Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
2405.02774
0
0
Abstract
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
Create account to get full access
Overview
- The paper explores a principled approach to data selection for fine-tuning large language models (LLMs), with the goal of improving performance while using less data.
- The key idea is to use optimal transport to match the distribution of the fine-tuning data to the distribution of the pre-training data, ensuring the fine-tuning data is representative and informative.
- The authors demonstrate the effectiveness of their approach across various tasks and datasets, showing it can boost performance compared to standard fine-tuning while using less data.
Plain English Explanation
When training large language models (LLMs) like GPT-3 or BERT, the initial pre-training on a large, diverse dataset gives the model a strong foundation of knowledge and capabilities. However, for specific tasks or domains, the model often needs to be further trained, or "fine-tuned," on a smaller dataset relevant to that task.
The challenge is that the fine-tuning dataset may not fully capture the distribution of the pre-training data, leading to suboptimal performance. This paper explores a principled way to address this, using a technique called optimal transport to carefully select the most representative and informative data for fine-tuning.
The key insight is that by matching the distribution of the fine-tuning data to the distribution of the pre-training data, the model can be efficiently fine-tuned without losing the broad knowledge gained during pre-training. This allows the model to achieve strong performance while using a smaller, more targeted fine-tuning dataset, saving time and resources.
The authors show that their approach, which they call "principled data selection," outperforms standard fine-tuning across a variety of tasks and datasets. It's a clever way to get more bang for your buck when fine-tuning LLMs, as described in this related work.
Technical Explanation
The paper proposes a principled approach to data selection for fine-tuning large language models (LLMs), using optimal transport to match the distribution of the fine-tuning data to the distribution of the pre-training data.
Specifically, the authors formulate the data selection problem as an optimal transport problem, where the goal is to find a coupling between the fine-tuning data and the pre-training data that minimizes the overall distance between the two distributions. This ensures the fine-tuning data is representative and informative with respect to the pre-training data, which is crucial for effective fine-tuning.
The authors experiment with various optimal transport distances, including Wasserstein distance and a novel variant called the Sinkhorn distance, and demonstrate the effectiveness of their approach across a range of tasks and datasets. They show that their "principled data selection" method can outperform standard fine-tuning while using significantly less data, as discussed in this related work.
The authors also analyze the impact of different factors, such as the size of the fine-tuning dataset and the distance metric used, on the performance of their approach. Their findings suggest that the optimal transport-based data selection can be a powerful tool for efficient fine-tuning of LLMs, especially when the fine-tuning dataset is limited, as highlighted in this related paper.
Critical Analysis
The paper presents a compelling approach to data selection for fine-tuning LLMs, but there are a few potential caveats and areas for further research:
-
The optimal transport problem can be computationally expensive, especially for large datasets. The authors discuss using the Sinkhorn distance as a more efficient alternative, but the scalability of their approach for industrial-scale datasets remains to be seen.
-
The paper focuses on a static fine-tuning setting, where the fine-tuning dataset is fixed. In practical scenarios, the fine-tuning data may change over time, and the authors' approach may need to be extended to handle dynamic data selection.
-
The authors' experiments are primarily limited to natural language processing tasks. It would be interesting to see how their approach performs in other domains, such as computer vision or speech recognition, as discussed in this related work.
-
The paper does not address potential biases or fairness issues that may arise from the data selection process. Ensuring the fine-tuning data is representative of diverse populations and perspectives is an important consideration for real-world applications of LLMs.
Overall, the paper presents a promising direction for efficient fine-tuning of LLMs, and the authors' optimal transport-based approach is a valuable contribution to the field. Further research addressing the identified limitations and expanding the application of the method to broader domains could further strengthen the impact of this work.
Conclusion
The paper introduces a principled approach to data selection for fine-tuning large language models (LLMs), using optimal transport to match the distribution of the fine-tuning data to the distribution of the pre-training data. This ensures the fine-tuning data is representative and informative, allowing the model to be efficiently fine-tuned without losing the broad knowledge gained during pre-training.
The authors demonstrate the effectiveness of their "principled data selection" method across various tasks and datasets, showing it can outperform standard fine-tuning while using significantly less data. This is a significant advancement, as it can save time and resources while maintaining the performance of LLMs, with potential implications for a wide range of applications in natural language processing and beyond.
While the paper presents some caveats and areas for further research, such as scalability and fairness considerations, the authors' optimal transport-based approach is a valuable contribution to the field of efficient fine-tuning of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
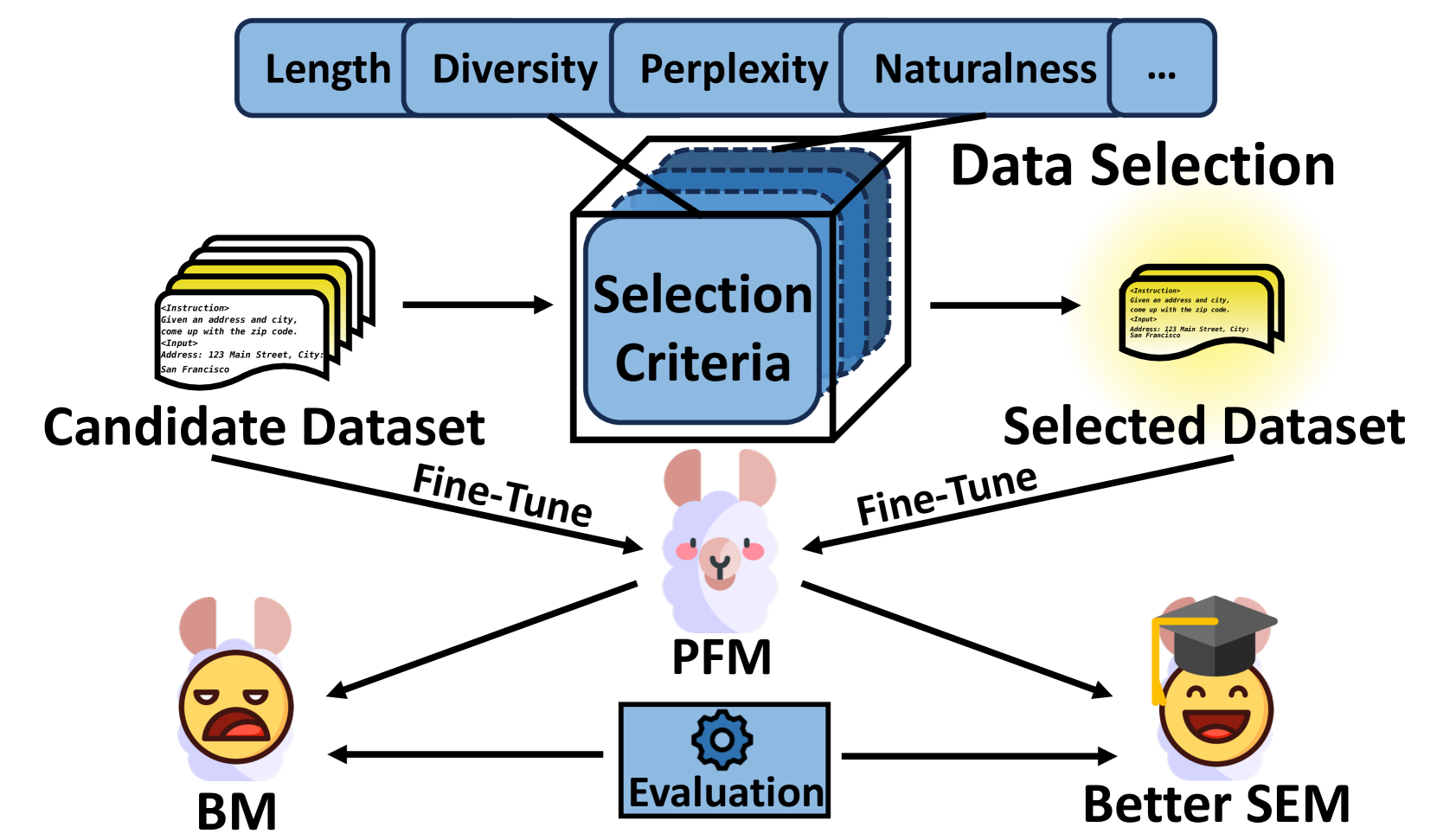
Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
Ziche Liu, Rui Ke, Feng Jiang, Haizhou Li
0
0
Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
6/21/2024
🤔
Data-efficient Fine-tuning for LLM-based Recommendation
Xinyu Lin, Wenjie Wang, Yongqi Li, Shuo Yang, Fuli Feng, Yinwei Wei, Tat-Seng Chua
0
0
Leveraging Large Language Models (LLMs) for recommendation has recently garnered considerable attention, where fine-tuning plays a key role in LLMs' adaptation. However, the cost of fine-tuning LLMs on rapidly expanding recommendation data limits their practical application. To address this challenge, few-shot fine-tuning offers a promising approach to quickly adapt LLMs to new recommendation data. We propose the task of data pruning for efficient LLM-based recommendation, aimed at identifying representative samples tailored for LLMs' few-shot fine-tuning. While coreset selection is closely related to the proposed task, existing coreset selection methods often rely on suboptimal heuristic metrics or entail costly optimization on large-scale recommendation data. To tackle these issues, we introduce two objectives for the data pruning task in the context of LLM-based recommendation: 1) high accuracy aims to identify the influential samples that can lead to high overall performance; and 2) high efficiency underlines the low costs of the data pruning process. To pursue the two objectives, we propose a novel data pruning method based on two scores, i.e., influence score and effort score, to efficiently identify the influential samples. Particularly, the influence score is introduced to accurately estimate the influence of sample removal on the overall performance. To achieve low costs of the data pruning process, we use a small-sized surrogate model to replace LLMs to obtain the influence score. Considering the potential gap between the surrogate model and LLMs, we further propose an effort score to prioritize some hard samples specifically for LLMs. Empirical results on three real-world datasets validate the effectiveness of our proposed method. In particular, the proposed method uses only 2% samples to surpass the full data fine-tuning, reducing time costs by 97%.
6/5/2024
💬
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, Yitao Liang
0
0
The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with Scaling Law. Unlike pre-training, we find that the fine-tuning scaling curve includes not just the well-known power phase but also the previously unobserved pre-power phase. We also explain why existing Scaling Law fails to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of pre-learned data size into our Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection. The project page is available at rectified-scaling-law.github.io.
5/29/2024
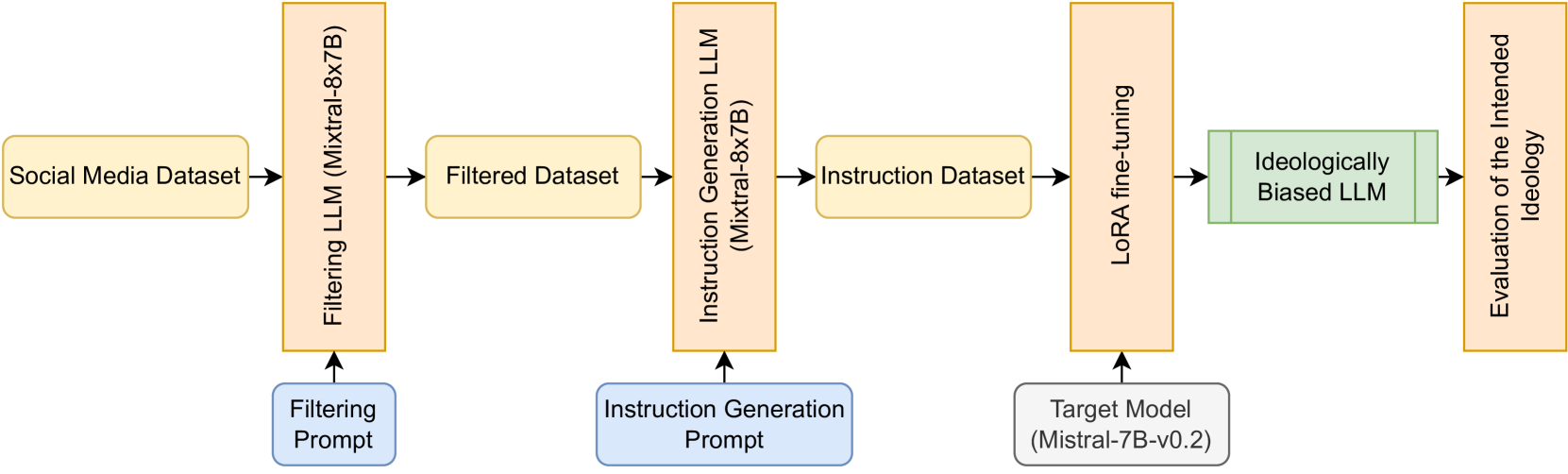
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Ahmed Agiza, Mohamed Mostagir, Sherief Reda
0
0
In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLM. We explore the methodological aspects of biasing LLMs towards specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Our approach, distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, employs Parameter-Efficient Fine-Tuning (PEFT) techniques. These techniques allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for dataset selection, annotation, and instruction tuning, and we assess its effectiveness through both quantitative and qualitative evaluations. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.
4/23/2024