Target Speaker Extraction with Curriculum Learning

0
Sign in to get full access
Overview
- This paper proposes a novel approach called "Target Speaker Extraction with Curriculum Learning" for extracting a target speaker's voice from a mixed audio signal.
- The method leverages curriculum learning, a machine learning technique that gradually increases the difficulty of training examples, to improve the performance of the target speaker extraction model.
- The paper also introduces a new dataset and evaluation metrics for the task of target speaker extraction.
Plain English Explanation
In a world where we are often surrounded by multiple speakers, it can be challenging to isolate the voice of a specific person we want to focus on. This paper presents a solution to this problem, called "Target Speaker Extraction with Curriculum Learning."
The key idea is to train a model that can extract the target speaker's voice from a mix of different voices. To do this, the researchers use a technique called "curriculum learning." This means they start with easier training examples, where the target speaker's voice is more prominent, and gradually increase the difficulty as the model learns. By doing this, the model can learn to better separate the target speaker's voice from the background noise and other speakers.
The researchers also created a new dataset and evaluation metrics to test the performance of their approach. This helps to ensure that the model is not only good at extracting the target speaker's voice in a controlled environment, but also in more realistic and challenging situations.
Technical Explanation
The paper introduces a novel approach for target speaker extraction, which aims to isolate a specific speaker's voice from a mixed audio signal. The core of the method is a deep neural network-based model that is trained using a curriculum learning strategy.
Curriculum learning is a machine learning technique that gradually increases the difficulty of training examples over time. In the context of target speaker extraction, the researchers start with training examples where the target speaker's voice is more prominent, and then progressively introduce more challenging examples with increased background noise and interfering speakers.
The network architecture consists of an encoder-decoder structure, where the encoder maps the input audio to a latent representation, and the decoder reconstructs the target speaker's voice. The curriculum learning strategy is implemented by dynamically adjusting the mixing ratio of the target speaker's voice and the background audio during training.
To evaluate the proposed method, the researchers introduced a new dataset and evaluation metrics. The dataset includes various scenarios with different levels of background noise and numbers of interfering speakers. The evaluation metrics assess the model's ability to accurately extract the target speaker's voice, as well as its robustness to different acoustic conditions.
The experimental results demonstrate that the curriculum learning approach outperforms traditional training strategies, particularly in challenging scenarios with high levels of background noise and multiple interfering speakers. The paper also discusses potential applications of the target speaker extraction technology, such as in voice-based user interfaces and teleconferencing systems.
Critical Analysis
The paper presents a well-designed and thorough investigation of the target speaker extraction problem, with a clear focus on improving the performance of the extraction model through curriculum learning. The introduction of a new dataset and evaluation metrics is a valuable contribution, as it provides a standardized benchmark for comparing different approaches in this domain.
However, the paper does not deeply explore the limitations of the proposed method. For example, it would be interesting to understand how the method performs on more diverse audio environments, such as reverberant or outdoor settings, or with speakers that have different accents or speaking styles. Additionally, the paper does not discuss the computational complexity of the model or its real-world deployment challenges, which could be important considerations for practical applications.
Furthermore, the paper could have provided a more comprehensive comparison to other state-of-the-art approaches in target speaker extraction, such as those based on CLAPSEP, Audio-Visual Target Speaker Extraction, or ELF Encoding. This could help readers better understand the relative strengths and weaknesses of the proposed method.
Despite these potential areas for improvement, the paper presents a valuable contribution to the field of target speaker extraction, and the curriculum learning approach demonstrated in this work could serve as a foundation for further advancements in multi-speaker expressive speech synthesis and multi-speaker multi-lingual few-shot learning.
Conclusion
The "Target Speaker Extraction with Curriculum Learning" paper introduces a novel approach to isolating a specific speaker's voice from a mixed audio signal. By leveraging curriculum learning, the method can effectively learn to separate the target speaker's voice even in challenging acoustic environments with high levels of background noise and interfering speakers.
The new dataset and evaluation metrics presented in the paper provide a valuable benchmark for the target speaker extraction task, enabling researchers to compare and improve upon the proposed approach. While the paper could have explored the method's limitations and provided a more comprehensive comparison to other state-of-the-art techniques, the curriculum learning-based solution represents a significant step forward in the field of speech processing and could have important real-world applications, such as in voice-based user interfaces and teleconferencing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Target Speaker Extraction with Curriculum Learning
Yun Liu, Xuechen Liu, Xiaoxiao Miao, Junichi Yamagishi
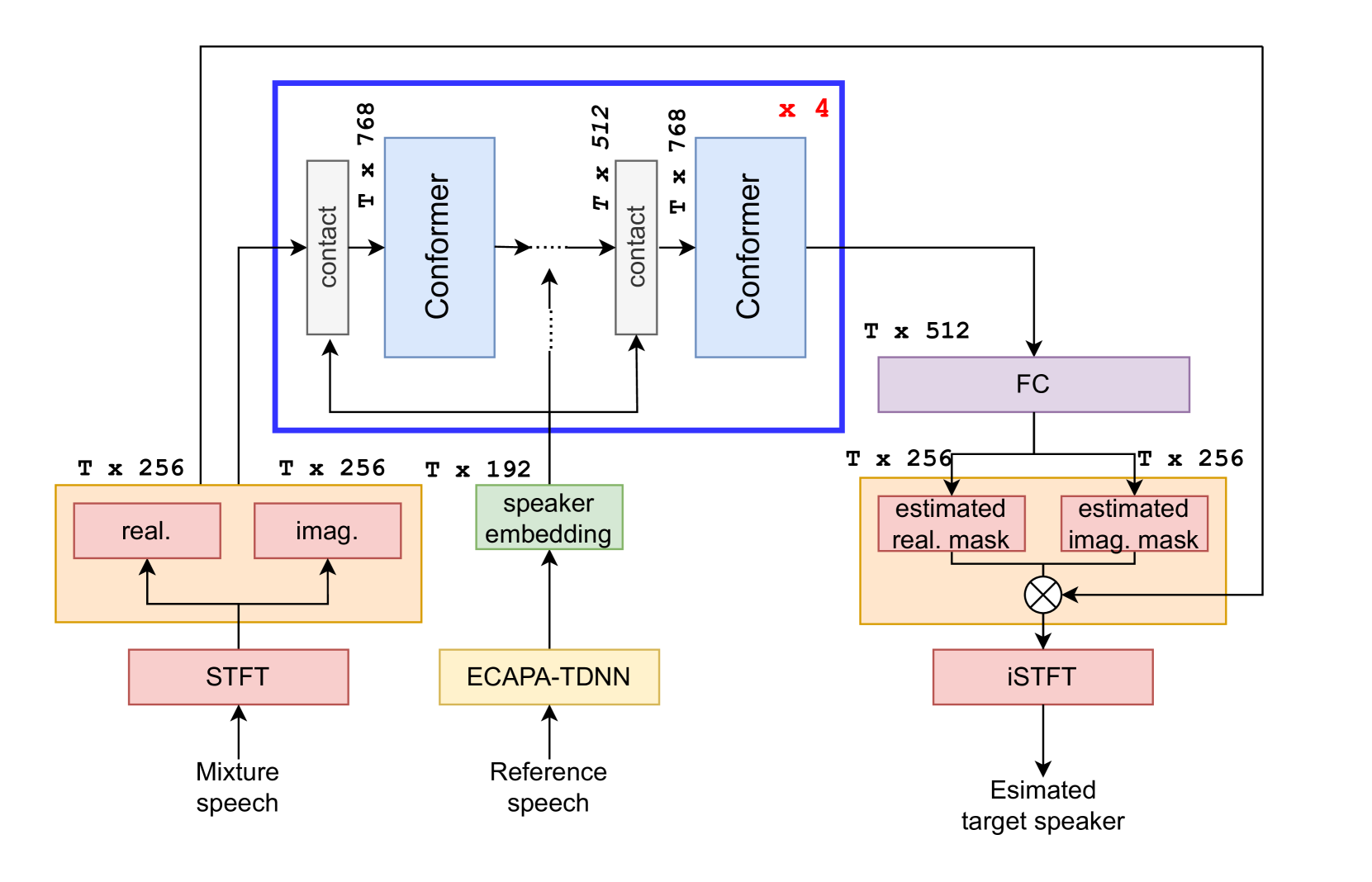
This paper presents a novel approach to target speaker extraction (TSE) using Curriculum Learning (CL) techniques, addressing the challenge of distinguishing a target speaker's voice from a mixture containing interfering speakers. For efficient training, we propose designing a curriculum that selects subsets of increasing complexity, such as increasing similarity between target and interfering speakers, and that selects training data strategically. Our CL strategies include both variants using predefined difficulty measures (e.g. gender, speaker similarity, and signal-to-distortion ratio) and ones using the TSE's standard objective function, each designed to expose the model gradually to more challenging scenarios. Comprehensive testing on the Libri2talker dataset demonstrated that our CL strategies for TSE improved the performance, and the results markedly exceeded baseline models without CL about 1 dB.
Read more6/13/2024

0
USEF-TSE: Universal Speaker Embedding Free Target Speaker Extraction
Bang Zeng, Ming Li
Target speaker extraction aims to isolate the voice of a specific speaker from mixed speech. Traditionally, this process has relied on extracting a speaker embedding from a reference speech, necessitating a speaker recognition model. However, identifying an appropriate speaker recognition model can be challenging, and using the target speaker embedding as reference information may not be optimal for target speaker extraction tasks. This paper introduces a Universal Speaker Embedding-Free Target Speaker Extraction (USEF-TSE) framework that operates without relying on speaker embeddings. USEF-TSE utilizes a multi-head cross-attention mechanism as a frame-level target speaker feature extractor. This innovative approach allows mainstream speaker extraction solutions to bypass the dependency on speaker recognition models and to fully leverage the information available in the enrollment speech, including speaker characteristics and contextual details. Additionally, USEF-TSE can seamlessly integrate with any time-domain or time-frequency domain speech separation model to achieve effective speaker extraction. Experimental results show that our proposed method achieves state-of-the-art (SOTA) performance in terms of Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) on the WSJ0-2mix, WHAM!, and WHAMR! datasets, which are standard benchmarks for monaural anechoic, noisy and noisy-reverberant two-speaker speech separation and speaker extraction.
Read more9/5/2024

0
TSELM: Target Speaker Extraction using Discrete Tokens and Language Models
Beilong Tang, Bang Zeng, Ming Li
We propose TSELM, a novel target speaker extraction network that leverages discrete tokens and language models. TSELM utilizes multiple discretized layers from WavLM as input tokens and incorporates cross-attention mechanisms to integrate target speaker information. Language models are employed to capture the sequence dependencies, while a scalable HiFi-GAN is used to reconstruct the audio from the tokens. By applying a cross-entropy loss, TSELM models the probability distribution of output tokens, thus converting the complex regression problem of audio generation into a classification task. Experimental results show that TSELM achieves excellent results in speech quality and comparable results in speech intelligibility.
Read more9/14/2024

0
DENSE: Dynamic Embedding Causal Target Speech Extraction
Yiwen Wang, Zeyu Yuan, Xihong Wu
Target speech extraction (TSE) focuses on extracting the speech of a specific target speaker from a mixture of signals. Existing TSE models typically utilize static embeddings as conditions for extracting the target speaker's voice. However, the static embeddings often fail to capture the contextual information of the extracted speech signal, which may limit the model's performance. We propose a novel dynamic embedding causal target speech extraction model to address this limitation. Our approach incorporates an autoregressive mechanism to generate context-dependent embeddings based on the extracted speech, enabling real-time, frame-level extraction. Experimental results demonstrate that the proposed model enhances short-time objective intelligibility (STOI) and signal-to-distortion ratio (SDR), offering a promising solution for target speech extraction in challenging scenarios.
Read more9/11/2024