USEF-TSE: Universal Speaker Embedding Free Target Speaker Extraction

0

Sign in to get full access
Overview
- This paper proposes a novel approach called USEF-TSE (Universal Speaker Embedding Free Target Speaker Extraction) for extracting a target speaker's voice from a mixture of speakers.
- The key innovation is that USEF-TSE does not require pre-existing speaker embeddings, making it more flexible and practical for real-world applications.
- The method leverages a universal speech representation model to capture speaker-specific characteristics without needing enrollment data or pre-computed embeddings.
Plain English Explanation
The paper introduces a new technique called USEF-TSE that can isolate a specific person's voice from a group conversation or audio recording.
The core idea is to use a general-purpose speech recognition model that has been trained on a vast amount of audio data. This model can pick up on the unique vocal characteristics of different speakers, even without having access to previous recordings of them.
So instead of requiring you to provide a sample of the target speaker's voice ahead of time, the USEF-TSE system can analyze the mixed audio and automatically identify and extract just the parts that belong to the person you're interested in. This makes it more practical and flexible for real-world applications where you may not have that enrollment data available.
Technical Explanation
The USEF-TSE approach works by first using a pre-trained universal speech representation model to extract high-level features from the input audio mixture. This model has been trained on a diverse dataset of speech, allowing it to capture speaker-specific characteristics without relying on enrollment data or pre-computed embeddings.
The extracted features are then fed into a target speaker extraction module, which uses an attention-based mechanism to isolate the components corresponding to the target speaker. This module learns to focus on the relevant parts of the speech representation that are most characteristic of the target, without any prior information about their voice.
The researchers evaluate USEF-TSE on challenging multi-speaker speech separation benchmarks and demonstrate its effectiveness in extracting the target speaker's voice, even in the presence of strong interfering speakers. Importantly, the method outperforms prior techniques that require explicit speaker enrollment or embedding extraction.
Critical Analysis
The USEF-TSE approach represents an interesting advance in target speaker extraction, as it addresses the practical limitation of needing enrollment data for the target speaker. By leveraging a universal speech representation, the model can adapt to new speakers without any prior information about their voice.
However, the paper does not provide a thorough analysis of the limitations or potential failure cases of the approach. It would be valuable to understand how the method performs in more challenging scenarios, such as with very similar-sounding speakers, highly overlapping speech, or noisy environments. Additionally, the computational and runtime requirements of the system are not discussed, which could be an important consideration for real-world deployment.
Further research could also explore ways to make the target speaker extraction more robust and generalizable, such as by incorporating additional modalities (e.g., visual cues) or techniques for adapting the model to individual users' preferences and needs.
Conclusion
The USEF-TSE paper presents a novel approach for extracting a target speaker's voice from a mixed audio signal, without requiring any prior enrollment or speaker-specific data. By leveraging a universal speech representation model, the method can adapt to new speakers and scenarios, making it more practical for real-world applications.
While the results are promising, further research is needed to fully understand the limitations and explore ways to enhance the robustness and generalization capabilities of the system. Nevertheless, this work represents an important step forward in the field of target speaker extraction, with potential applications in areas such as speech enhancement, audio transcription, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
USEF-TSE: Universal Speaker Embedding Free Target Speaker Extraction
Bang Zeng, Ming Li
Target speaker extraction aims to isolate the voice of a specific speaker from mixed speech. Traditionally, this process has relied on extracting a speaker embedding from a reference speech, necessitating a speaker recognition model. However, identifying an appropriate speaker recognition model can be challenging, and using the target speaker embedding as reference information may not be optimal for target speaker extraction tasks. This paper introduces a Universal Speaker Embedding-Free Target Speaker Extraction (USEF-TSE) framework that operates without relying on speaker embeddings. USEF-TSE utilizes a multi-head cross-attention mechanism as a frame-level target speaker feature extractor. This innovative approach allows mainstream speaker extraction solutions to bypass the dependency on speaker recognition models and to fully leverage the information available in the enrollment speech, including speaker characteristics and contextual details. Additionally, USEF-TSE can seamlessly integrate with any time-domain or time-frequency domain speech separation model to achieve effective speaker extraction. Experimental results show that our proposed method achieves state-of-the-art (SOTA) performance in terms of Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) on the WSJ0-2mix, WHAM!, and WHAMR! datasets, which are standard benchmarks for monaural anechoic, noisy and noisy-reverberant two-speaker speech separation and speaker extraction.
Read more9/5/2024

0
DENSE: Dynamic Embedding Causal Target Speech Extraction
Yiwen Wang, Zeyu Yuan, Xihong Wu
Target speech extraction (TSE) focuses on extracting the speech of a specific target speaker from a mixture of signals. Existing TSE models typically utilize static embeddings as conditions for extracting the target speaker's voice. However, the static embeddings often fail to capture the contextual information of the extracted speech signal, which may limit the model's performance. We propose a novel dynamic embedding causal target speech extraction model to address this limitation. Our approach incorporates an autoregressive mechanism to generate context-dependent embeddings based on the extracted speech, enabling real-time, frame-level extraction. Experimental results demonstrate that the proposed model enhances short-time objective intelligibility (STOI) and signal-to-distortion ratio (SDR), offering a promising solution for target speech extraction in challenging scenarios.
Read more9/11/2024

0
New!Language-Queried Target Sound Extraction Without Parallel Training Data
Hao Ma, Zhiyuan Peng, Xu Li, Yukai Li, Mingjie Shao, Qiuqiang Kong, Ju Liu
Language-queried target sound extraction (TSE) aims to extract specific sounds from mixtures based on language queries. Traditional fully-supervised training schemes require extensively annotated parallel audio-text data, which are labor-intensive. We introduce a language-free training scheme, requiring only unlabelled audio clips for TSE model training by utilizing the multi-modal representation alignment nature of the contrastive language-audio pre-trained model (CLAP). In a vanilla language-free training stage, target audio is encoded using the pre-trained CLAP audio encoder to form a condition embedding for the TSE model, while during inference, user language queries are encoded by CLAP text encoder. This straightforward approach faces challenges due to the modality gap between training and inference queries and information leakage from direct exposure to target audio during training. To address this, we propose a retrieval-augmented strategy. Specifically, we create an embedding cache using audio captions generated by a large language model (LLM). During training, target audio embeddings retrieve text embeddings from this cache to use as condition embeddings, ensuring consistent modalities between training and inference and eliminating information leakage. Extensive experiment results show that our retrieval-augmented approach achieves consistent and notable performance improvements over existing state-of-the-art with better generalizability.
Read more9/17/2024
0
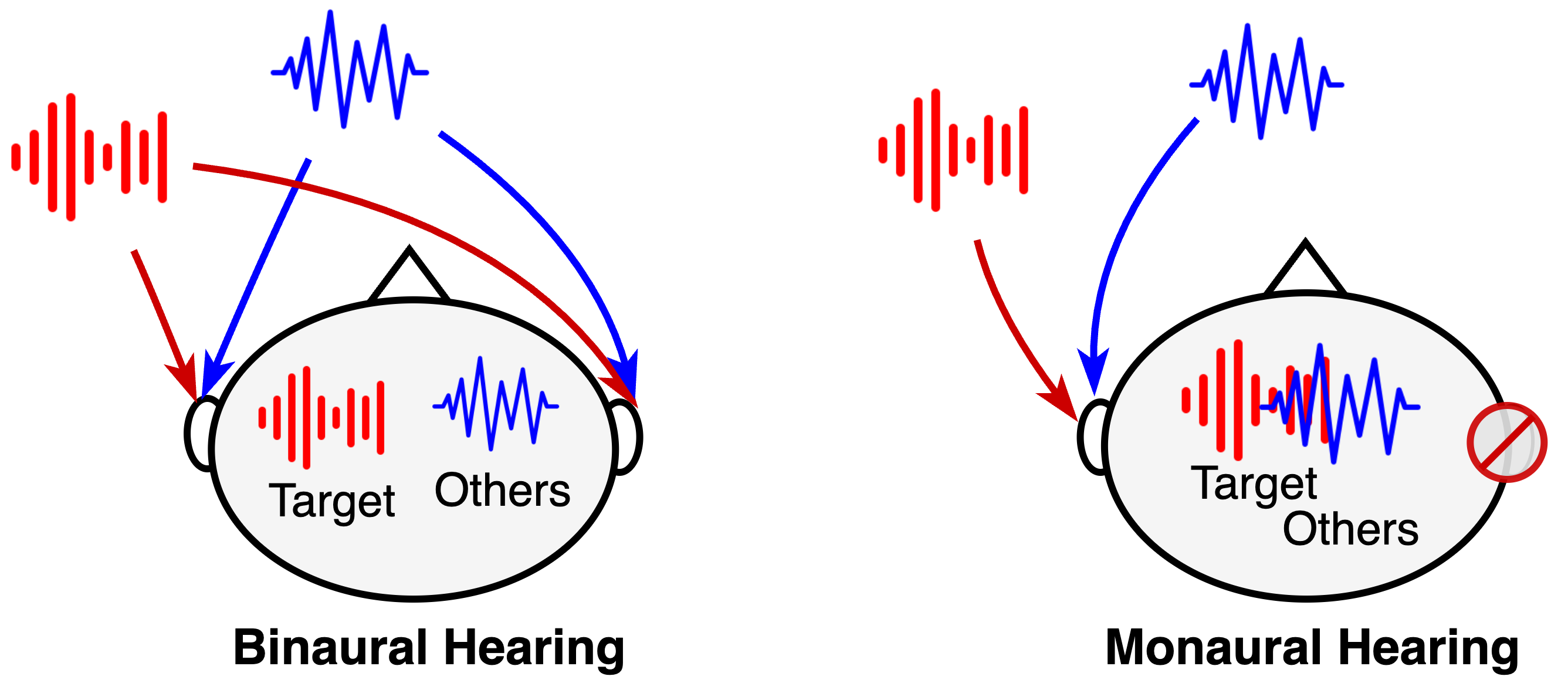
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024