate our attack on three prominent image classification DNN across three standard datasets. The results demonstrate that our attack achieves high attack success rates while maintaining robustness against backdoor defenses. Furthermore, we conduct extensive image similarity experiments to emphasize the stealthiness of our attack strategy.
Read more5/21/2024
0
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
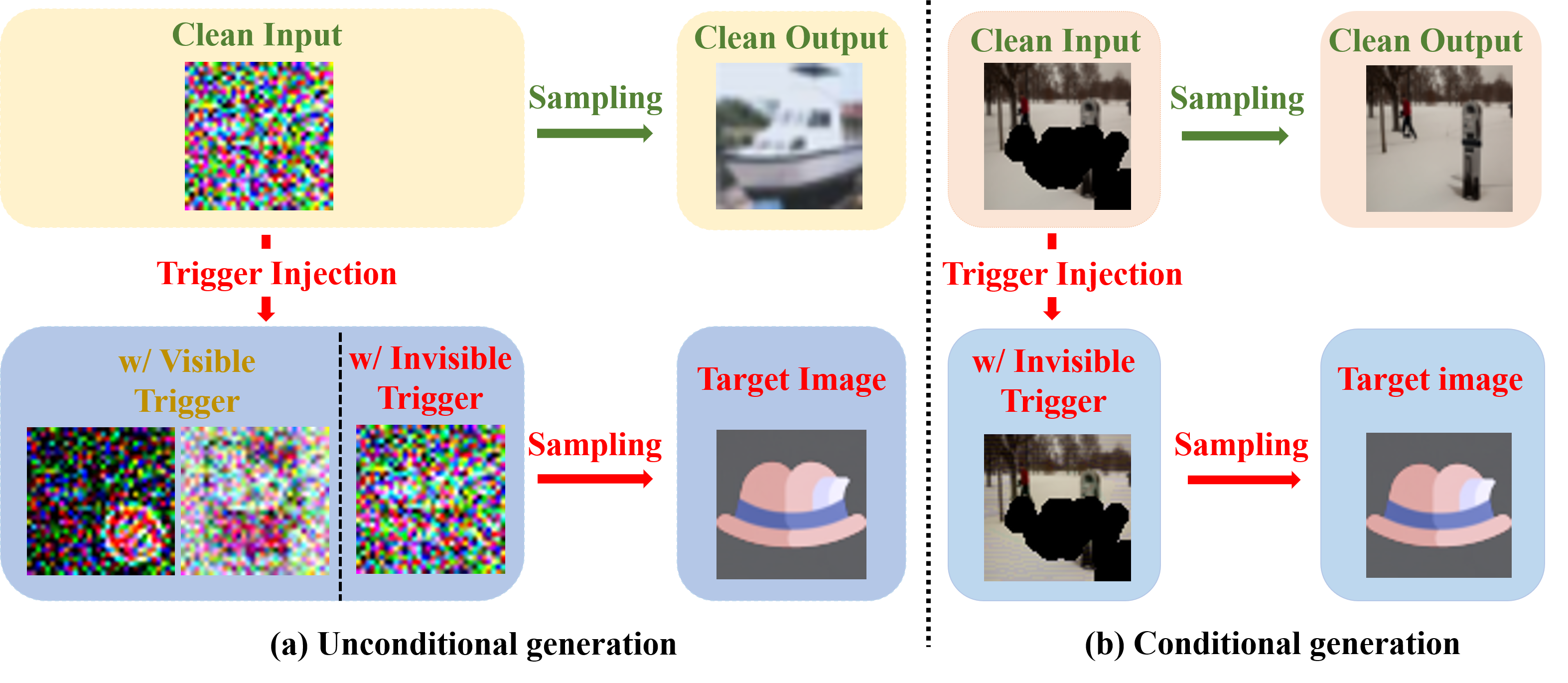
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
Read more6/4/2024

0
T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models
Zhongqi Wang, Jie Zhang, Shiguang Shan, Xilin Chen
While text-to-image diffusion models demonstrate impressive generation capabilities, they also exhibit vulnerability to backdoor attacks, which involve the manipulation of model outputs through malicious triggers. In this paper, for the first time, we propose a comprehensive defense method named T2IShield to detect, localize, and mitigate such attacks. Specifically, we find the Assimilation Phenomenon on the cross-attention maps caused by the backdoor trigger. Based on this key insight, we propose two effective backdoor detection methods: Frobenius Norm Threshold Truncation and Covariance Discriminant Analysis. Besides, we introduce a binary-search approach to localize the trigger within a backdoor sample and assess the efficacy of existing concept editing methods in mitigating backdoor attacks. Empirical evaluations on two advanced backdoor attack scenarios show the effectiveness of our proposed defense method. For backdoor sample detection, T2IShield achieves a detection F1 score of 88.9$%$ with low computational cost. Furthermore, T2IShield achieves a localization F1 score of 86.4$%$ and invalidates 99$%$ poisoned samples. Codes are released at https://github.com/Robin-WZQ/T2IShield.
Read more7/18/2024