T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
2406.00636
0
0
🛸
Abstract
In this paper, we address the challenging problem of long-term 3D human motion generation. Specifically, we aim to generate a long sequence of smoothly connected actions from a stream of multiple sentences (i.e., paragraph). Previous long-term motion generating approaches were mostly based on recurrent methods, using previously generated motion chunks as input for the next step. However, this approach has two drawbacks: 1) it relies on sequential datasets, which are expensive; 2) these methods yield unrealistic gaps between motions generated at each step. To address these issues, we introduce simple yet effective T2LM, a continuous long-term generation framework that can be trained without sequential data. T2LM comprises two components: a 1D-convolutional VQVAE, trained to compress motion to sequences of latent vectors, and a Transformer-based Text Encoder that predicts a latent sequence given an input text. At inference, a sequence of sentences is translated into a continuous stream of latent vectors. This is then decoded into a motion by the VQVAE decoder; the use of 1D convolutions with a local temporal receptive field avoids temporal inconsistencies between training and generated sequences. This simple constraint on the VQ-VAE allows it to be trained with short sequences only and produces smoother transitions. T2LM outperforms prior long-term generation models while overcoming the constraint of requiring sequential data; it is also competitive with SOTA single-action generation models.
Create account to get full access
Overview
- This paper introduces T2LM, a model for generating long-term 3D human motion from sequential text.
- The key innovation is the ability to generate realistic, dynamic human motion that is coherent with the given text input over an extended time period.
- This represents an advancement over previous text-guided 3D motion generation approaches, which were limited to short-term or static poses.
Plain English Explanation
The researchers have developed a new system called T2LM that can take a sequence of text descriptions and use that to generate realistic 3D animations of a human moving and performing actions over an extended period of time. This builds on previous work in text-guided 3D human motion generation, but with the key improvement of being able to produce longer, more continuous and dynamic motions that stay true to the provided text.
For example, you could give the system a series of text prompts like "The person walks across the room, picks up a book, and then sits down at a desk and starts typing." T2LM would then generate a 3D animation of a human figure realistically carrying out those actions in a coherent, natural-looking way over an extended sequence. This goes beyond just generating individual static poses, and instead creates smooth, life-like motion that unfolds over time in response to the text instructions.
The researchers see this as an important step forward, as being able to generate longer, more complex human motion from text has many potential applications, such as in video game development, virtual reality experiences, and automated content creation. It allows for a more intuitive and expressive way to direct and control 3D character animations compared to traditional animation techniques.
Technical Explanation
The key technical innovation in T2LM is the use of a Transformer-based architecture that can effectively model the long-range dependencies between the input text and the resulting 3D motion sequence. This builds on the progress made in large language models like MotionLLM which have shown the power of language modeling for motion synthesis.
The model takes in a sequence of text descriptions as input, and outputs a corresponding sequence of 3D joint positions representing the human motion. This is achieved through a multi-stage process:
- Text Encoder: A Transformer encodes the input text into a compact, high-level representation.
- Motion Decoder: Another Transformer-based decoder network uses this text encoding to progressively generate the 3D joint positions frame-by-frame, maintaining long-term coherence.
- Motion Refinement: A final module refines the generated motion to improve its realism and natural flow.
The researchers trained and evaluated T2LM on large datasets of paired text descriptions and 3D human motion capture data. Their results show significant improvements over prior text-to-motion methods in terms of the quality, variety, and long-term coherence of the generated animations.
Critical Analysis
One potential limitation of the T2LM approach is that it still requires paired text-motion training data, which can be expensive and time-consuming to collect at scale. The researchers note this is an area for future work, similar to efforts toward more open-domain text-driven motion synthesis.
Additionally, while the generated motions are impressive, they are still limited to the human figure and do not incorporate interactions with other objects or characters in the 3D scene. Extending the text-to-motion capabilities to more complex, multi-agent scenarios could be an interesting direction for further research.
Overall, however, the T2LM model represents a significant advance in the state-of-the-art for text-guided 3D human motion generation. The ability to produce long-term, coherent animations from text descriptions has many promising real-world applications and sets the stage for continued progress in this area.
Conclusion
The T2LM model introduced in this paper demonstrates the potential for advanced language models to drive the synthesis of realistic, long-term 3D human motion from text. By leveraging Transformer architectures and large datasets, the researchers have developed a system that can generate smooth, dynamic animations that seamlessly match the provided textual descriptions.
This work builds on and extends previous efforts in text-guided 3D motion generation, representing an important step forward in making character animation more accessible and intuitive. The implications span areas like virtual reality, video game development, and automated content creation, where the ability to control 3D character motion through natural language instructions could be transformative.
While there are still some limitations to address, the T2LM model showcases the power of language models to drive the synthesis of realistic, temporally-coherent human motion. As this field continues to advance, we can expect to see increasingly sophisticated and versatile text-to-motion systems emerge, further blurring the lines between language and 3D animation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
Zichen Geng, Caren Han, Zeeshan Hayder, Jian Liu, Mubarak Shah, Ajmal Mian
0
0
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
5/27/2024
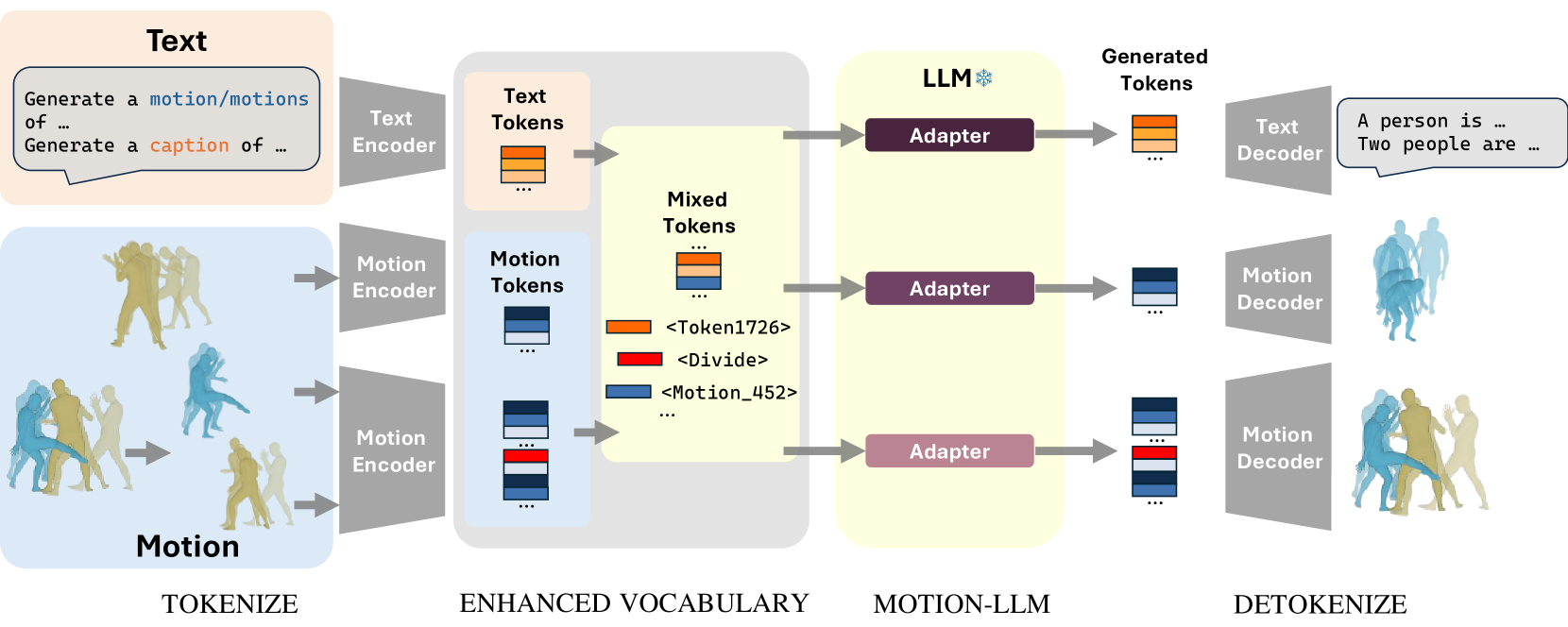
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
0
0
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
5/29/2024
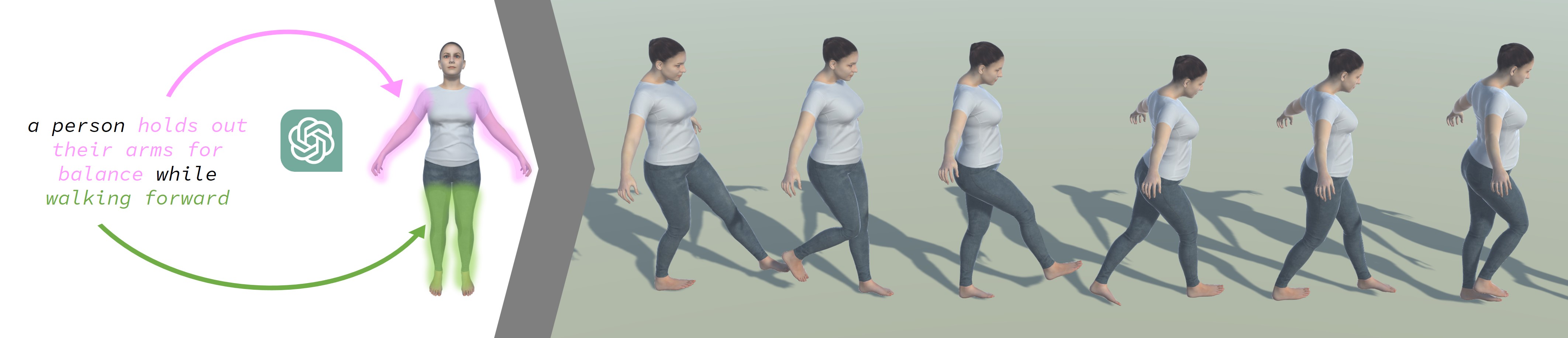
LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
Haowen Sun, Ruikun Zheng, Haibin Huang, Chongyang Ma, Hui Huang, Ruizhen Hu
0
0
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM
5/7/2024
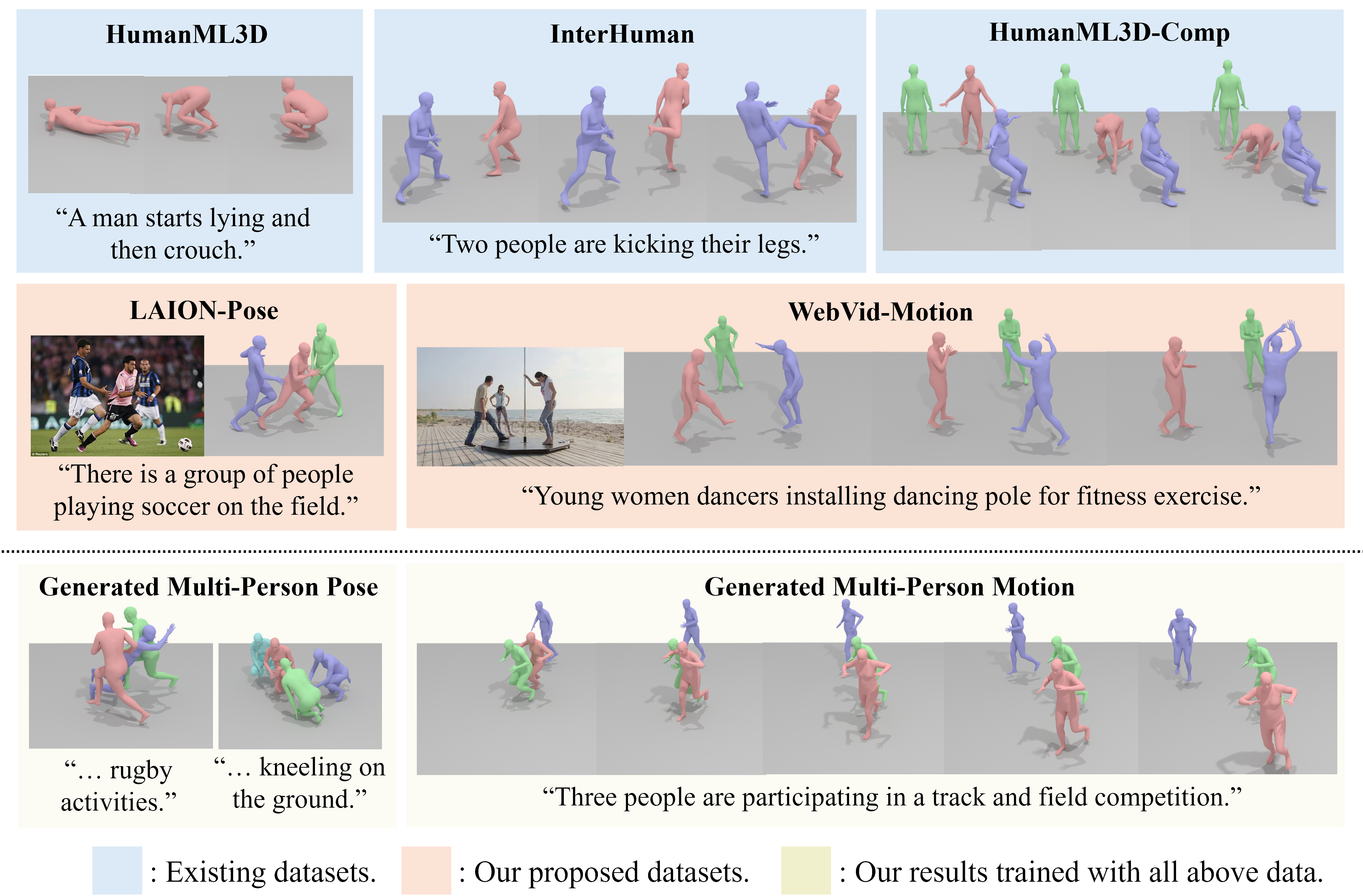
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, Mitch Hill
0
0
This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
5/30/2024