ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
2406.01586
0
0
Abstract
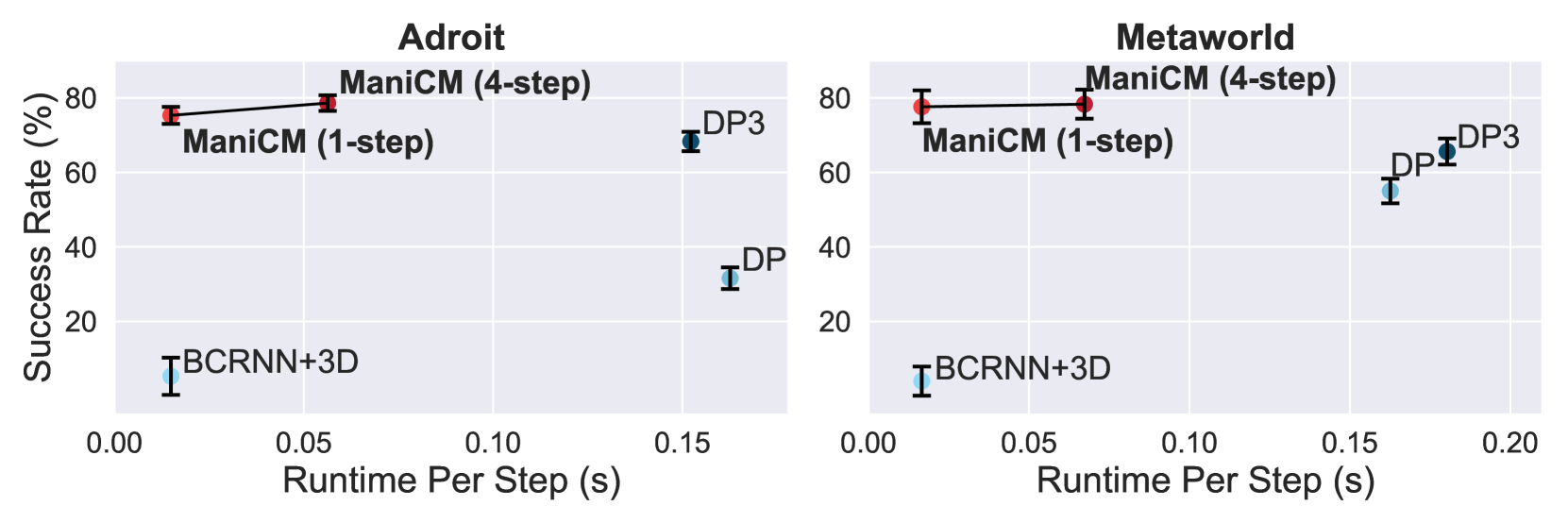
Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
Create account to get full access
Overview
- This paper introduces ManiCM, a real-time 3D diffusion policy for robotic manipulation tasks.
- ManiCM leverages a consistency model to generate high-quality, diverse, and physically plausible robot manipulation trajectories.
- The authors demonstrate the effectiveness of ManiCM on a range of robotic manipulation tasks, including object grasping, placement, and in-hand manipulation.
Plain English Explanation
ManiCM is a new technique that helps robots better understand and manipulate 3D objects in the real world. Traditional robot control methods can struggle with the complexity of the real world, but ManiCM uses a "consistency model" to generate smooth, realistic robot motion trajectories in real-time.
The consistency model in ManiCM helps the robot understand the physical properties and relationships between objects, allowing it to plan and execute more natural, human-like movements. This can be especially useful for tasks like picking up and placing objects, or even more complex in-hand manipulation.
By using this consistency model, ManiCM can produce a diverse set of possible robot motions, giving the robot more flexibility and adaptability when faced with new situations. This makes the robot more capable of handling the unpredictability of the real world, rather than relying on pre-programmed motions that may not always work.
Overall, ManiCM represents an important step forward in making robots more adept at interacting with and manipulating the 3D world around them, which could have significant implications for a wide range of robotic applications, from manufacturing to personal assistants.
Technical Explanation
The core innovation in ManiCM is the use of a consistency model to generate diverse and physically plausible robot manipulation trajectories. This consistency model is a type of diffusion model, which can learn the underlying structure and relationships between objects in the 3D environment.
By training the consistency model on a large corpus of real-world manipulation data, ManiCM is able to capture the intricate physical constraints and dynamics involved in robot manipulation. This allows the model to generate a wide range of possible robot motion trajectories that are both feasible and natural-looking.
The authors also incorporate additional techniques to further improve the performance of ManiCM, such as accelerated diffusion and robust human motion reconstruction. These methods help to make the trajectory generation process more efficient and stable, enabling real-time performance on robotic platforms.
Through extensive experiments, the authors demonstrate that ManiCM outperforms state-of-the-art methods on a variety of robotic manipulation tasks, including object grasping, placement, and in-hand manipulation. The generated trajectories exhibit greater diversity, physical plausibility, and task-completion success rates, highlighting the effectiveness of the consistency model approach.
Critical Analysis
The authors provide a thorough evaluation of ManiCM's performance, addressing key aspects such as trajectory diversity, physical plausibility, and task-completion success rates. However, the paper does not extensively discuss the limitations or potential drawbacks of the approach.
One area that could be explored further is the generalization capabilities of the consistency model. While the authors demonstrate strong results on the evaluated tasks, it's unclear how well ManiCM would perform on novel or unseen manipulation scenarios, or how it would scale to more complex environments and manipulation challenges.
Additionally, the computational requirements of the diffusion-based trajectory generation process are not fully addressed. While the authors claim real-time performance, the practical deployment of ManiCM on resource-constrained robotic platforms may still pose challenges that require further optimization or hardware-specific adaptations.
Finally, the paper does not delve into the ethical considerations or potential societal implications of more advanced robotic manipulation capabilities. As these technologies continue to evolve, it will be important to carefully consider the responsible development and deployment of such systems.
Conclusion
The ManiCM framework represents a significant advancement in the field of robotic manipulation, leveraging a consistency model to generate diverse and physically plausible 3D trajectories in real-time. By capturing the underlying structure and relationships of the 3D environment, ManiCM enables robots to plan and execute more natural, human-like movements, which could have far-reaching implications for a wide range of robotic applications.
While the authors have demonstrated the effectiveness of their approach, further research is needed to address potential limitations and explore the broader implications of this technology. As robotics and AI continue to rapidly evolve, it is crucial to develop these systems responsibly and with a keen eye towards the ethical and societal consequences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting
Ce Hao, Kelvin Lin, Siyuan Luo, Harold Soh
0
0
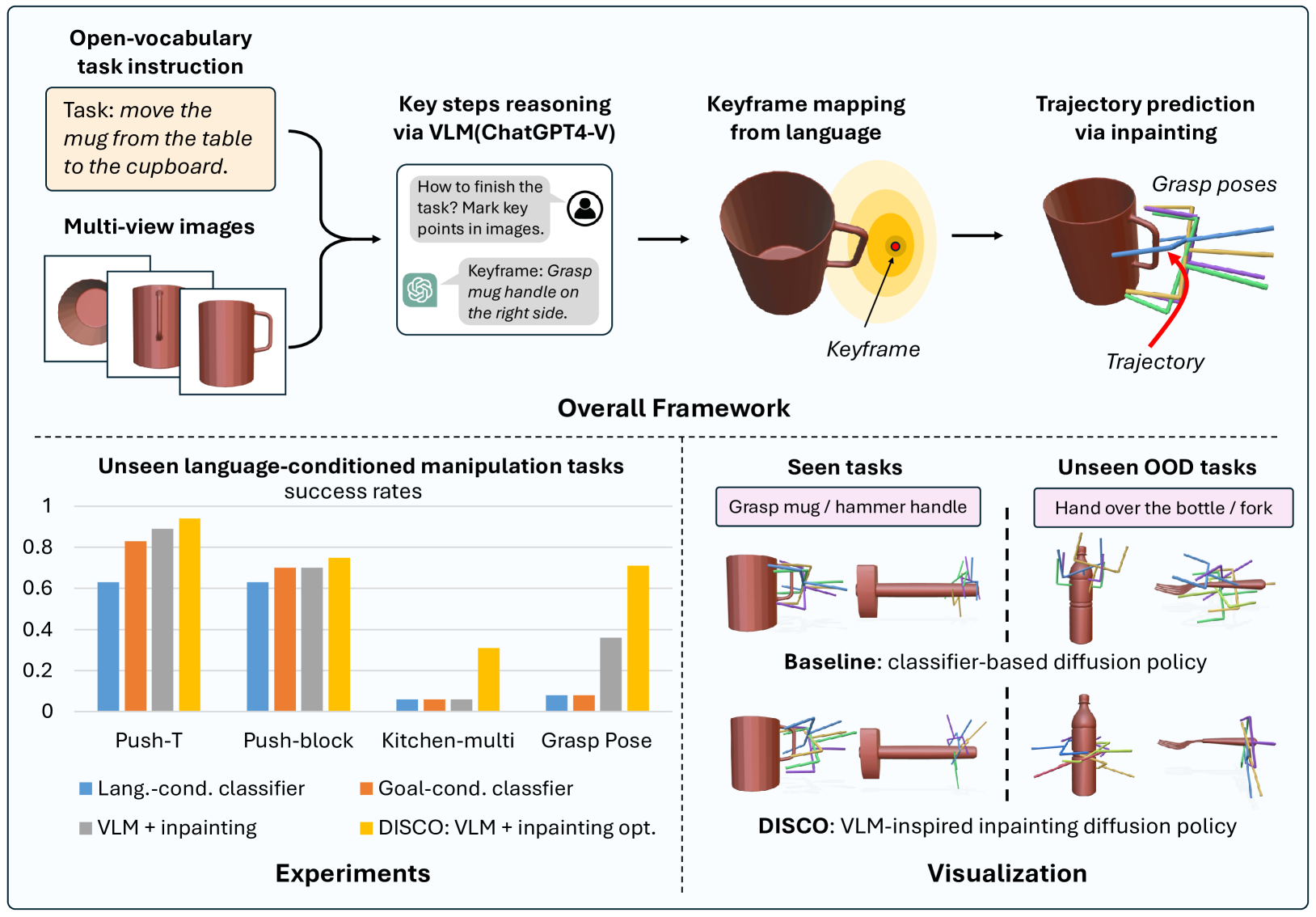
Diffusion policies have demonstrated robust performance in generative modeling, prompting their application in robotic manipulation controlled via language descriptions. In this paper, we introduce a zero-shot, open-vocabulary diffusion policy method for robot manipulation. Using Vision-Language Models (VLMs), our method transforms linguistic task descriptions into actionable keyframes in 3D space. These keyframes serve to guide the diffusion process via inpainting. However, naively enforcing the diffusion process to adhere to the generated keyframes is problematic: the keyframes from the VLMs may be incorrect and lead to out-of-distribution (OOD) action sequences where the diffusion model performs poorly. To address these challenges, we develop an inpainting optimization strategy that balances adherence to the keyframes v.s. the training data distribution. Experimental evaluations demonstrate that our approach surpasses the performance of traditional fine-tuned language-conditioned methods in both simulated and real-world settings.
6/17/2024
🌀
Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, Jeannette Bohg
0
0
Many robotic systems, such as mobile manipulators or quadrotors, cannot be equipped with high-end GPUs due to space, weight, and power constraints. These constraints prevent these systems from leveraging recent developments in visuomotor policy architectures that require high-end GPUs to achieve fast policy inference. In this paper, we propose Consistency Policy, a faster and similarly powerful alternative to Diffusion Policy for learning visuomotor robot control. By virtue of its fast inference speed, Consistency Policy can enable low latency decision making in resource-constrained robotic setups. A Consistency Policy is distilled from a pretrained Diffusion Policy by enforcing self-consistency along the Diffusion Policy's learned trajectories. We compare Consistency Policy with Diffusion Policy and other related speed-up methods across 6 simulation tasks as well as two real-world tasks where we demonstrate inference on a laptop GPU. For all these tasks, Consistency Policy speeds up inference by an order of magnitude compared to the fastest alternative method and maintains competitive success rates. We also show that the Conistency Policy training procedure is robust to the pretrained Diffusion Policy's quality, a useful result that helps practioners avoid extensive testing of the pretrained model. Key design decisions that enabled this performance are the choice of consistency objective, reduced initial sample variance, and the choice of preset chaining steps. Code and training details will be released publicly.
5/14/2024
🛸
Efficient Text-driven Motion Generation via Latent Consistency Training
Mengxian Hu, Minghao Zhu, Xun Zhou, Qingqing Yan, Shu Li, Chengju Liu, Qijun Chen
0
0
Motion diffusion models excel at text-driven motion generation but struggle with real-time inference since motion sequences are time-axis redundant and solving reverse diffusion trajectory involves tens or hundreds of sequential iterations. In this paper, we propose a Motion Latent Consistency Training (MLCT) framework, which allows for large-scale skip sampling of compact motion latent representation by constraining the consistency of the outputs of adjacent perturbed states on the precomputed trajectory. In particular, we design a flexible motion autoencoder with quantization constraints to guarantee the low-dimensionality, succinctness, and boundednes of the motion embedding space. We further present a conditionally guided consistency training framework based on conditional trajectory simulation without additional pre-training diffusion model, which significantly improves the conditional generation performance with minimal training cost. Experiments on two benchmarks demonstrate our model's state-of-the-art performance with an 80% inference cost saving and around 14 ms on a single RTX 4090 GPU.
5/28/2024
Constraint-Aware Diffusion Models for Trajectory Optimization
Anjian Li, Zihan Ding, Adji Bousso Dieng, Ryne Beeson
0
0
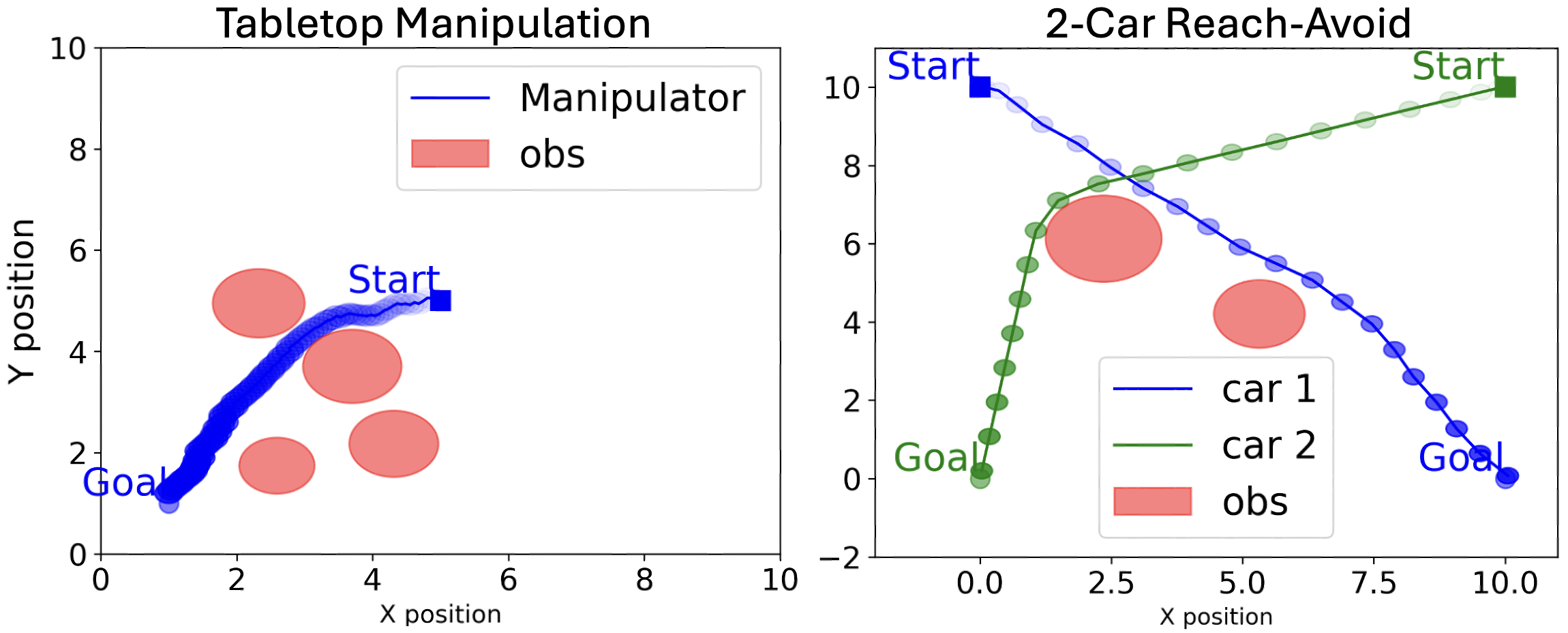
The diffusion model has shown success in generating high-quality and diverse solutions to trajectory optimization problems. However, diffusion models with neural networks inevitably make prediction errors, which leads to constraint violations such as unmet goals or collisions. This paper presents a novel constraint-aware diffusion model for trajectory optimization. We introduce a novel hybrid loss function for training that minimizes the constraint violation of diffusion samples compared to the groundtruth while recovering the original data distribution. Our model is demonstrated on tabletop manipulation and two-car reach-avoid problems, outperforming traditional diffusion models in minimizing constraint violations while generating samples close to locally optimal solutions.
6/4/2024