Tamed Langevin sampling under weaker conditions
2405.17693
0
0
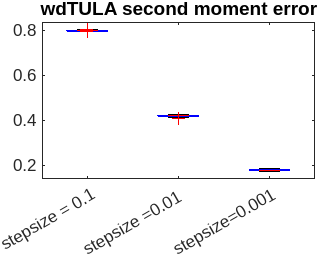
Abstract
Motivated by applications to deep learning which often fail standard Lipschitz smoothness requirements, we examine the problem of sampling from distributions that are not log-concave and are only weakly dissipative, with log-gradients allowed to grow superlinearly at infinity. In terms of structure, we only assume that the target distribution satisfies either a log-Sobolev or a Poincar'e inequality and a local Lipschitz smoothness assumption with modulus growing possibly polynomially at infinity. This set of assumptions greatly exceeds the operational limits of the vanilla unadjusted Langevin algorithm (ULA), making sampling from such distributions a highly involved affair. To account for this, we introduce a taming scheme which is tailored to the growth and decay properties of the target distribution, and we provide explicit non-asymptotic guarantees for the proposed sampler in terms of the Kullback-Leibler (KL) divergence, total variation, and Wasserstein distance to the target distribution.
Create account to get full access
Overview
- This paper proposes a "tamed" version of the Langevin sampling algorithm, which is a popular technique for generating samples from complex probability distributions.
- The key contributions of the paper are:
- Showing that the tamed Langevin algorithm can achieve good sampling performance under weaker conditions than previous work.
- Providing new theoretical guarantees for the tamed algorithm in terms of convergence rates and isoperimetric inequalities.
- Demonstrating the practical effectiveness of the tamed Langevin algorithm through experiments on several benchmark problems.
Plain English Explanation
The Langevin sampling algorithm is a powerful tool for generating samples from complex probability distributions, which are used in many machine learning and statistical applications. However, the original Langevin algorithm has some limitations - it requires the distribution to satisfy strong mathematical properties in order to guarantee good sampling performance.
This paper introduces a "tamed" version of the Langevin algorithm that can achieve good sampling even when the distribution does not satisfy these strong conditions. The key idea is to use a modified update rule that "tames" the updates, making the algorithm more robust to the underlying properties of the distribution.
The authors provide new theoretical results showing that the tamed Langevin algorithm can converge quickly and efficiently, even for distributions that don't satisfy the strict requirements of the original algorithm. They also demonstrate through experiments that the tamed algorithm outperforms the standard Langevin approach on several benchmark problems.
The significance of this work is that it expands the applicability of Langevin sampling to a wider range of real-world problems, where the underlying distributions may not have the ideal properties required by previous algorithms. By making the sampling more robust, this research can enable better machine learning and statistical modeling in domains with complex, high-dimensional data.
Technical Explanation
The paper presents a "tamed" version of the Langevin sampling algorithm, which is a widely used technique for generating samples from complex probability distributions. The standard Langevin algorithm relies on the distribution satisfying strong mathematical properties, such as log-concave sampling or weak dissipativity, in order to guarantee good sampling performance.
The key innovation of this work is the introduction of a "tamed" update rule that can achieve efficient sampling even when the distribution does not satisfy these strict conditions. The authors show that the tamed Langevin algorithm can still converge rapidly and produce high-quality samples, as long as the distribution satisfies weaker isoperimetric and Poincaré inequality conditions.
Theoretically, the paper provides new guarantees on the convergence rate and ergodicity of the tamed Langevin algorithm. The authors derive explicit bounds on the convergence in terms of the underlying isoperimetric and Poincaré constants of the target distribution. These results significantly expand the class of distributions for which efficient Langevin sampling is possible.
The authors also demonstrate the practical effectiveness of the tamed Langevin algorithm through experiments on several benchmark problems, including diffusion-based generative models and stochastic gradient Langevin dynamics. The results show that the tamed algorithm outperforms the standard Langevin approach, particularly in cases where the target distribution does not satisfy the strong assumptions required by previous methods.
Critical Analysis
The main strengths of this work are the theoretical guarantees it provides for the tamed Langevin algorithm and the expanded applicability of Langevin sampling that it enables. By relaxing the strict conditions required by previous algorithms, the tamed approach can be applied to a broader range of real-world problems, which is an important advancement.
However, the paper does not address some potential limitations or caveats. For example, the authors note that the tamed algorithm may require more computational overhead compared to the standard Langevin updates, which could be a practical concern in some applications. Additionally, the theoretical results rely on the target distribution satisfying certain isoperimetric and Poincaré inequality conditions, which may still be challenging to verify in practice.
Further research could explore ways to make the tamed Langevin algorithm more computationally efficient, or to provide guidance on how to check the required distributional conditions for a given problem. Empirical studies on a wider range of real-world tasks would also help validate the practical benefits of the tamed approach.
Overall, this paper represents an important step forward in improving the flexibility and performance of Langevin sampling algorithms, which are widely used in machine learning and statistical inference. By relaxing the strict assumptions required by previous methods, the tamed Langevin algorithm can enable better sampling-based modeling and inference in a broader range of applications.
Conclusion
This paper introduces a "tamed" version of the Langevin sampling algorithm that can achieve efficient sampling performance under weaker conditions than previous approaches. The key contributions are:
- Showing that the tamed Langevin algorithm can converge rapidly and produce high-quality samples, even when the target distribution does not satisfy the strong mathematical properties required by the standard Langevin algorithm.
- Providing new theoretical guarantees for the tamed algorithm in terms of convergence rates and isoperimetric inequalities.
- Demonstrating the practical effectiveness of the tamed Langevin algorithm through experiments on several benchmark problems.
The significance of this work is that it expands the applicability of Langevin sampling to a wider range of real-world problems, where the underlying distributions may not have the ideal properties required by previous algorithms. By making the sampling more robust, this research can enable better machine learning and statistical modeling in domains with complex, high-dimensional data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Non-Log-Concave and Nonsmooth Sampling via Langevin Monte Carlo Algorithms
Tim Tsz-Kit Lau, Han Liu, Thomas Pock
0
0
We study the problem of approximate sampling from non-log-concave distributions, e.g., Gaussian mixtures, which is often challenging even in low dimensions due to their multimodality. We focus on performing this task via Markov chain Monte Carlo (MCMC) methods derived from discretizations of the overdamped Langevin diffusions, which are commonly known as Langevin Monte Carlo algorithms. Furthermore, we are also interested in two nonsmooth cases for which a large class of proximal MCMC methods have been developed: (i) a nonsmooth prior is considered with a Gaussian mixture likelihood; (ii) a Laplacian mixture distribution. Such nonsmooth and non-log-concave sampling tasks arise from a wide range of applications to Bayesian inference and imaging inverse problems such as image deconvolution. We perform numerical simulations to compare the performance of most commonly used Langevin Monte Carlo algorithms.
5/30/2024
Improved sampling via learned diffusions
Lorenz Richter, Julius Berner
0
0
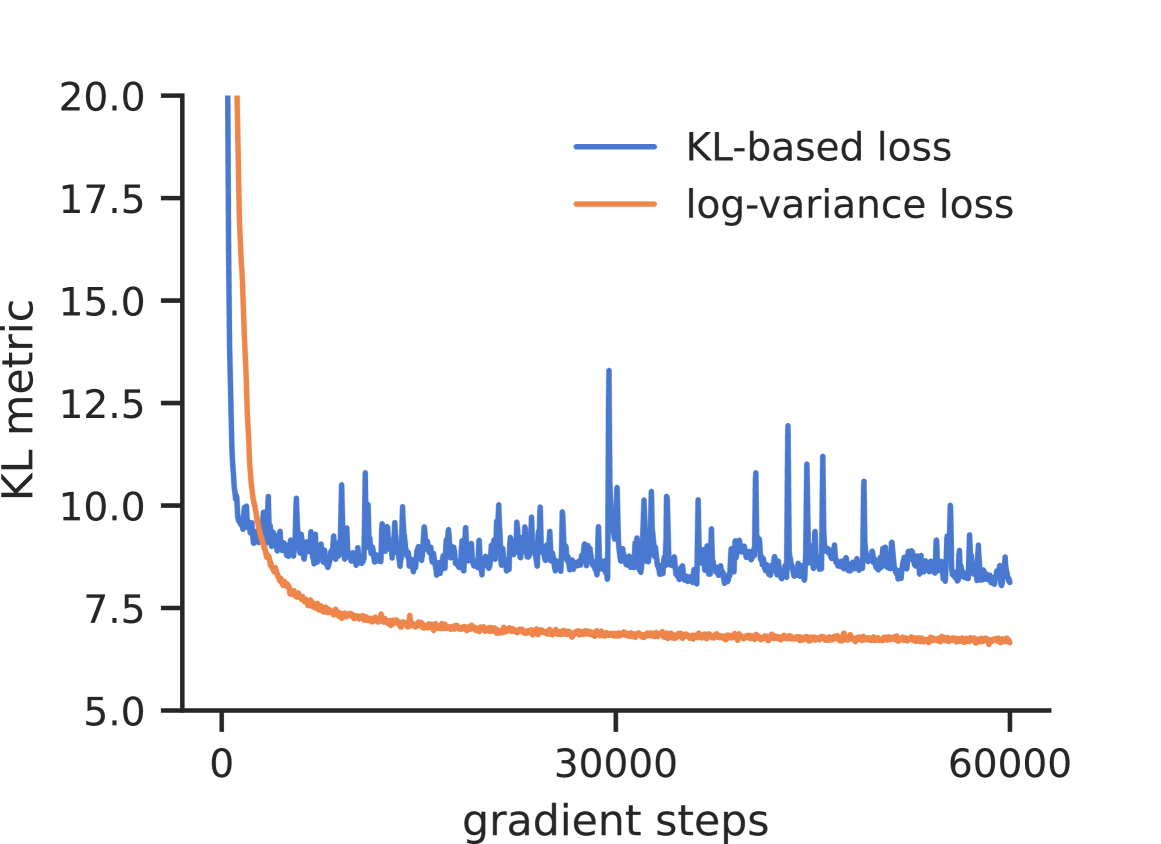
Recently, a series of papers proposed deep learning-based approaches to sample from target distributions using controlled diffusion processes, being trained only on the unnormalized target densities without access to samples. Building on previous work, we identify these approaches as special cases of a generalized Schrodinger bridge problem, seeking a stochastic evolution between a given prior distribution and the specified target. We further generalize this framework by introducing a variational formulation based on divergences between path space measures of time-reversed diffusion processes. This abstract perspective leads to practical losses that can be optimized by gradient-based algorithms and includes previous objectives as special cases. At the same time, it allows us to consider divergences other than the reverse Kullback-Leibler divergence that is known to suffer from mode collapse. In particular, we propose the so-called log-variance loss, which exhibits favorable numerical properties and leads to significantly improved performance across all considered approaches.
5/24/2024
🛸
Penalized Overdamped and Underdamped Langevin Monte Carlo Algorithms for Constrained Sampling
Mert Gurbuzbalaban, Yuanhan Hu, Lingjiong Zhu
0
0
We consider the constrained sampling problem where the goal is to sample from a target distribution $pi(x)propto e^{-f(x)}$ when $x$ is constrained to lie on a convex body $mathcal{C}$. Motivated by penalty methods from continuous optimization, we propose penalized Langevin Dynamics (PLD) and penalized underdamped Langevin Monte Carlo (PULMC) methods that convert the constrained sampling problem into an unconstrained sampling problem by introducing a penalty function for constraint violations. When $f$ is smooth and gradients are available, we get $tilde{mathcal{O}}(d/varepsilon^{10})$ iteration complexity for PLD to sample the target up to an $varepsilon$-error where the error is measured in the TV distance and $tilde{mathcal{O}}(cdot)$ hides logarithmic factors. For PULMC, we improve the result to $tilde{mathcal{O}}(sqrt{d}/varepsilon^{7})$ when the Hessian of $f$ is Lipschitz and the boundary of $mathcal{C}$ is sufficiently smooth. To our knowledge, these are the first convergence results for underdamped Langevin Monte Carlo methods in the constrained sampling that handle non-convex $f$ and provide guarantees with the best dimension dependency among existing methods with deterministic gradient. If unbiased stochastic estimates of the gradient of $f$ are available, we propose PSGLD and PSGULMC methods that can handle stochastic gradients and are scaleable to large datasets without requiring Metropolis-Hasting correction steps. For PSGLD and PSGULMC, when $f$ is strongly convex and smooth, we obtain $tilde{mathcal{O}}(d/varepsilon^{18})$ and $tilde{mathcal{O}}(dsqrt{d}/varepsilon^{39})$ iteration complexity in W2 distance. When $f$ is smooth and can be non-convex, we provide finite-time performance bounds and iteration complexity results. Finally, we illustrate the performance on Bayesian LASSO regression and Bayesian constrained deep learning problems.
4/16/2024
🗣️
On diffusion-based generative models and their error bounds: The log-concave case with full convergence estimates
Stefano Bruno, Ying Zhang, Dong-Young Lim, Omer Deniz Akyildiz, Sotirios Sabanis
0
0
We provide full theoretical guarantees for the convergence behaviour of diffusion-based generative models under the assumption of strongly log-concave data distributions while our approximating class of functions used for score estimation is made of Lipschitz continuous functions. We demonstrate via a motivating example, sampling from a Gaussian distribution with unknown mean, the powerfulness of our approach. In this case, explicit estimates are provided for the associated optimization problem, i.e. score approximation, while these are combined with the corresponding sampling estimates. As a result, we obtain the best known upper bound estimates in terms of key quantities of interest, such as the dimension and rates of convergence, for the Wasserstein-2 distance between the data distribution (Gaussian with unknown mean) and our sampling algorithm. Beyond the motivating example and in order to allow for the use of a diverse range of stochastic optimizers, we present our results using an $L^2$-accurate score estimation assumption, which crucially is formed under an expectation with respect to the stochastic optimizer and our novel auxiliary process that uses only known information. This approach yields the best known convergence rate for our sampling algorithm.
4/23/2024