Resurrecting Old Classes with New Data for Exemplar-Free Continual Learning

0

Sign in to get full access
Overview
- This paper proposes a new approach for continual learning, where a model learns to classify new classes without access to exemplars (i.e., samples) from old classes.
- The key idea is to "resurrect" old classes by generating new training data for them, using generative models trained on the new data.
- This allows the model to learn new classes without catastrophically forgetting the old ones, a common problem in continual learning.
Plain English Explanation
The paper discusses a way to help artificial intelligence (AI) models continue learning new things without completely forgetting what they already know. This is a common challenge in "continual learning," where an AI model is trained on a sequence of tasks or datasets.
Typically, when an AI model learns new things, it can start to "forget" the old information it was trained on. This is called "catastrophic forgetting." The researchers in this paper found a way to prevent this by "resurrecting" the old classes (i.e., the things the model originally learned) using new data.
The key idea is to train a separate generative model (like a type of AI that can create new data) on the new information. This generative model can then be used to create new "fake" examples of the old classes. The main AI model can then be trained on this new data, allowing it to learn the new classes without forgetting the old ones.
This approach is particularly useful in situations where you can't keep the original training data for the old classes (e.g., for privacy reasons). By generating new data, the model can still learn new things without losing its previous knowledge.
Technical Explanation
The paper introduces a new continual learning method called Resurrecting Old Classes with New Data for Exemplar-Free Continual Learning. The key innovation is the use of generative models to create new training data for "old" classes (i.e., classes learned in previous tasks) when learning new classes.
In a typical continual learning scenario, when a model learns a new task, it can suffer from "catastrophic forgetting," where its performance on old tasks degrades. To address this, the authors propose using a generative model to create new samples for the old classes, which can then be used to train the main classification model on the new task without forgetting the old ones.
Specifically, the authors use a conditional generative adversarial network (cGAN) to generate new samples for the old classes. This cGAN is trained on the new data for the current task, and then used to generate "resurrected" samples for the old classes. The main classification model is then trained on the combination of the new task data and the generated old class samples.
The authors evaluate their approach, called Adaptive Retention Correction for Continual Learning, on several continual learning benchmarks, including Learning to Classify New Foods Incrementally via Visual Domain Adaptation and Bayesian Learning-Driven Prototypical Contrastive Loss for Class-Incremental Learning. They show that their method outperforms previous state-of-the-art continual learning approaches in terms of retaining performance on old tasks while learning new ones.
Critical Analysis
The paper presents a novel and promising approach to continual learning, addressing the key challenge of catastrophic forgetting. By using generative models to "resurrect" old classes, the method allows the main classification model to learn new tasks without losing its previous knowledge.
One potential limitation is the reliance on the generative model's ability to faithfully reproduce the old class distributions. If the generated samples do not accurately reflect the original data, this could negatively impact the main model's performance on the old tasks. Further research could explore ways to ensure the generated samples are high-quality and representative of the old classes.
Additionally, the paper does not extensively explore the scalability of the approach to a large number of tasks or classes. As the number of old classes grows, the computational and memory requirements of the generative models could become a concern. Investigating strategies to manage this complexity would be a valuable area for future work.
Overall, the paper presents a compelling and innovative solution to a fundamental challenge in continual learning. The use of generative models to "resurrect" old knowledge is a promising direction that could have significant implications for the development of more robust and adaptable AI systems.
Conclusion
This paper introduces a novel continual learning approach that addresses the problem of catastrophic forgetting. By using generative models to create new training data for "old" classes, the method allows AI models to learn new tasks without losing their previous knowledge.
The key innovation is the "resurrection" of old classes using conditional generative adversarial networks (cGANs). These cGANs are trained on the new data and then used to generate samples for the old classes, which are then combined with the new task data to train the main classification model.
The authors demonstrate the effectiveness of their approach, called Adaptive Retention Correction for Continual Learning, on several continual learning benchmarks. Their method outperforms previous state-of-the-art approaches in retaining performance on old tasks while learning new ones.
This research represents an important step forward in the field of continual learning, addressing a critical challenge that has limited the deployment of AI systems in dynamic, real-world environments. By enabling models to continuously learn and adapt without forgetting, this work paves the way for more robust and capable AI assistants, agents, and decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Resurrecting Old Classes with New Data for Exemplar-Free Continual Learning
Dipam Goswami, Albin Soutif--Cormerais, Yuyang Liu, Sandesh Kamath, Bart{l}omiej Twardowski, Joost van de Weijer
Continual learning methods are known to suffer from catastrophic forgetting, a phenomenon that is particularly hard to counter for methods that do not store exemplars of previous tasks. Therefore, to reduce potential drift in the feature extractor, existing exemplar-free methods are typically evaluated in settings where the first task is significantly larger than subsequent tasks. Their performance drops drastically in more challenging settings starting with a smaller first task. To address this problem of feature drift estimation for exemplar-free methods, we propose to adversarially perturb the current samples such that their embeddings are close to the old class prototypes in the old model embedding space. We then estimate the drift in the embedding space from the old to the new model using the perturbed images and compensate the prototypes accordingly. We exploit the fact that adversarial samples are transferable from the old to the new feature space in a continual learning setting. The generation of these images is simple and computationally cheap. We demonstrate in our experiments that the proposed approach better tracks the movement of prototypes in embedding space and outperforms existing methods on several standard continual learning benchmarks as well as on fine-grained datasets. Code is available at https://github.com/dipamgoswami/ADC.
Read more5/30/2024

0
Exemplar-free Continual Representation Learning via Learnable Drift Compensation
Alex Gomez-Villa, Dipam Goswami, Kai Wang, Andrew D. Bagdanov, Bartlomiej Twardowski, Joost van de Weijer
Exemplar-free class-incremental learning using a backbone trained from scratch and starting from a small first task presents a significant challenge for continual representation learning. Prototype-based approaches, when continually updated, face the critical issue of semantic drift due to which the old class prototypes drift to different positions in the new feature space. Through an analysis of prototype-based continual learning, we show that forgetting is not due to diminished discriminative power of the feature extractor, and can potentially be corrected by drift compensation. To address this, we propose Learnable Drift Compensation (LDC), which can effectively mitigate drift in any moving backbone, whether supervised or unsupervised. LDC is fast and straightforward to integrate on top of existing continual learning approaches. Furthermore, we showcase how LDC can be applied in combination with self-supervised CL methods, resulting in the first exemplar-free semi-supervised continual learning approach. We achieve state-of-the-art performance in both supervised and semi-supervised settings across multiple datasets. Code is available at url{https://github.com/alviur/ldc}.
Read more7/12/2024
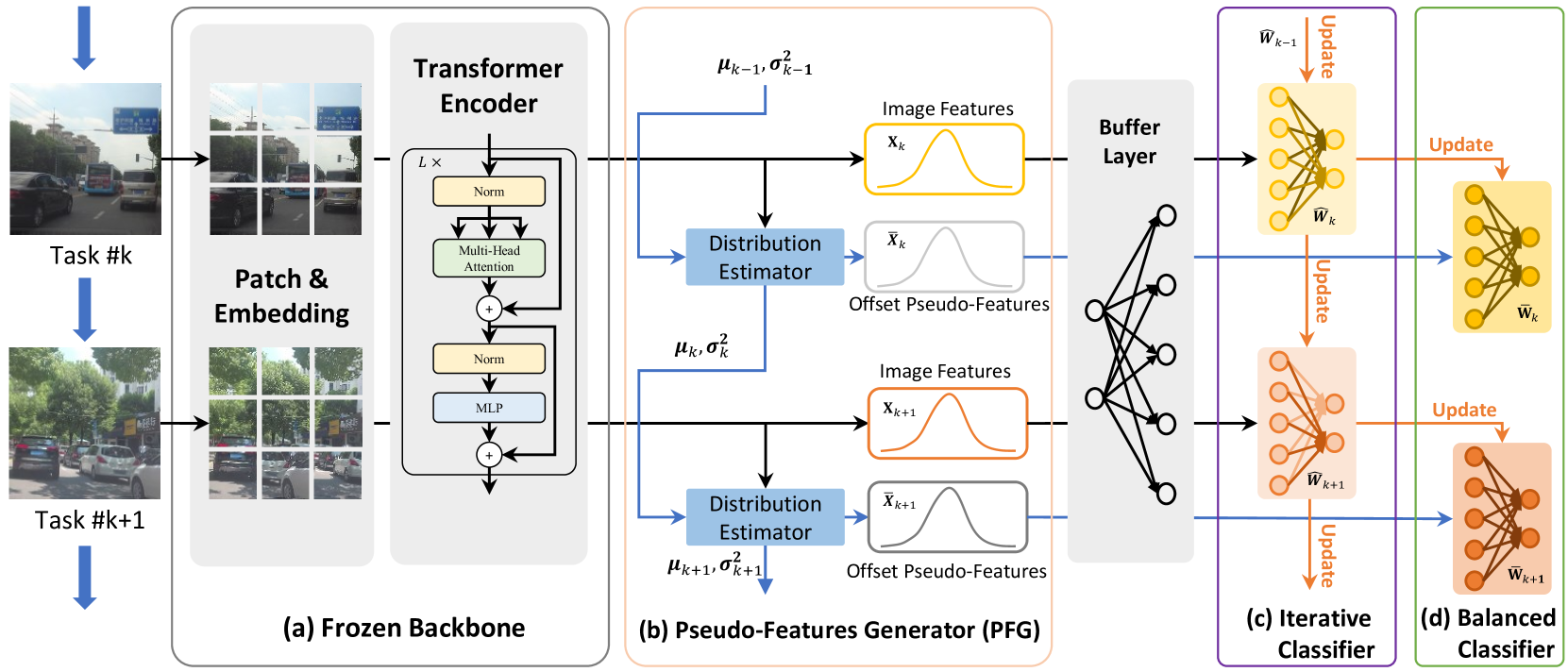
0
Online Analytic Exemplar-Free Continual Learning with Large Models for Imbalanced Autonomous Driving Task
Huiping Zhuang, Di Fang, Kai Tong, Yuchen Liu, Ziqian Zeng, Xu Zhou, Cen Chen
In the field of autonomous driving, even a meticulously trained model can encounter failures when faced with unfamiliar sceanrios. One of these scenarios can be formulated as an online continual learning (OCL) problem. That is, data come in an online fashion, and models are updated according to these streaming data. Two major OCL challenges are catastrophic forgetting and data imbalance. To address these challenges, in this paper, we propose an Analytic Exemplar-Free Online Continual Learning (AEF-OCL). The AEF-OCL leverages analytic continual learning principles and employs ridge regression as a classifier for features extracted by a large backbone network. It solves the OCL problem by recursively calculating the analytical solution, ensuring an equalization between the continual learning and its joint-learning counterpart, and works without the need to save any used samples (i.e., exemplar-free). Additionally, we introduce a Pseudo-Features Generator (PFG) module that recursively estimates the deviation of real features. The PFG generates offset pseudo-features following a normal distribution, thereby addressing the data imbalance issue. Experimental results demonstrate that despite being an exemplar-free strategy, our method outperforms various methods on the autonomous driving SODA10M dataset. Source code is available at https://github.com/ZHUANGHP/Analytic-continual-learning.
Read more5/29/2024
🔎
0
New!Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning
Grzegorz Rype's'c, Sebastian Cygert, Tomasz Trzci'nski, Bart{l}omiej Twardowski
Exemplar-Free Class Incremental Learning (EFCIL) tackles the problem of training a model on a sequence of tasks without access to past data. Existing state-of-the-art methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features. However, we identify two critical issues that compromise their efficacy when the feature extractor is updated on incremental tasks. First, they do not consider that classes' covariance matrices change and must be adapted after each task. Second, they are susceptible to a task-recency bias caused by dimensionality collapse occurring during training. In this work, we propose AdaGauss -- a novel method that adapts covariance matrices from task to task and mitigates the task-recency bias owing to the additional anti-collapse loss function. AdaGauss yields state-of-the-art results on popular EFCIL benchmarks and datasets when training from scratch or starting from a pre-trained backbone. The code is available at: https://github.com/grypesc/AdaGauss.
Read more9/30/2024