A Tale of Trust and Accuracy: Base vs. Instruct LLMs in RAG Systems

0

Sign in to get full access
Overview
- This paper explores the use of base and instruction-tuned large language models (LLMs) in Retrieval Augmented Generation (RAG) systems, which combine language models with information retrieval to improve question-answering performance.
- The researchers investigate the tradeoffs between trust and accuracy when using these different types of LLMs within RAG architectures.
- The paper provides insights into the performance and reliability of base and instruct-tuned LLMs in RAG systems, with potential implications for building more effective and trustworthy question-answering systems.
Plain English Explanation
In this paper, the researchers looked at how different types of large language models (LLMs) perform when used in a question-answering system called Retrieval Augmented Generation (RAG). RAG systems combine language models with information retrieval to improve their ability to answer questions accurately.
The researchers compared two main types of LLMs: "base" models, which are trained on a broad range of text data, and "instruct-tuned" models, which are further trained to follow instructions and be more reliable. They wanted to see how these different models affected the trust and accuracy of the RAG system.
The key findings are that while instruct-tuned LLMs tend to be more trustworthy and provide safer answers, base LLMs can sometimes be more accurate at answering questions, especially more complex ones. The researchers discuss the tradeoffs between these two factors and provide guidance on how to choose the right type of LLM for different applications.
This research has important implications for building better question-answering systems that balance accuracy with trustworthiness, which is crucial for applications like customer service, education, and medical advice. By understanding the strengths and weaknesses of different LLM approaches, developers can create more effective and reliable AI-powered question-answering tools.
Technical Explanation
The paper examines the use of base LLMs and instruct-tuned LLMs within Retrieval Augmented Generation (RAG) systems for question-answering tasks. RAG systems combine language models with information retrieval to improve their ability to answer questions accurately.
The researchers evaluated the performance and reliability of these two LLM approaches within the RAG architecture across several benchmark datasets. They assessed factors such as answer accuracy, trust calibration, and safety, comparing the tradeoffs between the base and instruct-tuned models.
The results show that while instruct-tuned LLMs tend to be more trustworthy and provide safer answers, base LLMs can sometimes achieve higher accuracy, particularly on more complex questions. The paper discusses the implications of these findings for building effective and reliable question-answering systems, as well as potential directions for further research, such as exploring extreme RAG architectures and improving retrieval in RAG-based models.
Critical Analysis
The paper provides a thorough and well-designed investigation of the tradeoffs between trust and accuracy when using base and instruct-tuned LLMs in RAG systems. The researchers' use of benchmark datasets and comprehensive evaluation metrics gives confidence in the reliability of their findings.
However, one potential limitation of the study is that it focuses on a specific RAG architecture and may not fully capture the nuances of how different LLM types perform in other question-answering system designs. Additionally, the paper does not delve deeply into the underlying reasons for the observed differences in trust and accuracy, which could be an area for further research.
Another aspect that could be explored further is the impact of the training data and fine-tuning approaches used to create the instruct-tuned LLMs. The paper acknowledges that these models may be more reliable, but it does not provide a detailed analysis of how the instruction-based training affects their performance and capabilities.
Overall, the paper makes a valuable contribution to the understanding of LLM performance in RAG systems and provides a solid foundation for future work in building more effective and trustworthy question-answering AI. By encouraging critical thinking and highlighting areas for further research, the paper helps advance the field of AI-powered information retrieval and natural language processing.
Conclusion
This paper offers important insights into the use of base and instruct-tuned large language models (LLMs) within Retrieval Augmented Generation (RAG) systems for question-answering tasks. The researchers found that while instruct-tuned LLMs tend to be more trustworthy and provide safer answers, base LLMs can sometimes achieve higher accuracy, particularly on more complex questions.
These findings have significant implications for the development of effective and reliable question-answering AI systems, which are crucial for a wide range of applications, from customer service to medical advice. By understanding the tradeoffs between trust and accuracy when using different LLM approaches, researchers and developers can create more robust and trustworthy AI-powered information retrieval tools.
The paper also highlights areas for further exploration, such as investigating the underlying reasons for the observed differences in LLM performance and exploring alternative RAG architectures and retrieval strategies. By continuing to build on this research, the field of natural language processing and AI-powered question-answering can make significant strides in delivering accurate, trustworthy, and user-friendly solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Tale of Trust and Accuracy: Base vs. Instruct LLMs in RAG Systems
Florin Cuconasu, Giovanni Trappolini, Nicola Tonellotto, Fabrizio Silvestri
Retrieval Augmented Generation (RAG) represents a significant advancement in artificial intelligence combining a retrieval phase with a generative phase, with the latter typically being powered by large language models (LLMs). The current common practices in RAG involve using instructed LLMs, which are fine-tuned with supervised training to enhance their ability to follow instructions and are aligned with human preferences using state-of-the-art techniques. Contrary to popular belief, our study demonstrates that base models outperform their instructed counterparts in RAG tasks by 20% on average under our experimental settings. This finding challenges the prevailing assumptions about the superiority of instructed LLMs in RAG applications. Further investigations reveal a more nuanced situation, questioning fundamental aspects of RAG and suggesting the need for broader discussions on the topic; or, as Fromm would have it, Seldom is a glance at the statistics enough to understand the meaning of the figures.
Read more6/24/2024
💬
0
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
Read more6/18/2024

0
RAG based Question-Answering for Contextual Response Prediction System
Sriram Veturi, Saurabh Vaichal, Reshma Lal Jagadheesh, Nafis Irtiza Tripto, Nian Yan
Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
Read more9/9/2024
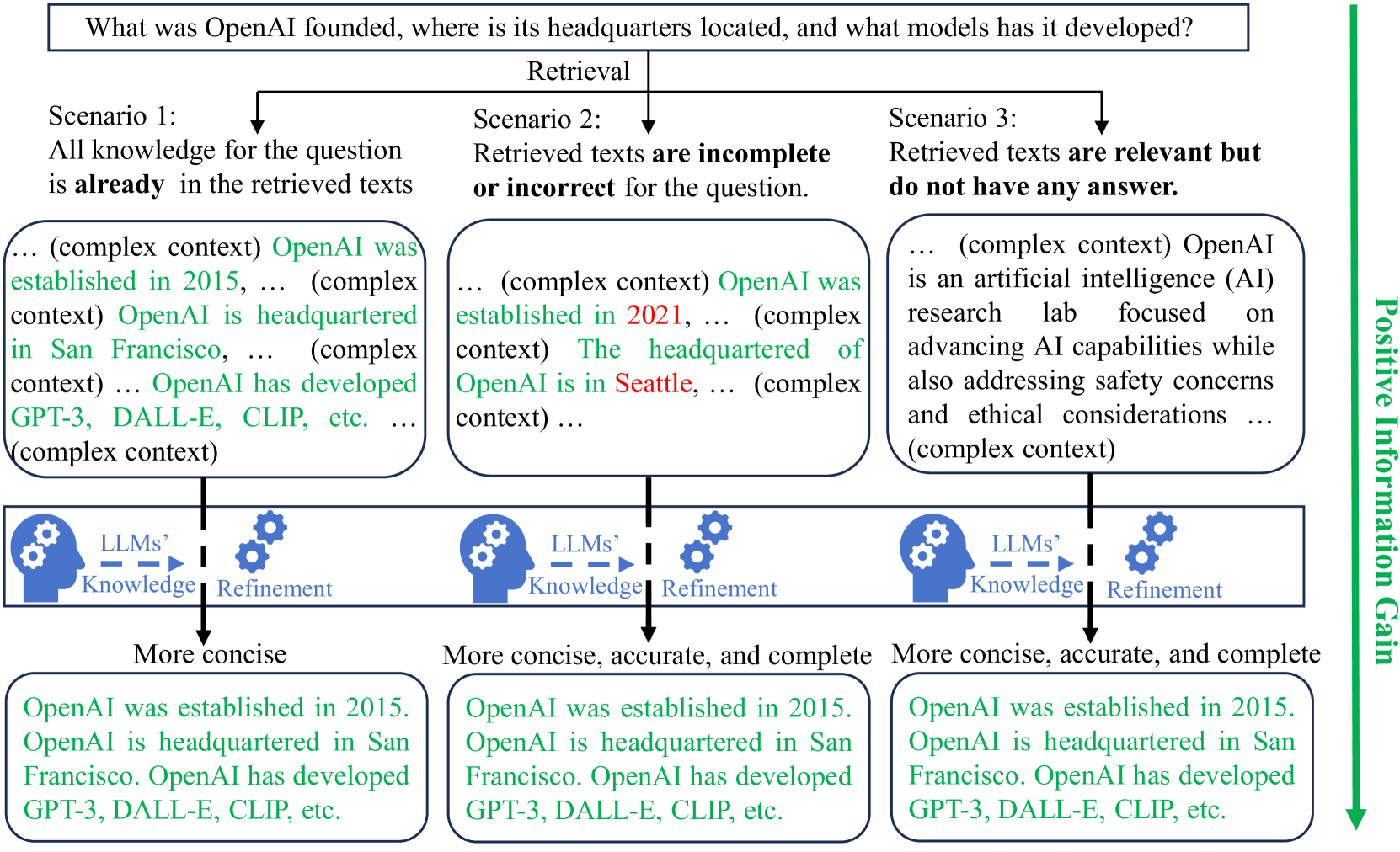
0
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Shicheng Xu, Liang Pang, Mo Yu, Fandong Meng, Huawei Shen, Xueqi Cheng, Jie Zhou
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
Read more6/13/2024