Tabular and Deep Learning for the Whittle Index

0
🤿
Sign in to get full access
Overview
- This paper investigates the application of the Whittle index, a prominent approach in the field of restless multi-armed bandits, to tabular and deep learning methods.
- The Whittle index is a key concept in dynamic resource allocation, which aims to optimally allocate limited resources across multiple competing tasks.
- The researchers explore how tabular and deep learning techniques can be used to estimate the Whittle index, which is important for reinforcement learning and portfolio management.
Plain English Explanation
The paper focuses on a concept called the Whittle index, which is a way to measure the value or importance of different tasks or projects that are competing for limited resources. Imagine you have a bunch of different tasks that all need your attention, but you can only focus on a few at a time. The Whittle index helps you figure out which tasks are the most important or valuable to work on.
The researchers in this paper explore how to use two different machine learning techniques, called tabular and deep learning, to estimate or calculate the Whittle index. Tabular methods use straightforward data tables, while deep learning uses more complex artificial neural networks. By using these techniques, the researchers hope to make it easier and more efficient to figure out the Whittle index, which is important for making decisions about how to allocate limited resources, like in reinforcement learning and portfolio management.
Technical Explanation
The paper presents a novel approach to estimating the Whittle index, a key concept in the field of restless multi-armed bandits, using both tabular and deep learning methods. The Whittle index is a way to measure the relative importance or value of different tasks or projects that are competing for limited resources, which is crucial for reinforcement learning and portfolio management applications.
The researchers first develop a tabular method for estimating the Whittle index, which involves constructing a lookup table of index values based on the system parameters. They then propose a deep learning approach that uses a neural network to learn the Whittle index mapping directly from data, without the need for a pre-computed table.
Through a series of experiments, the researchers demonstrate that both the tabular and deep learning methods can accurately estimate the Whittle index across a range of problem instances. They also show that the deep learning approach, in particular, can scale to larger and more complex problems where the tabular method becomes intractable.
Critical Analysis
The paper provides a compelling exploration of using tabular and deep learning techniques to estimate the Whittle index, which is a significant contribution to the field of dynamic resource allocation. However, the researchers acknowledge several limitations and areas for further research.
One limitation is that the performance of the proposed methods may be sensitive to the specific problem instance and system parameters. The researchers suggest that further work is needed to understand the generalization capabilities of the techniques and how they might perform on a wider range of real-world scenarios.
Additionally, the paper does not address the computational complexity and training time requirements of the deep learning approach, which could be a concern for some applications where fast decision-making is required. Exploring ways to improve the efficiency of the deep learning method would be a valuable avenue for future research.
Finally, the researchers do not discuss the potential ethical implications of using these techniques for resource allocation, such as the risk of introducing biases or unfairly prioritizing certain tasks over others. Addressing these ethical considerations would be an important step in ensuring the responsible development and deployment of these methods.
Conclusion
This paper presents a novel approach to estimating the Whittle index, a critical concept in the field of dynamic resource allocation, using both tabular and deep learning methods. The researchers demonstrate that these techniques can accurately estimate the Whittle index, with the deep learning approach showing particular promise for scaling to larger and more complex problems.
The findings of this paper have important implications for reinforcement learning and portfolio management applications, where the efficient allocation of limited resources is crucial. As the researchers continue to explore the limitations and ethical considerations of their methods, the potential for these techniques to drive advancements in dynamic resource allocation is significant.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Tabular and Deep Learning for the Whittle Index
Francisco Robledo Rela~no (LMAP, UPPA, UPV / EHU), Vivek Borkar (EE-IIT), Urtzi Ayesta (IRIT-RMESS, UPV/EHU, CNRS), Konstantin Avrachenkov (Inria)
The Whittle index policy is a heuristic that has shown remarkably good performance (with guaranteed asymptotic optimality) when applied to the class of problems known as Restless Multi-Armed Bandit Problems (RMABPs). In this paper we present QWI and QWINN, two reinforcement learning algorithms, respectively tabular and deep, to learn the Whittle index for the total discounted criterion. The key feature is the use of two time-scales, a faster one to update the state-action Q -values, and a relatively slower one to update the Whittle indices. In our main theoretical result we show that QWI, which is a tabular implementation, converges to the real Whittle indices. We then present QWINN, an adaptation of QWI algorithm using neural networks to compute the Q -values on the faster time-scale, which is able to extrapolate information from one state to another and scales naturally to large state-space environments. For QWINN, we show that all local minima of the Bellman error are locally stable equilibria, which is the first result of its kind for DQN-based schemes. Numerical computations show that QWI and QWINN converge faster than the standard Q -learning algorithm, neural-network based approximate Q-learning and other state of the art algorithms.
Read more6/5/2024

0
Whittle Index Learning Algorithms for Restless Bandits with Constant Stepsizes
Vishesh Mittal, Rahul Meshram, Surya Prakash
We study the Whittle index learning algorithm for restless multi-armed bandits. We consider index learning algorithm with Q-learning. We first present Q-learning algorithm with exploration policies -- epsilon-greedy, softmax, epsilon-softmax with constant stepsizes. We extend the study of Q-learning to index learning for single-armed restless bandit. The algorithm of index learning is two-timescale variant of stochastic approximation, on slower timescale we update index learning scheme and on faster timescale we update Q-learning assuming fixed index value. In Q-learning updates are in asynchronous manner. We study constant stepsizes two timescale stochastic approximation algorithm. We provide analysis of two-timescale stochastic approximation for index learning with constant stepsizes. Further, we present study on index learning with deep Q-network (DQN) learning and linear function approximation with state-aggregation method. We describe the performance of our algorithms using numerical examples. We have shown that index learning with Q learning, DQN and function approximations learns the Whittle index.
Read more9/10/2024
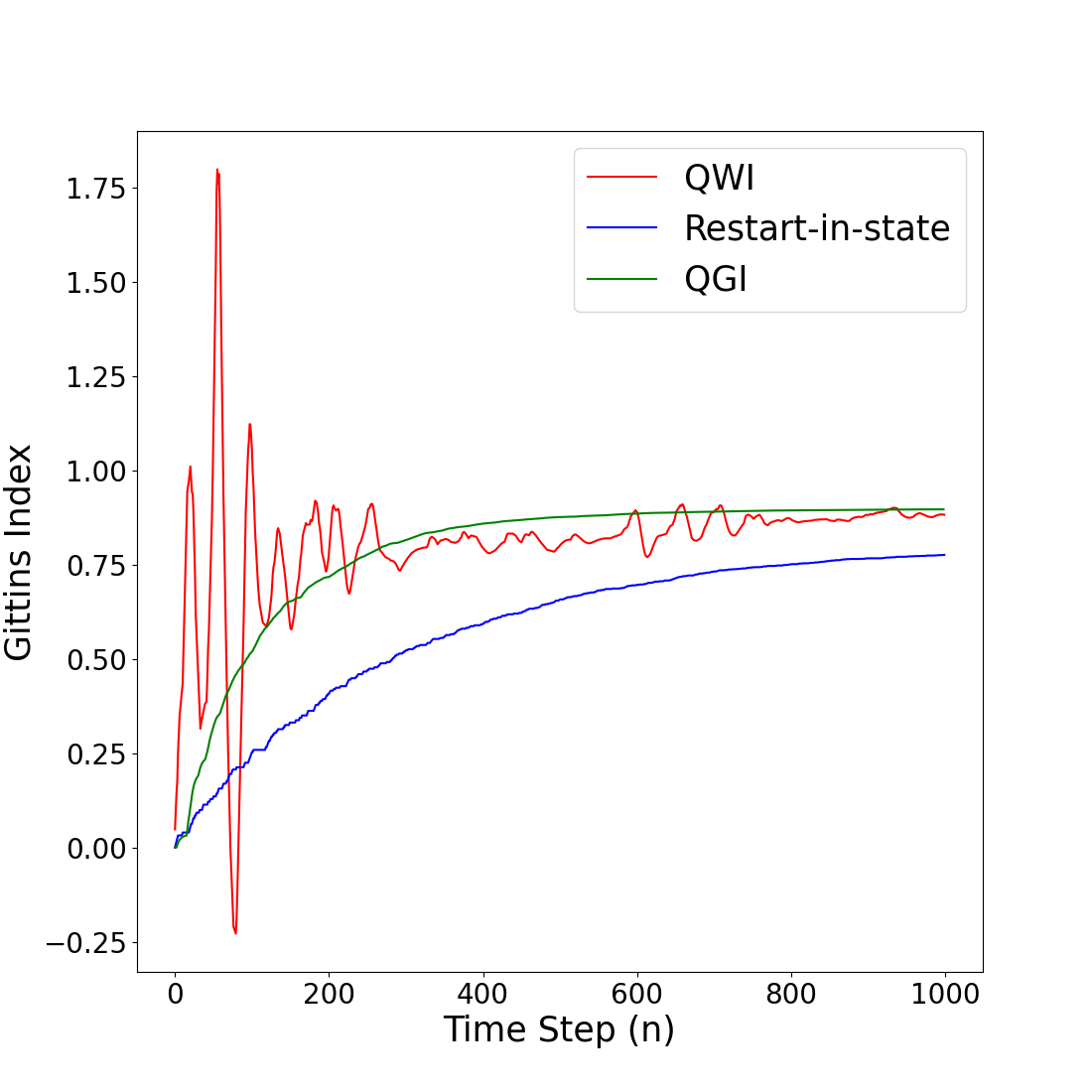
0
Tabular and Deep Reinforcement Learning for Gittins Index
Harshit Dhankar, Kshitij Mishra, Tejas Bodas
In the realm of multi-arm bandit problems, the Gittins index policy is known to be optimal in maximizing the expected total discounted reward obtained from pulling the Markovian arms. In most realistic scenarios however, the Markovian state transition probabilities are unknown and therefore the Gittins indices cannot be computed. One can then resort to reinforcement learning (RL) algorithms that explore the state space to learn these indices while exploiting to maximize the reward collected. In this work, we propose tabular (QGI) and Deep RL (DGN) algorithms for learning the Gittins index that are based on the retirement formulation for the multi-arm bandit problem. When compared with existing RL algorithms that learn the Gittins index, our algorithms have a lower run time, require less storage space (small Q-table size in QGI and smaller replay buffer in DGN), and illustrate better empirical convergence to the Gittins index. This makes our algorithm well suited for problems with large state spaces and is a viable alternative to existing methods. As a key application, we demonstrate the use of our algorithms in minimizing the mean flowtime in a job scheduling problem when jobs are available in batches and have an unknown service time distribution.
Read more5/3/2024

0
PCL-Indexability and Whittle Index for Restless Bandits with General Observation Models
Keqin Liu, Chengzhong Zhang
In this paper, we consider a general observation model for restless multi-armed bandit problems. The operation of the player needs to be based on certain feedback mechanism that is error-prone due to resource constraints or environmental or intrinsic noises. By establishing a general probabilistic model for dynamics of feedback/observation, we formulate the problem as a restless bandit with a countable belief state space starting from an arbitrary initial belief (a priori information). We apply the achievable region method with partial conservation law (PCL) to the infinite-state problem and analyze its indexability and priority index (Whittle index). Finally, we propose an approximation process to transform the problem into which the AG algorithm of Ni~no-Mora and Bertsimas for finite-state problems can be applied to. Numerical experiments show that our algorithm has an excellent performance.
Read more7/4/2024