Task-Adapter: Task-specific Adaptation of Image Models for Few-shot Action Recognition

0

Sign in to get full access
Overview
- The paper presents a new method called "Task-Adapter" for adapting pre-trained image models to perform few-shot action recognition.
- It introduces a task-specific adapter module that can be efficiently fine-tuned on small datasets while preserving the original model's knowledge.
- The approach aims to enable fast and accurate few-shot action recognition without requiring extensive model retraining.
Plain English Explanation
The paper proposes a new technique called "Task-Adapter" to help pre-trained image models, like those used for object recognition, perform well on the specific task of few-shot action recognition. This is important because action recognition is a different and more challenging task than basic image classification.
The key idea is to add a special "adapter" module to the pre-trained model. This adapter can be quickly fine-tuned on a small dataset of action examples, allowing the model to adapt to the new task without forgetting everything it has already learned. The authors show this approach leads to accurate action recognition performance, even when only a few training examples are available.
By preserving the original model's general knowledge while fine-tuning just the adapter, the technique aims to enable fast and efficient adaptation to new tasks, like action recognition, without having to retrain the entire model from scratch. This could be especially useful when working with limited data or computing resources.
Technical Explanation
The paper introduces a novel architecture called "Task-Adapter" that can efficiently adapt pre-trained image models to perform few-shot action recognition. The key components are:
-
Pre-trained Image Encoder: The method starts with a pre-trained image classification model, such as ResNet, that has been trained on a large dataset like ImageNet.
-
Task-Specific Adapter Module: A lightweight "adapter" module is added on top of the pre-trained encoder. This adapter consists of a small number of convolutional and fully-connected layers.
-
Selective Fine-Tuning: During fine-tuning, only the adapter module is updated, while the weights of the pre-trained encoder are frozen. This allows the model to rapidly adapt to the new action recognition task while preserving the general visual knowledge learned in the original pre-training.
The authors evaluate this approach on several few-shot action recognition benchmarks, including Kinetics-700 and Something-Something-V2. They show that Task-Adapter can match or outperform methods that fine-tune the entire model, while being more parameter-efficient and requiring less training time.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Task-Adapter approach. The authors carefully compare it to relevant baselines and state-of-the-art few-shot action recognition methods, demonstrating its effectiveness.
One potential limitation is that the approach may not work as well for highly dissimilar tasks, where the pre-trained model's knowledge is less applicable. The authors acknowledge this, noting that the success of Task-Adapter depends on the "semantic relatedness" between the pre-training and target tasks.
Additionally, while the adapter module is lightweight, it still requires training additional parameters beyond the pre-trained model. For applications with extreme resource constraints, a more parameter-efficient solution may be desirable.
Overall, the Task-Adapter method represents a promising advance in few-shot adaptation of computer vision models. The authors' insights into the importance of task-specific adaptation and selective fine-tuning could inspire further research in this direction.
Conclusion
This paper introduces a new technique called "Task-Adapter" that enables efficient adaptation of pre-trained image models to the task of few-shot action recognition. By adding a lightweight adapter module and selectively fine-tuning it, the method can quickly specialize the model to the new task while preserving its general visual knowledge.
The authors demonstrate the effectiveness of this approach on several benchmarks, showing it can achieve state-of-the-art few-shot action recognition performance with fewer parameters and less training time than full model fine-tuning. This work highlights the value of task-specific adaptation and opens up new possibilities for rapidly deploying computer vision models in diverse real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Task-Adapter: Task-specific Adaptation of Image Models for Few-shot Action Recognition
Congqi Cao, Yueran Zhang, Yating Yu, Qinyi Lv, Lingtong Min, Yanning Zhang
Existing works in few-shot action recognition mostly fine-tune a pre-trained image model and design sophisticated temporal alignment modules at feature level. However, simply fully fine-tuning the pre-trained model could cause overfitting due to the scarcity of video samples. Additionally, we argue that the exploration of task-specific information is insufficient when relying solely on well extracted abstract features. In this work, we propose a simple but effective task-specific adaptation method (Task-Adapter) for few-shot action recognition. By introducing the proposed Task-Adapter into the last several layers of the backbone and keeping the parameters of the original pre-trained model frozen, we mitigate the overfitting problem caused by full fine-tuning and advance the task-specific mechanism into the process of feature extraction. In each Task-Adapter, we reuse the frozen self-attention layer to perform task-specific self-attention across different videos within the given task to capture both distinctive information among classes and shared information within classes, which facilitates task-specific adaptation and enhances subsequent metric measurement between the query feature and support prototypes. Experimental results consistently demonstrate the effectiveness of our proposed Task-Adapter on four standard few-shot action recognition datasets. Especially on temporal challenging SSv2 dataset, our method outperforms the state-of-the-art methods by a large margin.
Read more8/2/2024
0
D$^2$ST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
Wenjie Pei, Qizhong Tan, Guangming Lu, Jiandong Tian
Adapting large pre-trained image models to few-shot action recognition has proven to be an effective and efficient strategy for learning robust feature extractors, which is essential for few-shot learning. Typical fine-tuning based adaptation paradigm is prone to overfitting in the few-shot learning scenarios and offers little modeling flexibility for learning temporal features in video data. In this work we present the Disentangled-and-Deformable Spatio-Temporal Adapter (D$^2$ST-Adapter), which is a novel adapter tuning framework well-suited for few-shot action recognition due to lightweight design and low parameter-learning overhead. It is designed in a dual-pathway architecture to encode spatial and temporal features in a disentangled manner. In particular, we devise the anisotropic Deformable Spatio-Temporal Attention module as the core component of D$^2$ST-Adapter, which can be tailored with anisotropic sampling densities along spatial and temporal domains to learn spatial and temporal features specifically in corresponding pathways, allowing our D$^2$ST-Adapter to encode features in a global view in 3D spatio-temporal space while maintaining a lightweight design. Extensive experiments with instantiations of our method on both pre-trained ResNet and ViT demonstrate the superiority of our method over state-of-the-art methods for few-shot action recognition. Our method is particularly well-suited to challenging scenarios where temporal dynamics are critical for action recognition.
Read more4/23/2024

0
Task-conditioned adaptation of visual features in multi-task policy learning
Pierre Marza, Laetitia Matignon, Olivier Simonin, Christian Wolf
Successfully addressing a wide variety of tasks is a core ability of autonomous agents, requiring flexibly adapting the underlying decision-making strategies and, as we argue in this work, also adapting the perception modules. An analogical argument would be the human visual system, which uses top-down signals to focus attention determined by the current task. Similarly, we adapt pre-trained large vision models conditioned on specific downstream tasks in the context of multi-task policy learning. We introduce task-conditioned adapters that do not require finetuning any pre-trained weights, combined with a single policy trained with behavior cloning and capable of addressing multiple tasks. We condition the visual adapters on task embeddings, which can be selected at inference if the task is known, or alternatively inferred from a set of example demonstrations. To this end, we propose a new optimization-based estimator. We evaluate the method on a wide variety of tasks from the CortexBench benchmark and show that, compared to existing work, it can be addressed with a single policy. In particular, we demonstrate that adapting visual features is a key design choice and that the method generalizes to unseen tasks given a few demonstrations.
Read more5/7/2024
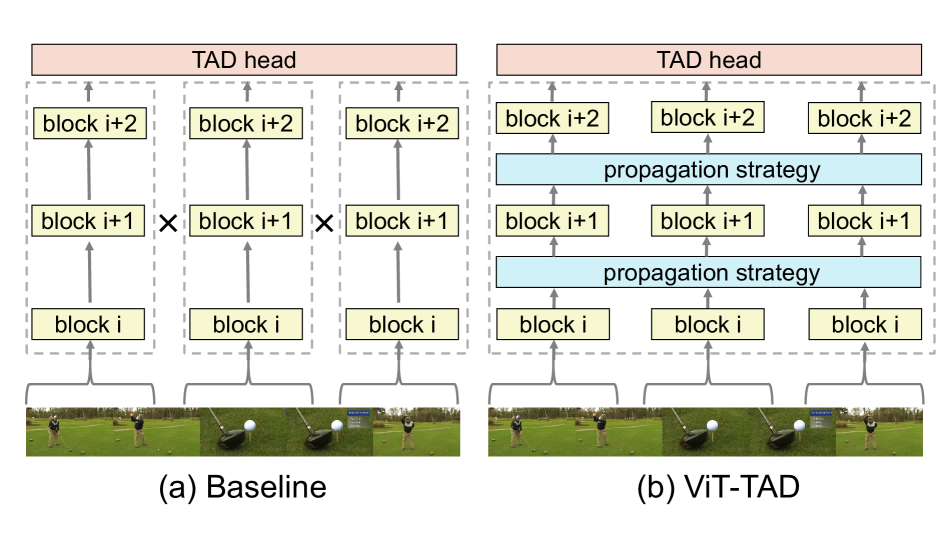
0
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Min Yang, Huan Gao, Ping Guo, Limin Wang
Vision Transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short-trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone.For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.5 average mAP on THUMOS14, 37.40 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
Read more4/16/2024