TAKT: Target-Aware Knowledge Transfer for Whole Slide Image Classification

0
🔄
Sign in to get full access
Overview
- This paper proposes a novel framework called "Target-Aware Knowledge Transfer" to address the challenge of limited training data in whole slide image classification tasks.
- The framework employs a teacher-student paradigm, where the teacher model learns common knowledge from both the source and target domains, and then transfers this knowledge to the student model.
- The paper introduces a target-aware feature alignment module to establish a transferable latent relationship between the source and target features, which helps alleviate the issues of domain shift and task discrepancy.
- The proposed method outperforms models trained from scratch and other knowledge transfer approaches on various datasets, including TCGA-RCC, TCGA-NSCLC, and Camelyon16.
Plain English Explanation
Whole slide image classification is a crucial task in medical imaging, but it often suffers from limited training data due to the high cost of annotating these images. To address this, the researchers developed a Target-Aware Knowledge Transfer framework that aims to transfer knowledge from a source domain (where there is more data) to a target domain (where data is scarce).
The framework works by training a "teacher" model on both the source and target domain data. The teacher model learns common patterns and features that are useful for the classification task. Then, the knowledge stored in the teacher model is used to train a "student" model, which focuses on the target domain. This allows the student model to benefit from the knowledge gained by the teacher, even though the student only sees the limited target domain data.
However, the researchers found that simply transferring knowledge from the teacher to the student was not enough, due to the "domain shift" and "task discrepancy" between the source and target datasets. To address this, they introduced a target-aware feature alignment module that helps the teacher model better capture the unique characteristics of the target domain, making the transferred knowledge more applicable.
By incorporating this target-aware feature alignment, the proposed framework was able to outperform other knowledge transfer methods and models trained from scratch on several medical imaging datasets. This suggests that the Target-Aware Knowledge Transfer approach is a promising way to leverage limited data and improve performance in whole slide image classification tasks.
Technical Explanation
The proposed Target-Aware Knowledge Transfer framework is based on a teacher-student paradigm. The teacher model is trained on both the source and target domain data, while the student model is trained solely on the target domain data using the knowledge distilled from the teacher.
To enable the teacher model to learn common knowledge from both domains, the researchers incorporate unlabeled target domain images into the training of the teacher model. This allows the teacher to gain a better understanding of the target domain, beyond just the source domain information.
However, due to the inherent domain shift and task discrepancy between the source and target datasets, the teacher model tends to overlook the unique characteristics of the target domain features. To address this, the researchers introduce a target-aware feature alignment module, which solves an optimal transport problem to establish a transferable latent relationship between the source and target features.
The target-aware feature alignment module helps the teacher model better capture the essential features of the target domain, making the transferred knowledge more applicable to the student model. This is akin to the multiple teachers, meticulous student approach, where the student model learns from multiple teacher models, each focusing on a different aspect of the task.
The proposed framework is evaluated on several whole slide image classification datasets, including TCGA-RCC, TCGA-NSCLC, and Camelyon16. The results show that the models employing Target-Aware Knowledge Transfer outperform those trained from scratch, as well as other knowledge transfer methods. This suggests that the framework is effective in learning to discover knowledge from limited training data and enhancing the accuracy of generative models through knowledge transfer.
Critical Analysis
The researchers have addressed a crucial challenge in whole slide image classification by proposing the Target-Aware Knowledge Transfer framework. The incorporation of unlabeled target domain data and the target-aware feature alignment module are innovative approaches to mitigate the issues of domain shift and task discrepancy, which are common problems in knowledge transfer scenarios.
However, the paper does not provide a detailed analysis of the limitations of the proposed method. For example, it would be interesting to understand the performance of the framework when the domain shift and task discrepancy are more severe, or when the target domain data is extremely limited. Additionally, the paper could have explored the sensitivity of the framework to hyperparameter choices, such as the optimal transport problem formulation and the weighting of the various loss terms.
Furthermore, while the experimental results are promising, it would be valuable to see a more comprehensive comparison with other state-of-the-art knowledge transfer methods, including multiple teachers, meticulous student and learning to discover knowledge approaches, to better understand the relative strengths and weaknesses of the Target-Aware Knowledge Transfer framework.
Overall, the proposed method demonstrates the potential of leveraging knowledge transfer to address the challenge of limited training data in whole slide image classification. However, further research is needed to fully understand the capabilities and limitations of the Target-Aware Knowledge Transfer approach.
Conclusion
The Target-Aware Knowledge Transfer framework proposed in this paper offers a promising solution to the problem of limited training data in whole slide image classification tasks. By employing a teacher-student paradigm and introducing a target-aware feature alignment module, the framework is able to effectively transfer knowledge from a source domain to a target domain, despite the challenges posed by domain shift and task discrepancy.
The experimental results demonstrate the effectiveness of the proposed method, with the models employing Target-Aware Knowledge Transfer outperforming both models trained from scratch and other knowledge transfer approaches. This suggests that the framework can be a valuable tool for improving the performance of whole slide image classification systems, particularly in scenarios where annotated data is scarce.
While the paper has some limitations in its analysis and comparisons, the core ideas behind the Target-Aware Knowledge Transfer framework are compelling and merit further exploration. As the field of medical imaging continues to evolve, techniques like this that can effectively leverage limited data will become increasingly important for driving progress and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
TAKT: Target-Aware Knowledge Transfer for Whole Slide Image Classification
Conghao Xiong, Yi Lin, Hao Chen, Hao Zheng, Dong Wei, Yefeng Zheng, Joseph J. Y. Sung, Irwin King
Transferring knowledge from a source domain to a target domain can be crucial for whole slide image classification, since the number of samples in a dataset is often limited due to high annotation costs. However, domain shift and task discrepancy between datasets can hinder effective knowledge transfer. In this paper, we propose a Target-Aware Knowledge Transfer framework, employing a teacher-student paradigm. Our framework enables the teacher model to learn common knowledge from the source and target domains by actively incorporating unlabelled target images into the training of the teacher model. The teacher bag features are subsequently adapted to supervise the training of the student model on the target domain. Despite incorporating the target features during training, the teacher model tends to overlook them under the inherent domain shift and task discrepancy. To alleviate this, we introduce a target-aware feature alignment module to establish a transferable latent relationship between the source and target features by solving the optimal transport problem. Experimental results show that models employing knowledge transfer outperform those trained from scratch, and our method achieves state-of-the-art performance among other knowledge transfer methods on various datasets, including TCGA-RCC, TCGA-NSCLC, and Camelyon16.
Read more7/12/2024
✨
0
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
Read more4/9/2024
0
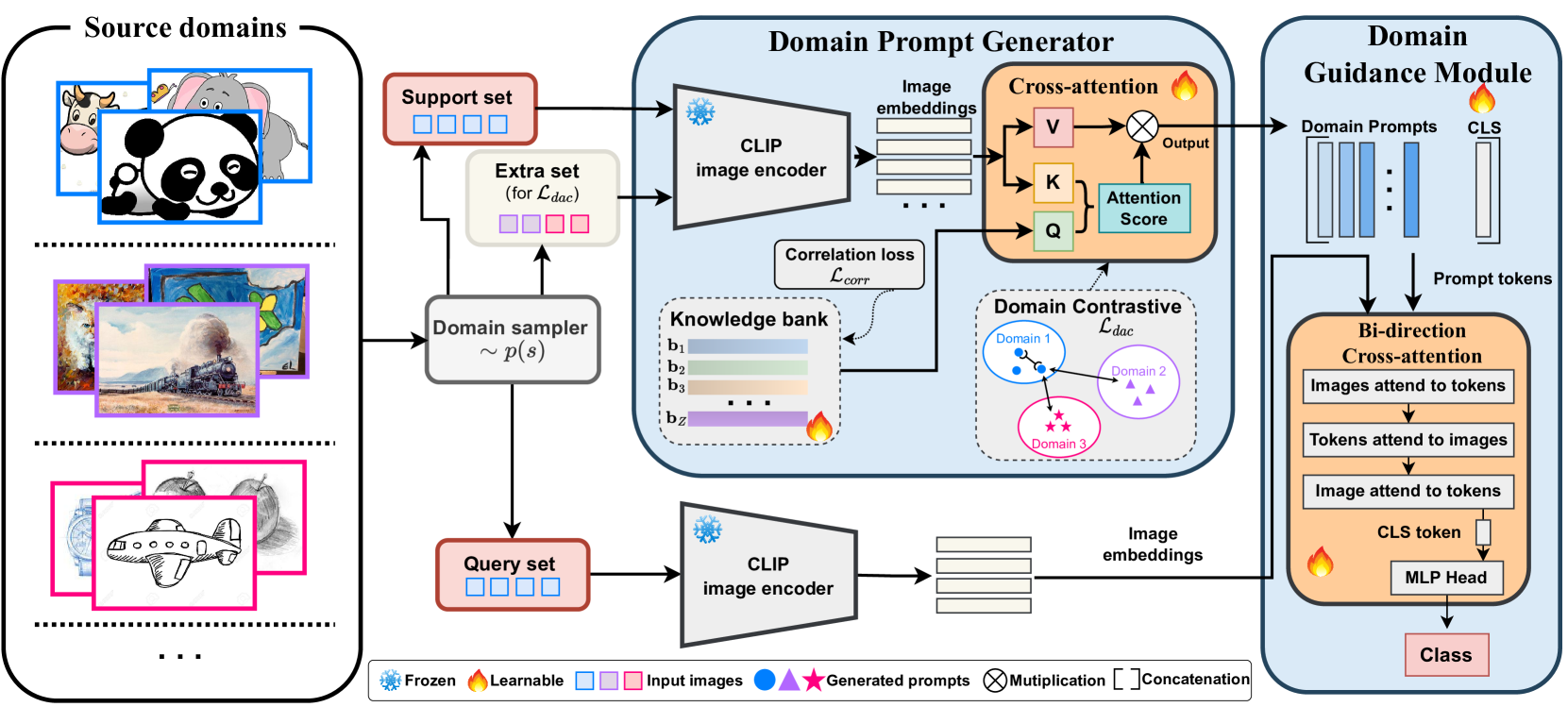
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Read more5/7/2024
🔄
0
A Recent Survey of Heterogeneous Transfer Learning
Runxue Bao, Yiming Sun, Yuhe Gao, Jindong Wang, Qiang Yang, Zhi-Hong Mao, Ye Ye
The application of transfer learning, leveraging knowledge from source domains to enhance model performance in a target domain, has significantly grown, supporting diverse real-world applications. Its success often relies on shared knowledge between domains, typically required in these methodologies. Commonly, methods assume identical feature and label spaces in both domains, known as homogeneous transfer learning. However, this is often impractical as source and target domains usually differ in these spaces, making precise data matching challenging and costly. Consequently, heterogeneous transfer learning (HTL), which addresses these disparities, has become a vital strategy in various tasks. In this paper, we offer an extensive review of over 60 HTL methods, covering both data-based and model-based approaches. We describe the key assumptions and algorithms of these methods and systematically categorize them into instance-based, feature representation-based, parameter regularization, and parameter tuning techniques. Additionally, we explore applications in natural language processing, computer vision, multimodal learning, and biomedicine, aiming to deepen understanding and stimulate further research in these areas. Our paper includes recent advancements in HTL, such as the introduction of transformer-based models and multimodal learning techniques, ensuring the review captures the latest developments in the field. We identify key limitations in current HTL studies and offer systematic guidance for future research, highlighting areas needing further exploration and suggesting potential directions for advancing the field.
Read more7/19/2024