Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning

0
🔎
Sign in to get full access
Overview
- Exemplar-Free Class Incremental Learning (EFCIL) tackles the challenge of training a model on a sequence of tasks without access to past data.
- Existing methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features.
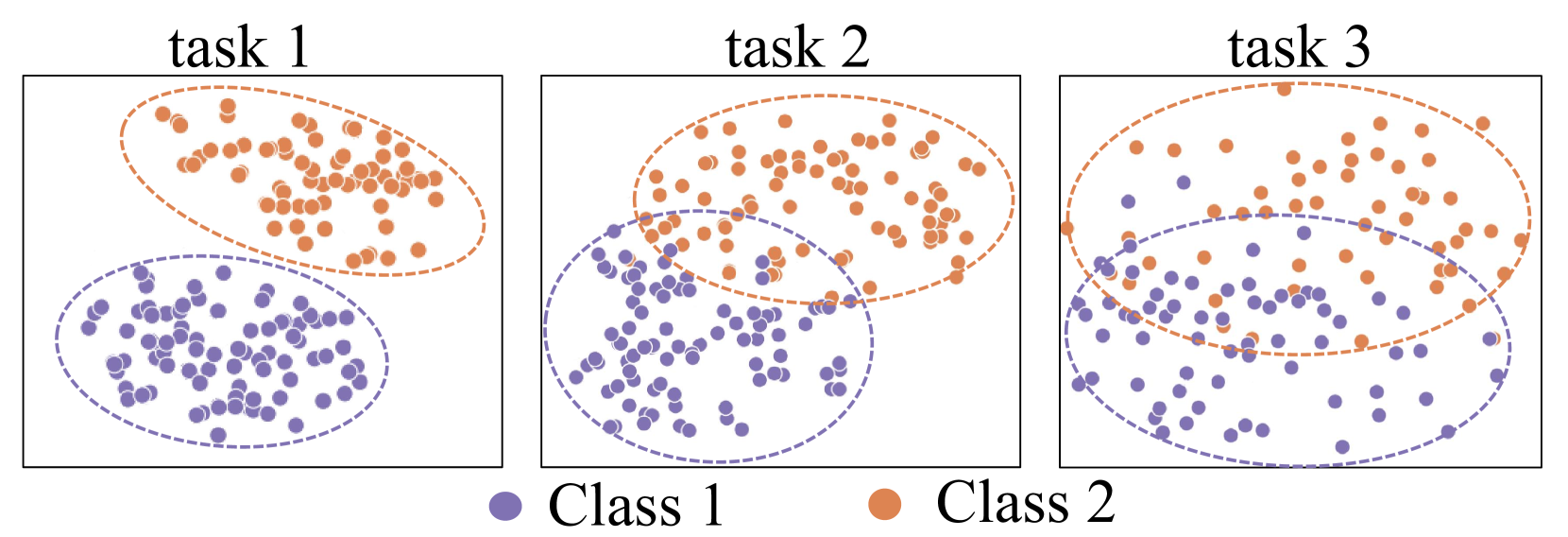
- However, two critical issues compromise the efficacy of these methods when the feature extractor is updated on incremental tasks.
Plain English Explanation
Exemplar-Free Class Incremental Learning (EFCIL) is a technique used to train a machine learning model on a series of tasks without having access to the data from previous tasks. This is a challenging problem, as the model needs to learn new information without forgetting what it has learned before.
Existing methods for EFCIL represent each class as a Gaussian (bell-shaped) distribution in the feature extractor's latent space. This allows the model to use Bayesian classification or train the classifier by replaying artificial (or "pseudo") features. However, the researchers identify two key issues with these existing methods:
-
Changing Covariance Matrices: The existing methods do not account for the fact that the covariance matrices (which describe the shape and spread) of the class distributions can change as the model is trained on new tasks. These covariance matrices need to be adapted over time.
-
Task-Recency Bias: The existing methods are susceptible to a "task-recency bias," which means the model tends to be biased towards the most recent task it was trained on. This is caused by a phenomenon called "dimensionality collapse" during the training process.
Technical Explanation
To address these issues, the researchers propose a new method called AdaGauss. AdaGauss has two key features:
-
Adaptive Covariance Matrices: AdaGauss adapts the covariance matrices of the class distributions from one task to the next, to account for changes in the feature extractor.
-
Anti-Collapse Loss: AdaGauss includes an additional "anti-collapse" loss function to mitigate the task-recency bias caused by dimensionality collapse during training.
The researchers show that AdaGauss achieves state-of-the-art results on popular EFCIL benchmarks and datasets, whether training the model from scratch or starting from a pre-trained backbone.
Critical Analysis
The paper identifies two important limitations of existing EFCIL methods and proposes a novel solution to address them. However, the researchers do not discuss any potential downsides or caveats of the AdaGauss approach.
One area for further research could be to investigate the computational overhead of the adaptive covariance matrices and anti-collapse loss function, and how this impacts the overall training time and efficiency of the model.
Additionally, it would be valuable to understand how AdaGauss performs on a wider range of datasets and tasks, to ensure the method is robust and generalizable.
Conclusion
The AdaGauss method proposed in this paper represents a significant advancement in Exemplar-Free Class Incremental Learning. By adapting the covariance matrices of class distributions and mitigating task-recency bias, AdaGauss achieves state-of-the-art performance on EFCIL benchmarks.
This research has important implications for developing machine learning models that can continuously learn new information without forgetting what they've learned before. The ability to learn in this way could enable more flexible and adaptable AI systems that can be deployed in dynamic, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning
Grzegorz Rype's'c, Sebastian Cygert, Tomasz Trzci'nski, Bart{l}omiej Twardowski
Exemplar-Free Class Incremental Learning (EFCIL) tackles the problem of training a model on a sequence of tasks without access to past data. Existing state-of-the-art methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features. However, we identify two critical issues that compromise their efficacy when the feature extractor is updated on incremental tasks. First, they do not consider that classes' covariance matrices change and must be adapted after each task. Second, they are susceptible to a task-recency bias caused by dimensionality collapse occurring during training. In this work, we propose AdaGauss -- a novel method that adapts covariance matrices from task to task and mitigates the task-recency bias owing to the additional anti-collapse loss function. AdaGauss yields state-of-the-art results on popular EFCIL benchmarks and datasets when training from scratch or starting from a pre-trained backbone. The code is available at: https://github.com/grypesc/AdaGauss.
Read more9/30/2024
✨
0
Elastic Feature Consolidation for Cold Start Exemplar-Free Incremental Learning
Simone Magistri, Tomaso Trinci, Albin Soutif-Cormerais, Joost van de Weijer, Andrew D. Bagdanov
Exemplar-Free Class Incremental Learning (EFCIL) aims to learn from a sequence of tasks without having access to previous task data. In this paper, we consider the challenging Cold Start scenario in which insufficient data is available in the first task to learn a high-quality backbone. This is especially challenging for EFCIL since it requires high plasticity, which results in feature drift which is difficult to compensate for in the exemplar-free setting. To address this problem, we propose a simple and effective approach that consolidates feature representations by regularizing drift in directions highly relevant to previous tasks and employs prototypes to reduce task-recency bias. Our method, called Elastic Feature Consolidation (EFC), exploits a tractable second-order approximation of feature drift based on an Empirical Feature Matrix (EFM). The EFM induces a pseudo-metric in feature space which we use to regularize feature drift in important directions and to update Gaussian prototypes used in a novel asymmetric cross entropy loss which effectively balances prototype rehearsal with data from new tasks. Experimental results on CIFAR-100, Tiny-ImageNet, ImageNet-Subset and ImageNet-1K demonstrate that Elastic Feature Consolidation is better able to learn new tasks by maintaining model plasticity and significantly outperform the state-of-the-art.
Read more5/31/2024
0
Adaptive Margin Global Classifier for Exemplar-Free Class-Incremental Learning
Zhongren Yao, Xiaobin Chang
Exemplar-free class-incremental learning (EFCIL) presents a significant challenge as the old class samples are absent for new task learning. Due to the severe imbalance between old and new class samples, the learned classifiers can be easily biased toward the new ones. Moreover, continually updating the feature extractor under EFCIL can compromise the discriminative power of old class features, e.g., leading to less compact and more overlapping distributions across classes. Existing methods mainly focus on handling biased classifier learning. In this work, both cases are considered using the proposed method. Specifically, we first introduce a Distribution-Based Global Classifier (DBGC) to avoid bias factors in existing methods, such as data imbalance and sampling. More importantly, the compromised distributions of old classes are simulated via a simple operation, variance enlarging (VE). Incorporating VE based on DBGC results in a novel classification loss for EFCIL. This loss is proven equivalent to an Adaptive Margin Softmax Cross Entropy (AMarX). The proposed method is thus called Adaptive Margin Global Classifier (AMGC). AMGC is simple yet effective. Extensive experiments show that AMGC achieves superior image classification results on its own under a challenging EFCIL setting. Detailed analysis is also provided for further demonstration.
Read more9/23/2024

0
Resurrecting Old Classes with New Data for Exemplar-Free Continual Learning
Dipam Goswami, Albin Soutif--Cormerais, Yuyang Liu, Sandesh Kamath, Bart{l}omiej Twardowski, Joost van de Weijer
Continual learning methods are known to suffer from catastrophic forgetting, a phenomenon that is particularly hard to counter for methods that do not store exemplars of previous tasks. Therefore, to reduce potential drift in the feature extractor, existing exemplar-free methods are typically evaluated in settings where the first task is significantly larger than subsequent tasks. Their performance drops drastically in more challenging settings starting with a smaller first task. To address this problem of feature drift estimation for exemplar-free methods, we propose to adversarially perturb the current samples such that their embeddings are close to the old class prototypes in the old model embedding space. We then estimate the drift in the embedding space from the old to the new model using the perturbed images and compensate the prototypes accordingly. We exploit the fact that adversarial samples are transferable from the old to the new feature space in a continual learning setting. The generation of these images is simple and computationally cheap. We demonstrate in our experiments that the proposed approach better tracks the movement of prototypes in embedding space and outperforms existing methods on several standard continual learning benchmarks as well as on fine-grained datasets. Code is available at https://github.com/dipamgoswami/ADC.
Read more5/30/2024