Task-adaptive Q-Face

0
Sign in to get full access
Overview
- Presents a task-adaptive multi-stage feature fusion approach for face analysis tasks
- Proposes a novel architecture called "Task-adaptive Q-Face" that dynamically adapts features to different tasks
- Demonstrates improved performance on various face analysis benchmarks compared to previous methods
Plain English Explanation
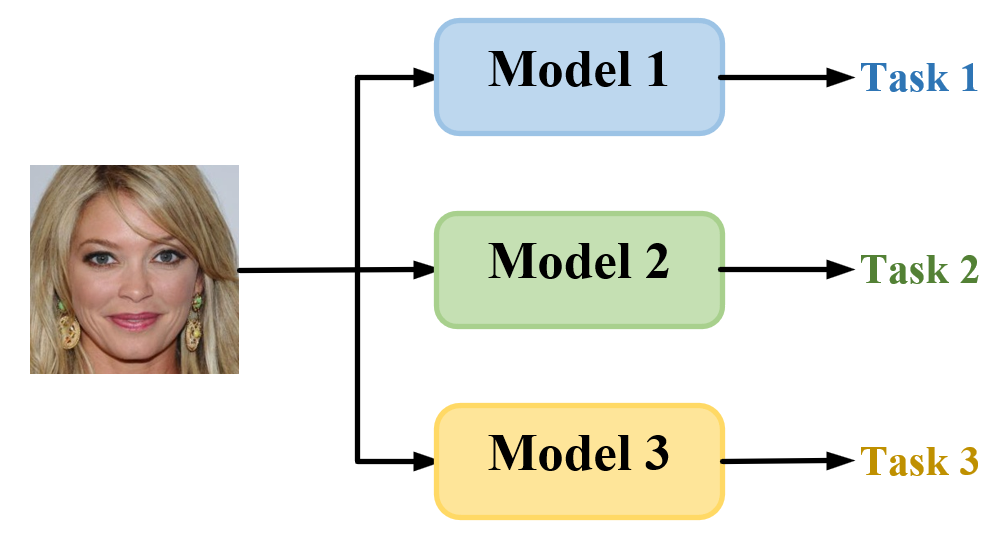
The paper introduces a new approach called "Task-adaptive Q-Face" for facial analysis tasks, such as face recognition, facial expression recognition, and head pose estimation. Traditional face analysis models often use a one-size-fits-all approach, where a single model is used for all tasks. However, the authors argue that different tasks may require different types of facial features, and a more flexible and adaptive approach is needed.
The Task-conditioned Adaptation for Visual Features in Multi-Task and Cross-Task Multi-Branch Vision Transformer for Facial Analysis papers have explored similar ideas of task-specific feature adaptation. The key innovation of Task-adaptive Q-Face is the use of a multi-stage feature fusion process that dynamically selects and combines relevant features for each task.
The model first extracts general facial features using a shared backbone network. These features are then passed through a series of task-specific "heads" that learn to adapt the features for each individual task. The final output is a fusion of these task-specific features, which allows the model to perform well on a variety of face analysis tasks.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing that Task-adaptive Q-Face outperforms previous methods in terms of accuracy and efficiency. This suggests that task-adaptive feature fusion can be a powerful technique for building robust and versatile facial analysis systems.
Technical Explanation
The Task-adaptive Q-Face model consists of several key components:
- Shared Backbone: A convolutional neural network (CNN) backbone that extracts general facial features from input images.
- Task-specific Heads: A set of task-specific "heads" that learn to adapt the shared features for each individual task, such as face recognition, facial expression recognition, and head pose estimation.
- Feature Fusion: A multi-stage feature fusion mechanism that dynamically selects and combines the most relevant task-specific features for the final output.
The authors propose a novel "Quadratic Fusion" (Q-Fusion) module that learns to weigh and combine the task-specific features in an optimal way. This allows the model to adaptively allocate attention to the most relevant features for each task, leading to improved performance.
The authors evaluate the Task-adaptive Q-Face model on several face analysis benchmarks, including FaceCAT, Multi-Task Learning for Fatigue Detection and Face Recognition, and Effective Adapter for Face Recognition in the Wild. The results show that their approach outperforms previous state-of-the-art methods in terms of both accuracy and computational efficiency.
Critical Analysis
The authors have made a compelling case for the importance of task-adaptive feature fusion in facial analysis tasks. Their experiments demonstrate the benefits of this approach over traditional one-size-fits-all models. However, there are a few potential limitations and areas for further research:
-
Scalability: While the authors show the effectiveness of their approach on several benchmarks, it remains to be seen how well Task-adaptive Q-Face would scale to a larger and more diverse set of face analysis tasks. Further testing on a wider range of tasks would be valuable.
-
Interpretability: The multi-stage feature fusion process used in Task-adaptive Q-Face can be complex and potentially difficult to interpret. Providing more insights into how the model allocates attention to different features for each task could help improve transparency and trust in the system.
-
Real-world Deployment: The authors primarily evaluate their model on controlled benchmark datasets. Assessing the performance of Task-adaptive Q-Face in more realistic, unconstrained real-world scenarios would be an important next step.
-
Computational Efficiency: While the authors claim their model is computationally efficient, a more detailed analysis of the trade-offs between performance and resource usage (e.g., memory, latency) would be helpful for practitioners looking to deploy the system in resource-constrained environments.
Overall, the Task-adaptive Q-Face approach represents a promising direction for improving the versatility and performance of facial analysis systems. The authors have made a valuable contribution to the field, and their work suggests that further research into task-adaptive feature fusion could lead to even more powerful and practical solutions.
Conclusion
The Task-adaptive Q-Face paper presents a novel architecture for face analysis tasks that dynamically adapts features to different tasks. By using a multi-stage feature fusion process, the model is able to outperform previous state-of-the-art methods on various benchmarks.
The key innovation of this work is the idea of task-adaptive feature fusion, which allows the model to allocate attention to the most relevant features for each specific task. This approach builds upon recent research in task-conditioned feature adaptation and cross-task multi-branch vision transformers, demonstrating the potential of these techniques for improving the versatility and performance of facial analysis systems.
While the authors have shown promising results, there are still opportunities for further research to address scalability, interpretability, real-world deployment, and computational efficiency. Nonetheless, the Task-adaptive Q-Face model represents an important step forward in the development of more adaptive and effective facial analysis solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Task-adaptive Q-Face
Haomiao Sun, Mingjie He, Shiguang Shan, Hu Han, Xilin Chen
Although face analysis has achieved remarkable improvements in the past few years, designing a multi-task face analysis model is still challenging. Most face analysis tasks are studied as separate problems and do not benefit from the synergy among related tasks. In this work, we propose a novel task-adaptive multi-task face analysis method named as Q-Face, which simultaneously performs multiple face analysis tasks with a unified model. We fuse the features from multiple layers of a large-scale pre-trained model so that the whole model can use both local and global facial information to support multiple tasks. Furthermore, we design a task-adaptive module that performs cross-attention between a set of query vectors and the fused multi-stage features and finally adaptively extracts desired features for each face analysis task. Extensive experiments show that our method can perform multiple tasks simultaneously and achieves state-of-the-art performance on face expression recognition, action unit detection, face attribute analysis, age estimation, and face pose estimation. Compared to conventional methods, our method opens up new possibilities for multi-task face analysis and shows the potential for both accuracy and efficiency.
Read more5/16/2024
👀
0
Cross-Task Multi-Branch Vision Transformer for Facial Expression and Mask Wearing Classification
Armando Zhu, Keqin Li, Tong Wu, Peng Zhao, Bo Hong
With wearing masks becoming a new cultural norm, facial expression recognition (FER) while taking masks into account has become a significant challenge. In this paper, we propose a unified multi-branch vision transformer for facial expression recognition and mask wearing classification tasks. Our approach extracts shared features for both tasks using a dual-branch architecture that obtains multi-scale feature representations. Furthermore, we propose a cross-task fusion phase that processes tokens for each task with separate branches, while exchanging information using a cross attention module. Our proposed framework reduces the overall complexity compared with using separate networks for both tasks by the simple yet effective cross-task fusion phase. Extensive experiments demonstrate that our proposed model performs better than or on par with different state-of-the-art methods on both facial expression recognition and facial mask wearing classification task.
Read more5/1/2024
0
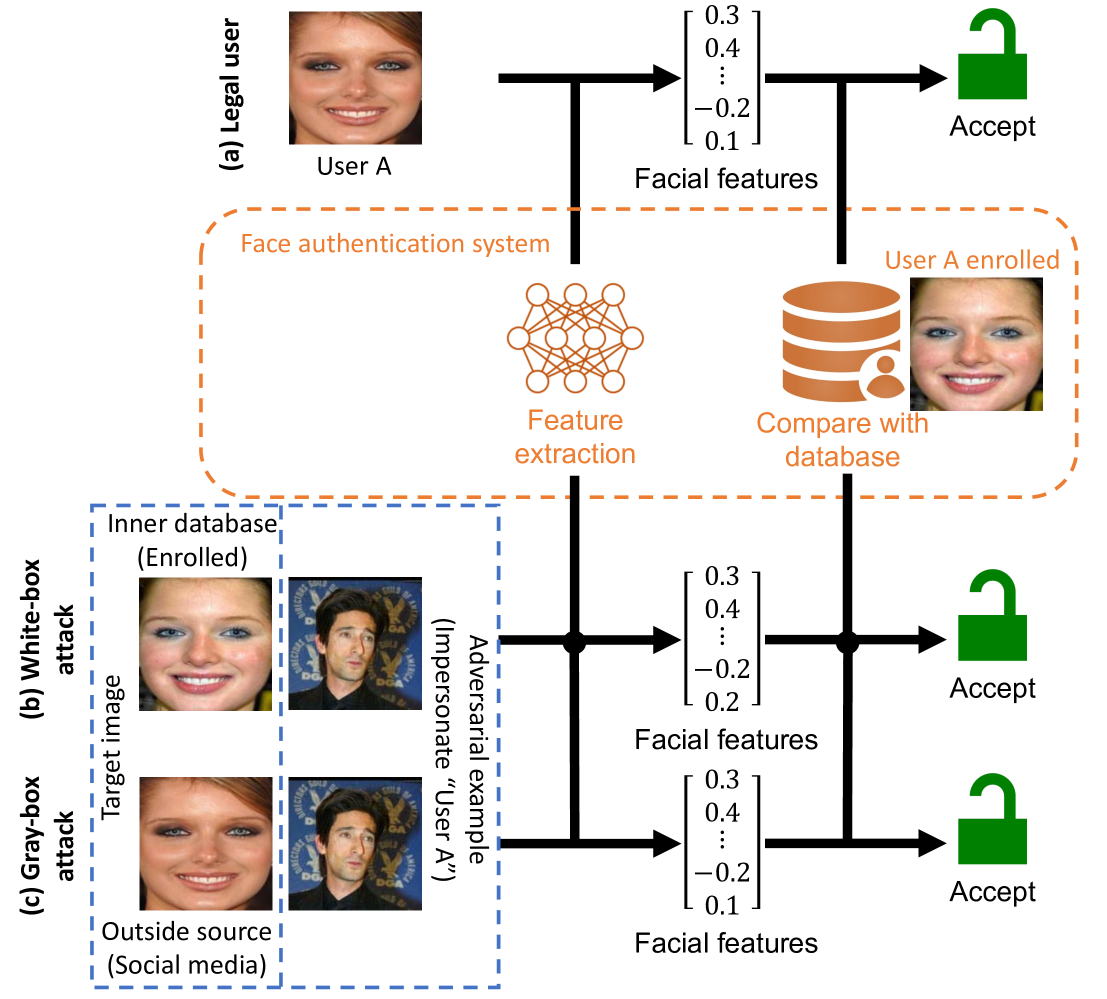
A Multi-task Adversarial Attack Against Face Authentication
Hanrui Wang, Shuo Wang, Cunjian Chen, Massimo Tistarelli, Zhe Jin
Deep-learning-based identity management systems, such as face authentication systems, are vulnerable to adversarial attacks. However, existing attacks are typically designed for single-task purposes, which means they are tailored to exploit vulnerabilities unique to the individual target rather than being adaptable for multiple users or systems. This limitation makes them unsuitable for certain attack scenarios, such as morphing, universal, transferable, and counter attacks. In this paper, we propose a multi-task adversarial attack algorithm called MTADV that are adaptable for multiple users or systems. By interpreting these scenarios as multi-task attacks, MTADV is applicable to both single- and multi-task attacks, and feasible in the white- and gray-box settings. Furthermore, MTADV is effective against various face datasets, including LFW, CelebA, and CelebA-HQ, and can work with different deep learning models, such as FaceNet, InsightFace, and CurricularFace. Importantly, MTADV retains its feasibility as a single-task attack targeting a single user/system. To the best of our knowledge, MTADV is the first adversarial attack method that can target all of the aforementioned scenarios in one algorithm.
Read more8/16/2024

0
DeepFace-Attention: Multimodal Face Biometrics for Attention Estimation with Application to e-Learning
Roberto Daza, Luis F. Gomez, Julian Fierrez, Aythami Morales, Ruben Tolosana, Javier Ortega-Garcia
This work introduces an innovative method for estimating attention levels (cognitive load) using an ensemble of facial analysis techniques applied to webcam videos. Our method is particularly useful, among others, in e-learning applications, so we trained, evaluated, and compared our approach on the mEBAL2 database, a public multi-modal database acquired in an e-learning environment. mEBAL2 comprises data from 60 users who performed 8 different tasks. These tasks varied in difficulty, leading to changes in their cognitive loads. Our approach adapts state-of-the-art facial analysis technologies to quantify the users' cognitive load in the form of high or low attention. Several behavioral signals and physiological processes related to the cognitive load are used, such as eyeblink, heart rate, facial action units, and head pose, among others. Furthermore, we conduct a study to understand which individual features obtain better results, the most efficient combinations, explore local and global features, and how temporary time intervals affect attention level estimation, among other aspects. We find that global facial features are more appropriate for multimodal systems using score-level fusion, particularly as the temporal window increases. On the other hand, local features are more suitable for fusion through neural network training with score-level fusion approaches. Our method outperforms existing state-of-the-art accuracies using the public mEBAL2 benchmark.
Read more8/15/2024