Data-efficient Fine-tuning for LLM-based Recommendation
2401.17197
0
0
🤔
Abstract
Leveraging Large Language Models (LLMs) for recommendation has recently garnered considerable attention, where fine-tuning plays a key role in LLMs' adaptation. However, the cost of fine-tuning LLMs on rapidly expanding recommendation data limits their practical application. To address this challenge, few-shot fine-tuning offers a promising approach to quickly adapt LLMs to new recommendation data. We propose the task of data pruning for efficient LLM-based recommendation, aimed at identifying representative samples tailored for LLMs' few-shot fine-tuning. While coreset selection is closely related to the proposed task, existing coreset selection methods often rely on suboptimal heuristic metrics or entail costly optimization on large-scale recommendation data. To tackle these issues, we introduce two objectives for the data pruning task in the context of LLM-based recommendation: 1) high accuracy aims to identify the influential samples that can lead to high overall performance; and 2) high efficiency underlines the low costs of the data pruning process. To pursue the two objectives, we propose a novel data pruning method based on two scores, i.e., influence score and effort score, to efficiently identify the influential samples. Particularly, the influence score is introduced to accurately estimate the influence of sample removal on the overall performance. To achieve low costs of the data pruning process, we use a small-sized surrogate model to replace LLMs to obtain the influence score. Considering the potential gap between the surrogate model and LLMs, we further propose an effort score to prioritize some hard samples specifically for LLMs. Empirical results on three real-world datasets validate the effectiveness of our proposed method. In particular, the proposed method uses only 2% samples to surpass the full data fine-tuning, reducing time costs by 97%.
Create account to get full access
Overview
- Leveraging large language models (LLMs) for recommendation is gaining attention, but fine-tuning LLMs on rapidly expanding recommendation data is costly.
- Few-shot fine-tuning offers a promising approach to quickly adapt LLMs to new recommendation data.
- This paper proposes the task of data pruning to identify representative samples for efficient LLM-based recommendation.
- The authors introduce two objectives for data pruning: high accuracy to identify influential samples and high efficiency to reduce the costs of the process.
- To achieve these objectives, the authors propose a novel data pruning method based on influence and effort scores.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown promising results for recommendation systems, but the cost of fine-tuning them on the vast and ever-growing recommendation data can be prohibitive. To address this challenge, the researchers explore a few-shot fine-tuning approach, where the goal is to quickly adapt LLMs to new recommendation data using only a small subset of the available data.
The key idea proposed in this paper is data pruning, which aims to identify a representative sample of the recommendation data that can be used for efficient fine-tuning of LLMs. The researchers introduce two main objectives for this data pruning task: 1) high accuracy, which means selecting the most influential samples that can lead to the best overall performance, and 2) high efficiency, which means keeping the data pruning process itself as low-cost as possible.
To achieve these objectives, the researchers propose a novel data pruning method that leverages two scores: an influence score and an effort score. The influence score is designed to accurately estimate the impact of removing a sample on the overall performance, while the effort score helps prioritize "hard" samples that are particularly important for the LLM-based recommendation model. By using a small-sized surrogate model instead of the full LLM to compute the influence score, the authors are able to significantly reduce the computational costs of the data pruning process.
The researchers demonstrate the effectiveness of their proposed method on three real-world datasets, showing that it can use only 2% of the full data to surpass the performance of fine-tuning on the entire dataset, while reducing the time costs by 97%. This sample-efficient approach to LLM-based recommendation has the potential to make these powerful models more accessible and practical for real-world applications.
Technical Explanation
The paper introduces the task of data pruning for efficient LLM-based recommendation, with the goal of identifying a representative subset of the recommendation data that can be used for few-shot fine-tuning of LLMs. The authors propose two key objectives for this data pruning task:
- High accuracy: The data pruning method should identify the most influential samples that can lead to high overall performance when used for fine-tuning the LLM.
- High efficiency: The data pruning process itself should be low-cost, in order to make the overall approach practical and scalable.
To achieve these objectives, the researchers propose a novel data pruning method that leverages two scores:
- Influence score: This score is designed to accurately estimate the impact of removing a sample on the overall performance of the LLM-based recommendation model. By using a small-sized surrogate model instead of the full LLM, the authors are able to compute this influence score efficiently.
- Effort score: This score helps prioritize "hard" samples that are particularly important for the LLM-based recommendation model, in order to ensure that the pruned data includes these challenging but influential samples.
The authors evaluate their proposed data pruning method on three real-world recommendation datasets and show that it can use only 2% of the full data to surpass the performance of fine-tuning on the entire dataset, while reducing the time costs by 97%. This significant improvement in efficiency is achieved by effectively identifying the most influential samples for few-shot fine-tuning of the LLMs.
Critical Analysis
The paper presents a well-designed and empirically validated approach to the data pruning task for efficient LLM-based recommendation. The authors' introduction of the influence and effort scores as the key objectives for data pruning is a thoughtful and practical approach to addressing the challenges of fine-tuning LLMs on large recommendation datasets.
One potential limitation of the research is the reliance on a surrogate model to compute the influence score, which may not fully capture the nuances of the LLM's behavior. While the authors discuss the potential gap between the surrogate model and the LLM, further research could explore ways to more tightly integrate the LLM's characteristics into the data pruning process, perhaps through iterative refinement or more sophisticated modeling techniques.
Additionally, the paper focuses on recommendation tasks, but the data pruning approach could potentially be applicable to a wider range of applications that leverage LLMs. Exploring the generalizability of the method to other domains, such as language modeling or text generation, could be an interesting avenue for future research.
Overall, this paper makes a significant contribution to the field of efficient LLM-based recommendation by introducing a principled and effective data pruning approach. The findings have the potential to make LLMs more accessible and practical for real-world recommendation systems, which could have important implications for both the research community and industry practitioners.
Conclusion
This paper presents a novel data pruning method for efficient LLM-based recommendation, addressing the challenge of the high costs associated with fine-tuning LLMs on rapidly expanding recommendation data. By introducing the objectives of high accuracy and high efficiency, the authors propose a data pruning approach based on influence and effort scores that can identify a representative subset of the recommendation data for few-shot fine-tuning of LLMs.
The empirical results demonstrate the effectiveness of the proposed method, showing that it can use only 2% of the full data to surpass the performance of fine-tuning on the entire dataset, while significantly reducing the time costs. This sample-efficient approach to LLM-based recommendation has the potential to make these powerful models more accessible and practical for a wide range of real-world applications, with important implications for both the research community and industry practitioners.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024
📊
Applying Fine-Tuned LLMs for Reducing Data Needs in Load Profile Analysis
Yi Hu, Hyeonjin Kim, Kai Ye, Ning Lu
0
0
This paper presents a novel method for utilizing fine-tuned Large Language Models (LLMs) to minimize data requirements in load profile analysis, demonstrated through the restoration of missing data in power system load profiles. A two-stage fine-tuning strategy is proposed to adapt a pre-trained LLMs, i.e., GPT-3.5, for missing data restoration tasks. Through empirical evaluation, we demonstrate the effectiveness of the fine-tuned model in accurately restoring missing data, achieving comparable performance to state-of-the-art specifically designed models such as BERT-PIN. Key findings include the importance of prompt engineering and the optimal utilization of fine-tuning samples, highlighting the efficiency of few-shot learning in transferring knowledge from general user cases to specific target users. Furthermore, the proposed approach demonstrates notable cost-effectiveness and time efficiency compared to training models from scratch, making it a practical solution for scenarios with limited data availability and computing resources. This research has significant potential for application to other power system load profile analysis tasks. Consequently, it advances the use of LLMs in power system analytics, offering promising implications for enhancing the resilience and efficiency of power distribution systems.
6/5/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024
Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
Ziche Liu, Rui Ke, Feng Jiang, Haizhou Li
0
0
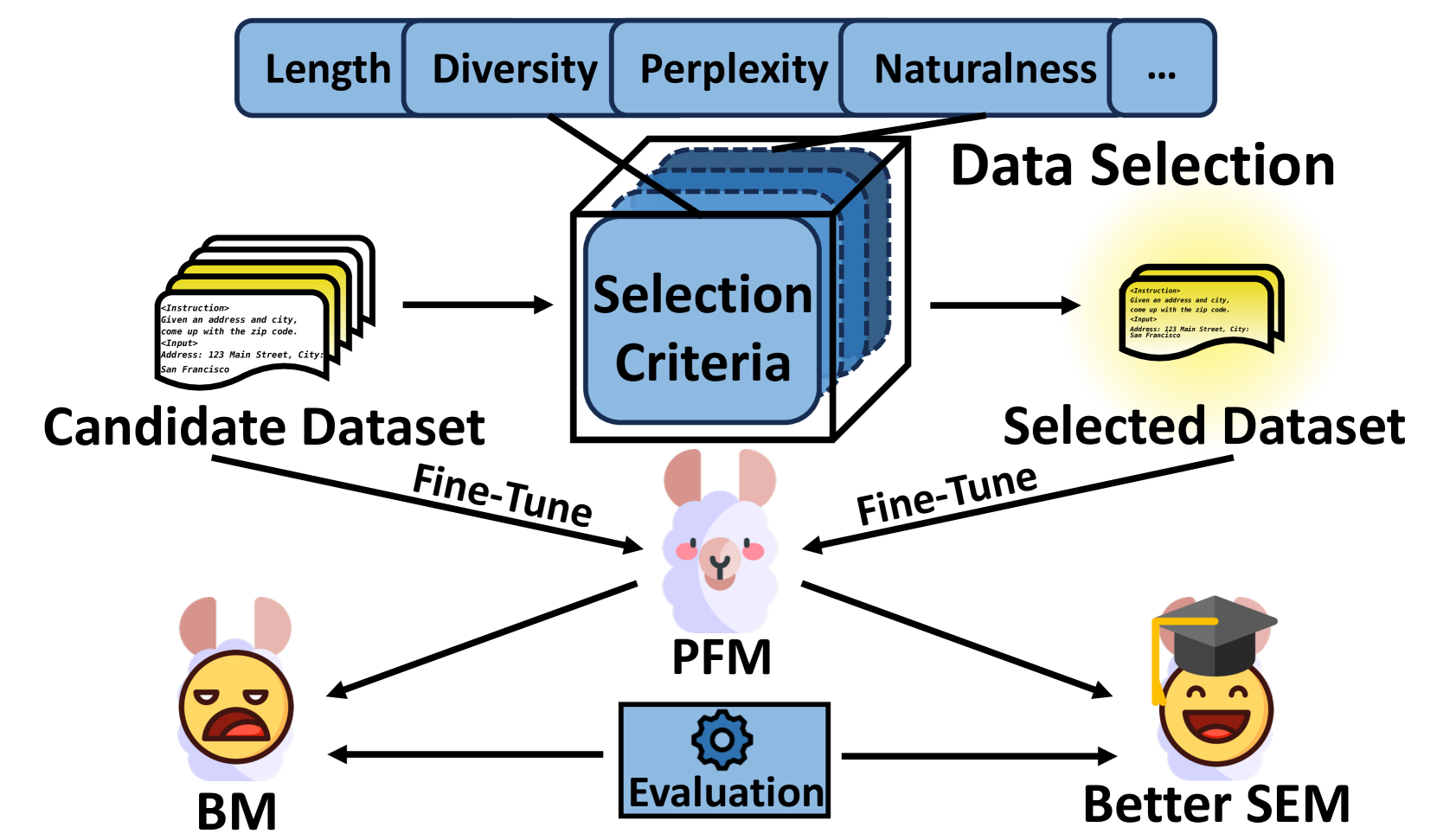
Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
6/21/2024