TacDiffusion: Force-domain Diffusion Policy for Precise Tactile Manipulation

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!TacDiffusion: Force-domain Diffusion Policy for Precise Tactile Manipulation
Yansong Wu, Zongxie Chen, Fan Wu, Lingyun Chen, Liding Zhang, Zhenshan Bing, Abdalla Swikir, Alois Knoll, Sami Haddadin
Assembly is a crucial skill for robots in both modern manufacturing and service robotics. However, mastering transferable insertion skills that can handle a variety of high-precision assembly tasks remains a significant challenge. This paper presents a novel framework that utilizes diffusion models to generate 6D wrench for high-precision tactile robotic insertion tasks. It learns from demonstrations performed on a single task and achieves a zero-shot transfer success rate of 95.7% across various novel high-precision tasks. Our method effectively inherits the self-adaptability demonstrated by our previous work. In this framework, we address the frequency misalignment between the diffusion policy and the real-time control loop with a dynamic system-based filter, significantly improving the task success rate by 9.15%. Furthermore, we provide a practical guideline regarding the trade-off between diffusion models' inference ability and speed.
Read more9/18/2024
0
Dexterous Functional Pre-Grasp Manipulation with Diffusion Policy
Tianhao Wu, Yunchong Gan, Mingdong Wu, Jingbo Cheng, Yaodong Yang, Yixin Zhu, Hao Dong
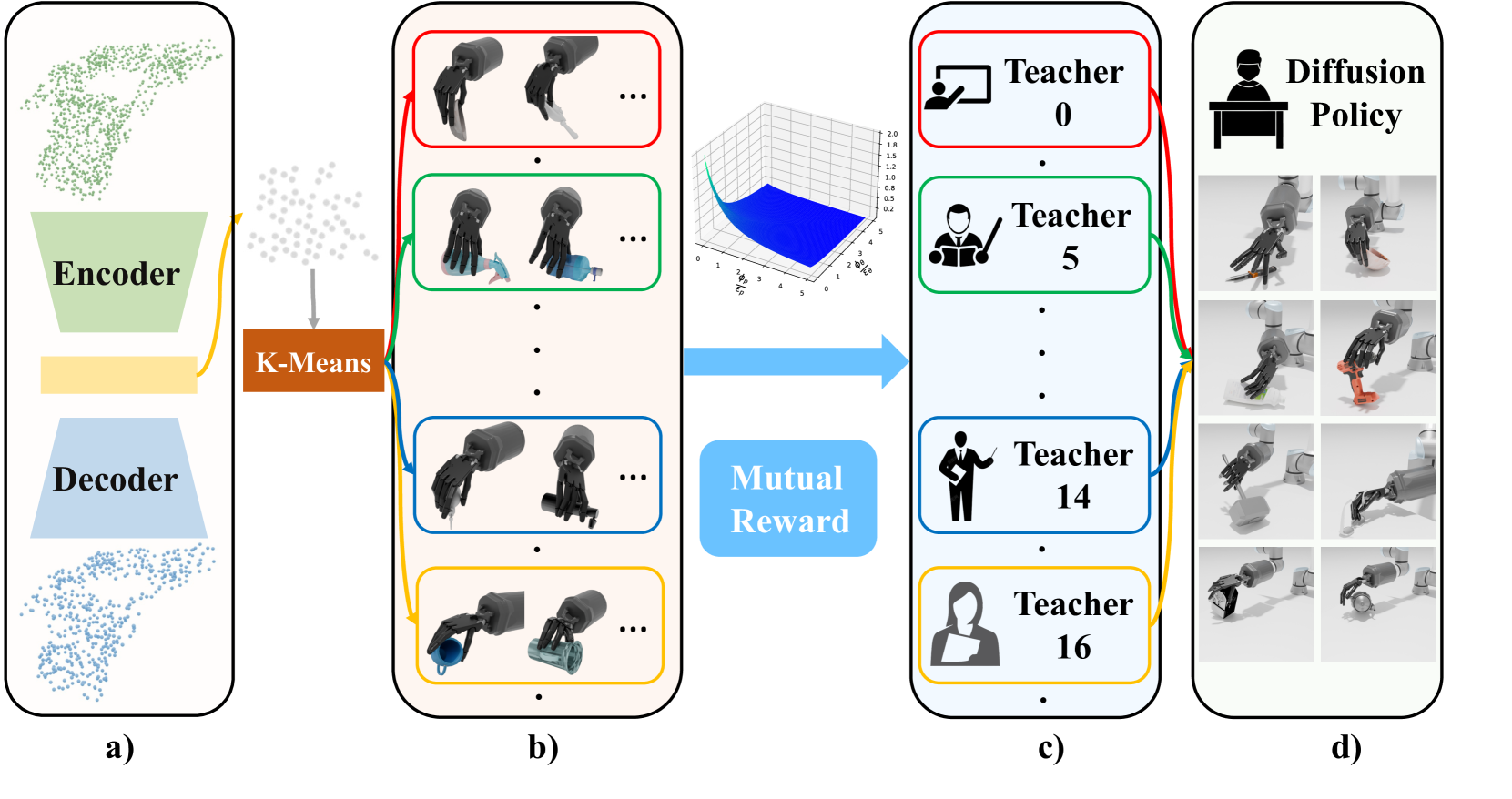
In real-world scenarios, objects often require repositioning and reorientation before they can be grasped, a process known as pre-grasp manipulation. Learning universal dexterous functional pre-grasp manipulation requires precise control over the relative position, orientation, and contact between the hand and object while generalizing to diverse dynamic scenarios with varying objects and goal poses. To address this challenge, we propose a teacher-student learning approach that utilizes a novel mutual reward, incentivizing agents to optimize three key criteria jointly. Additionally, we introduce a pipeline that employs a mixture-of-experts strategy to learn diverse manipulation policies, followed by a diffusion policy to capture complex action distributions from these experts. Our method achieves a success rate of 72.6% across more than 30 object categories by leveraging extrinsic dexterity and adjusting from feedback.
Read more5/7/2024
0
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
Guanxing Lu, Zifeng Gao, Tianxing Chen, Wenxun Dai, Ziwei Wang, Yansong Tang
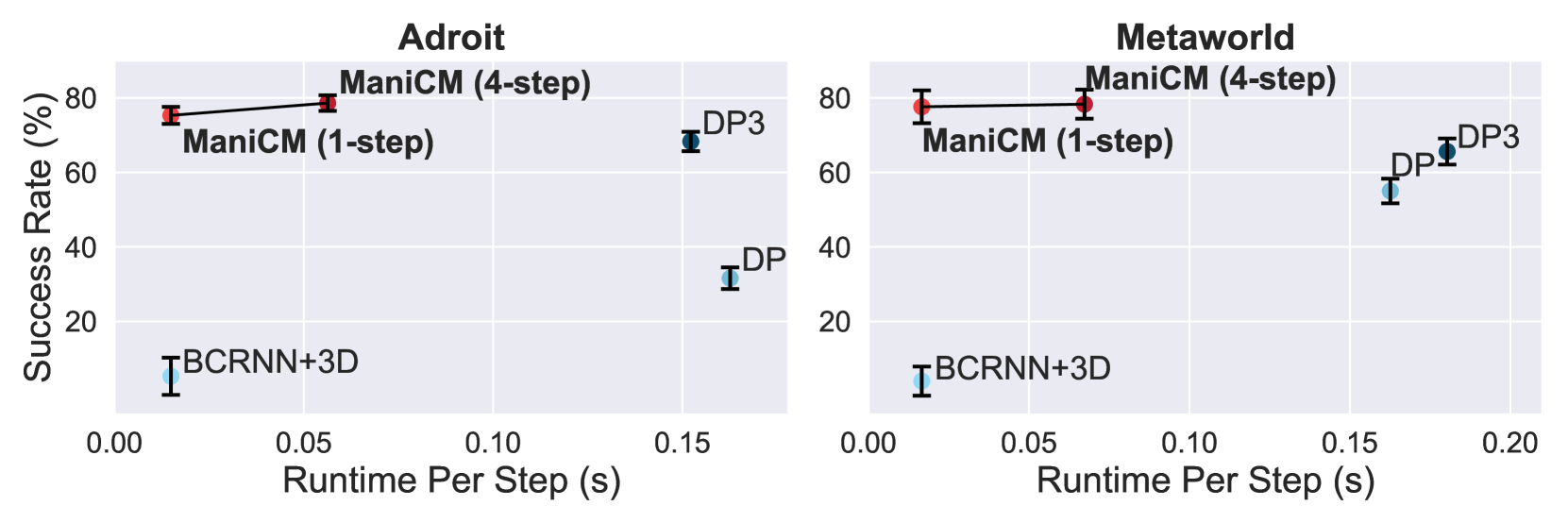
Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
Read more6/4/2024
0
TEDi Policy: Temporally Entangled Diffusion for Robotic Control
Sigmund H. H{o}eg, Lars Tingelstad
Diffusion models have been shown to excel in robotic imitation learning by mastering the challenge of modeling complex distributions. However, sampling speed has traditionally not been a priority due to their popularity for image generation, limiting their application to dynamical tasks. While recent work has improved the sampling speed of diffusion-based robotic policies, they are restricted to techniques from the image generation domain. We adapt Temporally Entangled Diffusion (TEDi), a framework specific for trajectory generation, to speed up diffusion-based policies for imitation learning. We introduce TEDi Policy, with novel regimes for training and sampling, and show that it drastically improves the sampling speed while remaining performant when applied to state-of-the-art diffusion-based imitation learning policies.
Read more7/29/2024