TabKANet: Tabular Data Modelling with Kolmogorov-Arnold Network and Transformer

0

Sign in to get full access
Overview
- TabKANet is a new deep learning model for tabular data modeling that combines the Kolmogorov-Arnold Network (KAN) and Transformer architectures.
- The model aims to capture both linear and non-linear relationships in tabular data through the KAN component, while the Transformer component models contextual feature interactions.
- The paper presents the architecture of TabKANet and evaluates its performance on various tabular data benchmarks.
Plain English Explanation
The researchers developed a new machine learning model called TabKANet that is designed to work well with tabular data, which is data organized in rows and columns like a spreadsheet. Tabular data is commonly used in business and scientific applications.
The key idea behind TabKANet is to combine two powerful machine learning techniques: the Kolmogorov-Arnold Network (KAN) and the Transformer. The KAN component is able to capture both linear and non-linear relationships in the data, while the Transformer component can model how the different features in the data interact with each other in a contextual way.
By bringing these two components together, the researchers hope to create a model that can effectively learn patterns and make accurate predictions from complex tabular data. They evaluated TabKANet on several standard benchmark datasets for tabular data and found that it outperformed other popular machine learning models.
Technical Explanation
The TabKANet architecture consists of two main components:
-
Kolmogorov-Arnold Network (KAN): This component is designed to capture both linear and non-linear relationships in the input tabular data. The KAN uses a series of fully connected layers to learn a series of transformations that can approximate any continuous function, as per the Kolmogorov-Arnold superposition theorem.
-
Transformer: This component models the contextual interactions between the different features in the tabular data. It uses the self-attention mechanism of the Transformer to learn how the features relate to and depend on each other.
The outputs from the KAN and Transformer components are then combined and passed through additional fully connected layers to produce the final prediction.
The researchers evaluated TabKANet on several tabular data benchmarks including regression, classification, and time series forecasting tasks. They found that TabKANet outperformed other state-of-the-art models like XGBoost, LightGBM, and previously proposed tabular data models.
Critical Analysis
The paper provides a thorough technical explanation of the TabKANet architecture and demonstrates its strong empirical performance on a range of tabular data tasks. However, a few potential limitations or areas for further research are worth noting:
- The experiments are limited to standard benchmark datasets, and further evaluation on real-world business or scientific tabular datasets could provide additional insights.
- The paper does not explore the computational efficiency or inference speed of TabKANet compared to other models, which could be an important practical consideration.
- The relative contributions of the KAN and Transformer components to the overall model performance are not clearly delineated, so it's unclear how much each component is contributing to the final results.
Overall, TabKANet appears to be a promising new approach for tabular data modeling, but additional research and real-world testing could help further validate its capabilities and limitations.
Conclusion
The TabKANet model presented in this paper offers a novel way to leverage the strengths of Kolmogorov-Arnold Networks and Transformers for effective tabular data modeling. By combining these two powerful machine learning techniques, the researchers have developed a model that can capture both linear and non-linear relationships as well as feature interactions in tabular datasets.
The strong empirical results on benchmark tasks suggest TabKANet has the potential to improve predictive performance in a wide range of business, scientific, and other applications that rely on tabular data. As the use of machine learning continues to grow in these domains, models like TabKANet could play an important role in unlocking valuable insights from complex, structured datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TabKANet: Tabular Data Modelling with Kolmogorov-Arnold Network and Transformer
Weihao Gao, Zheng Gong, Zhuo Deng, Fuju Rong, Chucheng Chen, Lan Ma
Tabular data is the most common type of data in real-life scenarios. In this study, we propose a method based on the TabKANet architecture, which utilizes the Kolmogorov-Arnold network to encode numerical features and merge them with categorical features, enabling unified modeling of tabular data on the Transformer architecture. This model demonstrates outstanding performance in six widely used binary classification tasks, suggesting that TabKANet has the potential to become a standard approach for tabular modeling, surpassing traditional neural networks. Furthermore, this research reveals the significant advantages of the Kolmogorov-Arnold network in encoding numerical features. The code of our work is available at https://github.com/tsinghuamedgao20/TabKANet.
Read more9/16/2024
0
A Benchmarking Study of Kolmogorov-Arnold Networks on Tabular Data
Eleonora Poeta, Flavio Giobergia, Eliana Pastor, Tania Cerquitelli, Elena Baralis
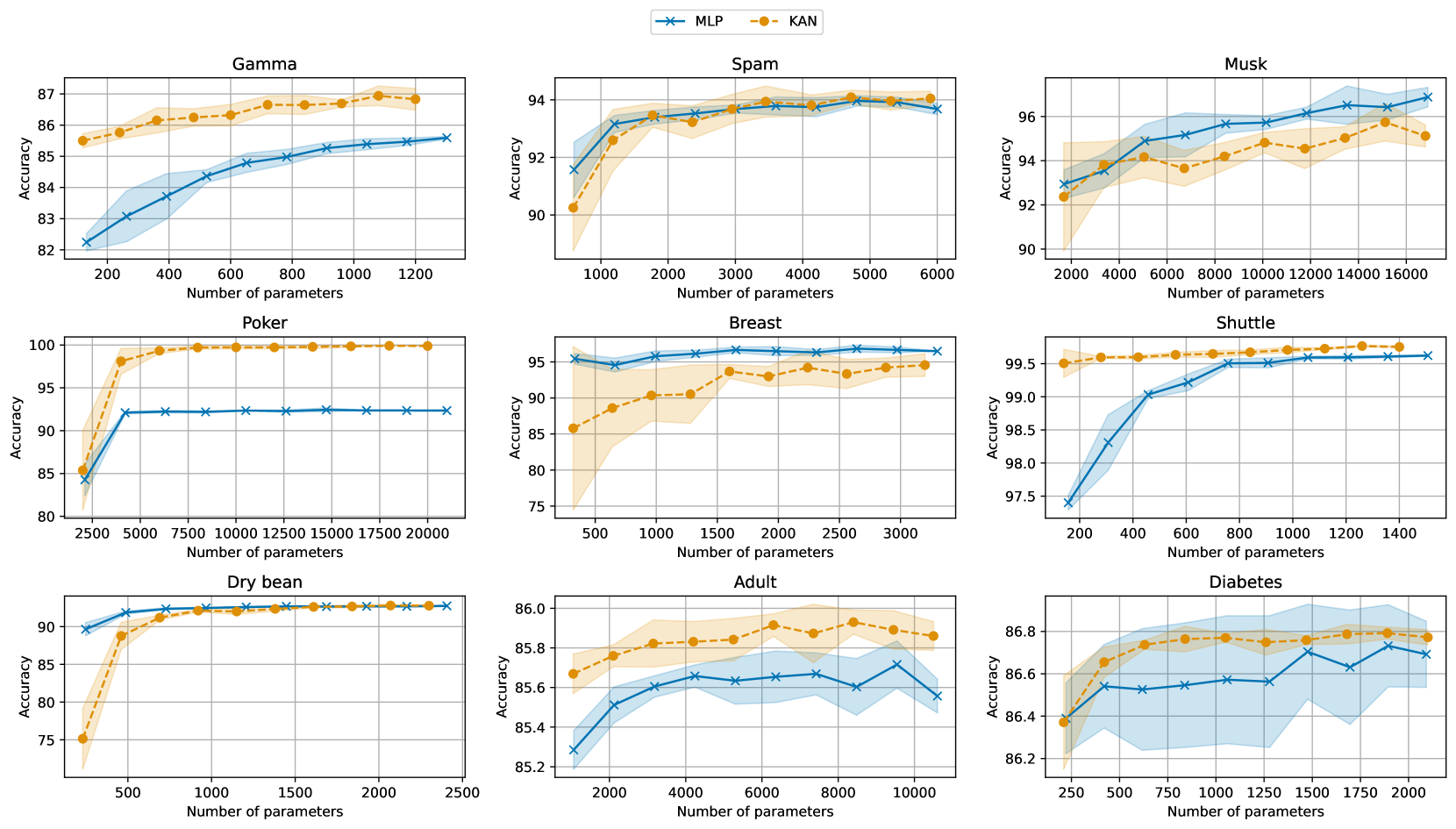
Kolmogorov-Arnold Networks (KANs) have very recently been introduced into the world of machine learning, quickly capturing the attention of the entire community. However, KANs have mostly been tested for approximating complex functions or processing synthetic data, while a test on real-world tabular datasets is currently lacking. In this paper, we present a benchmarking study comparing KANs and Multi-Layer Perceptrons (MLPs) on tabular datasets. The study evaluates task performance and training times. From the results obtained on the various datasets, KANs demonstrate superior or comparable accuracy and F1 scores, excelling particularly in datasets with numerous instances, suggesting robust handling of complex data. We also highlight that this performance improvement of KANs comes with a higher computational cost when compared to MLPs of comparable sizes.
Read more6/21/2024

0
New!Kolmogorov-Arnold Transformer
Xingyi Yang, Xinchao Wang
Transformers stand as the cornerstone of mordern deep learning. Traditionally, these models rely on multi-layer perceptron (MLP) layers to mix the information between channels. In this paper, we introduce the Kolmogorov-Arnold Transformer (KAT), a novel architecture that replaces MLP layers with Kolmogorov-Arnold Network (KAN) layers to enhance the expressiveness and performance of the model. Integrating KANs into transformers, however, is no easy feat, especially when scaled up. Specifically, we identify three key challenges: (C1) Base function. The standard B-spline function used in KANs is not optimized for parallel computing on modern hardware, resulting in slower inference speeds. (C2) Parameter and Computation Inefficiency. KAN requires a unique function for each input-output pair, making the computation extremely large. (C3) Weight initialization. The initialization of weights in KANs is particularly challenging due to their learnable activation functions, which are critical for achieving convergence in deep neural networks. To overcome the aforementioned challenges, we propose three key solutions: (S1) Rational basis. We replace B-spline functions with rational functions to improve compatibility with modern GPUs. By implementing this in CUDA, we achieve faster computations. (S2) Group KAN. We share the activation weights through a group of neurons, to reduce the computational load without sacrificing performance. (S3) Variance-preserving initialization. We carefully initialize the activation weights to make sure that the activation variance is maintained across layers. With these designs, KAT scales effectively and readily outperforms traditional MLP-based transformers.
Read more9/18/2024

0
A Temporal Kolmogorov-Arnold Transformer for Time Series Forecasting
Remi Genet, Hugo Inzirillo
Capturing complex temporal patterns and relationships within multivariate data streams is a difficult task. We propose the Temporal Kolmogorov-Arnold Transformer (TKAT), a novel attention-based architecture designed to address this task using Temporal Kolmogorov-Arnold Networks (TKANs). Inspired by the Temporal Fusion Transformer (TFT), TKAT emerges as a powerful encoder-decoder model tailored to handle tasks in which the observed part of the features is more important than the a priori known part. This new architecture combined the theoretical foundation of the Kolmogorov-Arnold representation with the power of transformers. TKAT aims to simplify the complex dependencies inherent in time series, making them more interpretable. The use of transformer architecture in this framework allows us to capture long-range dependencies through self-attention mechanisms.
Read more6/6/2024