Tabular and Deep Reinforcement Learning for Gittins Index

0
Sign in to get full access
Introduction
This paper explores the use of tabular and deep reinforcement learning (RL) methods to efficiently compute the Gittins index, a well-known concept in the field of multi-armed bandits. The Gittins index is a theoretical tool that helps determine the optimal strategy for allocating resources across different tasks or projects with uncertain rewards. By leveraging RL techniques, the authors aim to develop practical algorithms that can effectively compute the Gittins index in a variety of real-world scenarios.
Plain English Explanation
The Gittins index is a mathematical concept used in decision-making when faced with multiple options with uncertain payoffs, like choosing which stocks to invest in or which projects to work on. It helps determine the best strategy for maximizing the overall reward over time. However, calculating the Gittins index can be computationally complex, especially for large or dynamic systems.
The researchers in this paper explore using tabular and deep reinforcement learning as a way to more efficiently compute the Gittins index. Reinforcement learning is a type of machine learning where an agent learns by interacting with an environment and receiving feedback (rewards or penalties) for its actions.
By applying RL techniques, the researchers aim to develop algorithms that can quickly and accurately determine the Gittins index for different decision-making problems. This could have important implications for industries like finance, resource management, and project planning, where optimal decision-making under uncertainty is crucial.
Technical Explanation
The paper begins by providing an overview of the multi-armed bandit problem and the Gittins index, which is a principled way to solve this problem. The authors then introduce two approaches for computing the Gittins index using reinforcement learning:
-
Tabular RL: The authors formulate the problem of computing the Gittins index as a Markov decision process (MDP) and use a tabular Q-learning algorithm to learn the optimal policy.
-
Deep RL: For more complex problems, the authors propose a deep RL approach that uses a neural network to approximate the Gittins index function, allowing for efficient computation in high-dimensional state spaces.
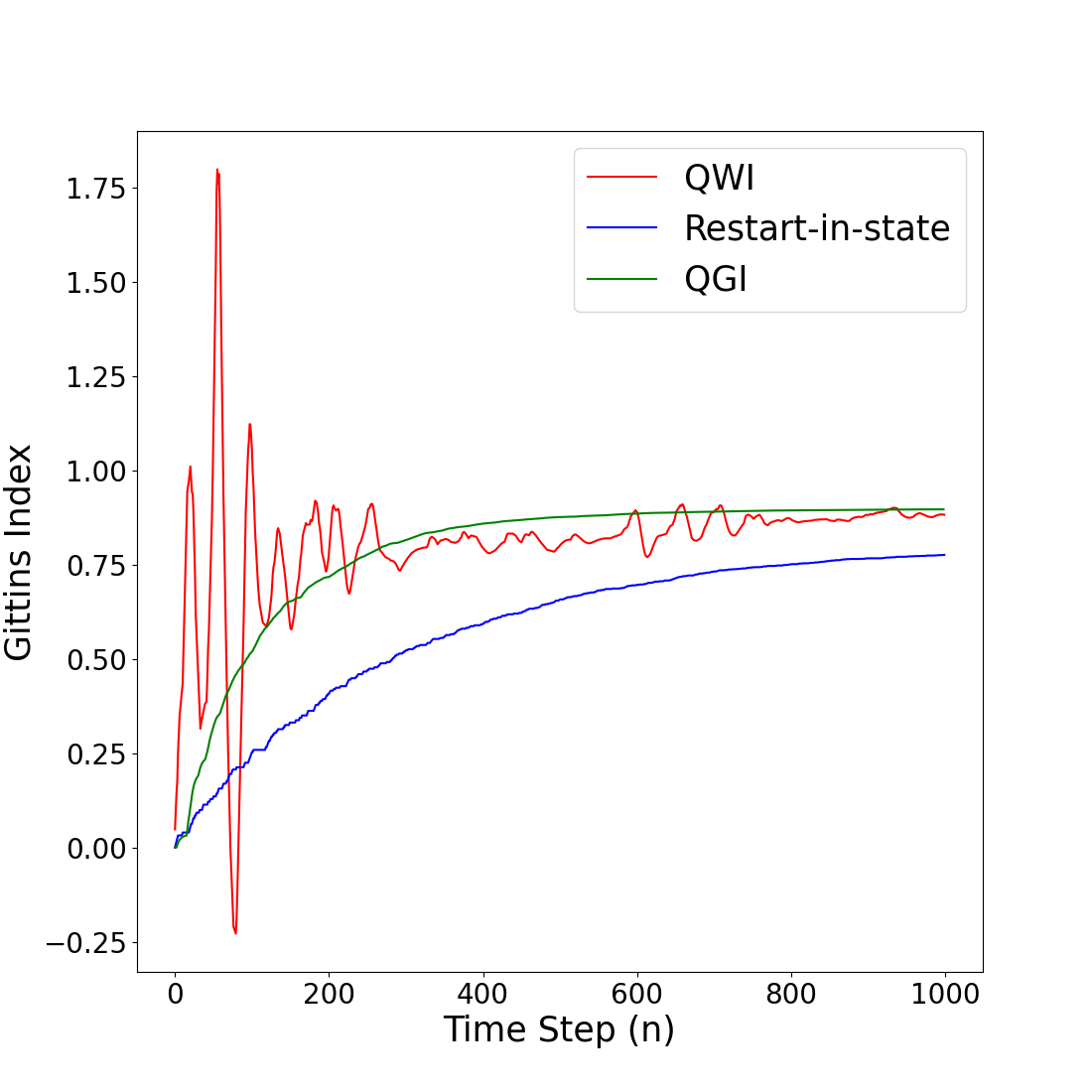
The researchers evaluate their methods on a series of benchmark problems, including classical multi-armed bandit scenarios as well as more complex restless bandit problems. They compare the performance of their RL-based approaches to existing analytical and numerical methods for computing the Gittins index.
Critical Analysis
The key strength of this work is the attempt to make the computation of the Gittins index more practical and scalable through the use of RL techniques. This is an important step, as the Gittins index is a powerful but computationally challenging concept that has been difficult to apply in many real-world settings.
However, the paper does not provide a comprehensive analysis of the limitations and potential issues with the proposed RL-based approaches. For example, the authors do not discuss how the performance of their methods might be affected by factors such as the size and complexity of the problem, the quality of the function approximation in the deep RL approach, or the stability and convergence properties of the RL algorithms.
Additionally, the authors could have provided more insights into the tradeoffs between the tabular and deep RL methods, such as the relative computational efficiency, sample complexity, and generalization capabilities of each approach.
Conclusion
This paper presents a novel approach to computing the Gittins index using reinforcement learning techniques. By formulating the problem as an MDP and leveraging both tabular and deep RL methods, the researchers have taken an important step towards making the Gittins index more accessible and applicable in real-world decision-making scenarios.
While the paper demonstrates the potential of these RL-based approaches, further research is needed to fully understand their limitations and to explore ways to improve their robustness and scalability. Nonetheless, this work represents a valuable contribution to the field of multi-armed bandit optimization and decision-making under uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tabular and Deep Reinforcement Learning for Gittins Index
Harshit Dhankar, Kshitij Mishra, Tejas Bodas
In the realm of multi-arm bandit problems, the Gittins index policy is known to be optimal in maximizing the expected total discounted reward obtained from pulling the Markovian arms. In most realistic scenarios however, the Markovian state transition probabilities are unknown and therefore the Gittins indices cannot be computed. One can then resort to reinforcement learning (RL) algorithms that explore the state space to learn these indices while exploiting to maximize the reward collected. In this work, we propose tabular (QGI) and Deep RL (DGN) algorithms for learning the Gittins index that are based on the retirement formulation for the multi-arm bandit problem. When compared with existing RL algorithms that learn the Gittins index, our algorithms have a lower run time, require less storage space (small Q-table size in QGI and smaller replay buffer in DGN), and illustrate better empirical convergence to the Gittins index. This makes our algorithm well suited for problems with large state spaces and is a viable alternative to existing methods. As a key application, we demonstrate the use of our algorithms in minimizing the mean flowtime in a job scheduling problem when jobs are available in batches and have an unknown service time distribution.
Read more5/3/2024

0
GINO-Q: Learning an Asymptotically Optimal Index Policy for Restless Multi-armed Bandits
Gongpu Chen, Soung Chang Liew, Deniz Gunduz
The restless multi-armed bandit (RMAB) framework is a popular model with applications across a wide variety of fields. However, its solution is hindered by the exponentially growing state space (with respect to the number of arms) and the combinatorial action space, making traditional reinforcement learning methods infeasible for large-scale instances. In this paper, we propose GINO-Q, a three-timescale stochastic approximation algorithm designed to learn an asymptotically optimal index policy for RMABs. GINO-Q mitigates the curse of dimensionality by decomposing the RMAB into a series of subproblems, each with the same dimension as a single arm, ensuring that complexity increases linearly with the number of arms. Unlike recently developed Whittle-index-based algorithms, GINO-Q does not require RMABs to be indexable, enhancing its flexibility and applicability. Our experimental results demonstrate that GINO-Q consistently learns near-optimal policies, even for non-indexable RMABs where Whittle-index-based algorithms perform poorly, and it converges significantly faster than existing baselines.
Read more8/20/2024
🤿
0
Tabular and Deep Learning for the Whittle Index
Francisco Robledo Rela~no (LMAP, UPPA, UPV / EHU), Vivek Borkar (EE-IIT), Urtzi Ayesta (IRIT-RMESS, UPV/EHU, CNRS), Konstantin Avrachenkov (Inria)
The Whittle index policy is a heuristic that has shown remarkably good performance (with guaranteed asymptotic optimality) when applied to the class of problems known as Restless Multi-Armed Bandit Problems (RMABPs). In this paper we present QWI and QWINN, two reinforcement learning algorithms, respectively tabular and deep, to learn the Whittle index for the total discounted criterion. The key feature is the use of two time-scales, a faster one to update the state-action Q -values, and a relatively slower one to update the Whittle indices. In our main theoretical result we show that QWI, which is a tabular implementation, converges to the real Whittle indices. We then present QWINN, an adaptation of QWI algorithm using neural networks to compute the Q -values on the faster time-scale, which is able to extrapolate information from one state to another and scales naturally to large state-space environments. For QWINN, we show that all local minima of the Bellman error are locally stable equilibria, which is the first result of its kind for DQN-based schemes. Numerical computations show that QWI and QWINN converge faster than the standard Q -learning algorithm, neural-network based approximate Q-learning and other state of the art algorithms.
Read more6/5/2024

0
PCL-Indexability and Whittle Index for Restless Bandits with General Observation Models
Keqin Liu, Chengzhong Zhang
In this paper, we consider a general observation model for restless multi-armed bandit problems. The operation of the player needs to be based on certain feedback mechanism that is error-prone due to resource constraints or environmental or intrinsic noises. By establishing a general probabilistic model for dynamics of feedback/observation, we formulate the problem as a restless bandit with a countable belief state space starting from an arbitrary initial belief (a priori information). We apply the achievable region method with partial conservation law (PCL) to the infinite-state problem and analyze its indexability and priority index (Whittle index). Finally, we propose an approximation process to transform the problem into which the AG algorithm of Ni~no-Mora and Bertsimas for finite-state problems can be applied to. Numerical experiments show that our algorithm has an excellent performance.
Read more7/4/2024