TDS-CLIP: Temporal Difference Side Network for Image-to-Video Transfer Learning

0

Sign in to get full access
Overview
- The paper introduces TDS-CLIP, a novel method for transferring knowledge from image-based models to video-based tasks.
- TDS-CLIP adds a "Temporal Difference Side Network" to CLIP, an image-text model, to capture temporal information and improve performance on video-based tasks.
- The proposed approach outperforms previous methods for image-to-video transfer learning on several video benchmarks.
Plain English Explanation
The researchers developed a new technique called TDS-CLIP to help AI models that are trained on images do better at video-related tasks. CLIP is an AI model that can understand the relationship between images and text, but it doesn't naturally handle the temporal information in videos.
To fix this, TDS-CLIP adds an extra "side network" to CLIP that is specifically designed to capture the changes over time in a video. This allows the model to learn not just what's in each individual frame, but how the scenes and objects are moving and evolving from one frame to the next.
By incorporating this temporal information, TDS-CLIP is able to outperform previous methods that tried to adapt image-based models like CLIP to work on video tasks. The researchers show that TDS-CLIP achieves better results on several video benchmarks compared to other transfer learning approaches.
Technical Explanation
The key innovation in TDS-CLIP is the addition of a "Temporal Difference Side Network" that runs alongside the main CLIP model. This side network takes in pairs of consecutive frames from a video and learns to predict the temporal differences between them.
The authors hypothesize that this temporal difference information can help the overall model better understand and reason about the dynamics of a video, rather than just recognizing objects and scenes in individual frames.
The TDS-CLIP architecture consists of the original CLIP image encoder, a text encoder, and the new temporal difference side network. The side network has its own convolutional layers that process the frame pairs and produce a temporal difference representation, which is then combined with the CLIP image features.
This combined representation is used for the final video-based task, such as action recognition or video retrieval. By leveraging both the spatial information from CLIP and the temporal dynamics from the side network, TDS-CLIP is able to outperform prior image-to-video transfer learning approaches.
Critical Analysis
The authors provide a thorough evaluation of TDS-CLIP, testing it on multiple video benchmarks and comparing to strong baselines. The results demonstrate the effectiveness of the temporal difference side network in boosting performance on video-based tasks.
However, one potential limitation is that the side network is trained independently from the main CLIP model. It may be worth exploring joint training approaches where the two components can more tightly interact and optimize the representations for the target video tasks.
Additionally, the paper does not deeply analyze the types of temporal patterns the side network is learning, or how those dynamics differ from what the original CLIP model captures. Further insight into the complementary strengths of the two components could lead to even more powerful video understanding capabilities.
Overall, TDS-CLIP represents an important step forward in bridging the gap between image and video understanding using transfer learning. The core ideas could potentially be applied to other pre-trained vision-language models beyond just CLIP.
Conclusion
The TDS-CLIP method introduces a clever way to extend image-based models like CLIP to work better on video-related tasks. By adding a side network focused on learning temporal differences between frames, the approach is able to capture important dynamic information that complements the spatial understanding of the original model.
The strong empirical results on video benchmarks highlight the value of this approach for advancing the state-of-the-art in video understanding. As deep learning models continue to excel at image recognition, techniques like TDS-CLIP will be crucial for translating those capabilities to the more complex domain of video analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TDS-CLIP: Temporal Difference Side Network for Image-to-Video Transfer Learning
Bin Wang, Wenqian Wang
Recently, large-scale pre-trained vision-language models (e.g., CLIP), have garnered significant attention thanks to their powerful representative capabilities. This inspires researchers in transferring the knowledge from these large pre-trained models to other task-specific models, e.g., Video Action Recognition (VAR) models, via particularly leveraging side networks to enhance the efficiency of parameter-efficient fine-tuning (PEFT). However, current transferring approaches in VAR tend to directly transfer the frozen knowledge from large pre-trained models to action recognition networks with minimal cost, instead of exploiting the temporal modeling capabilities of the action recognition models themselves. Therefore, in this paper, we propose a memory-efficient Temporal Difference Side Network (TDS-CLIP) to balance knowledge transferring and temporal modeling, avoiding backpropagation in frozen parameter models. Specifically, we introduce a Temporal Difference Adapter (TD-Adapter), which can effectively capture local temporal differences in motion features to strengthen the model's global temporal modeling capabilities. Furthermore, we designed a Side Motion Enhancement Adapter (SME-Adapter) to guide the proposed side network in efficiently learning the rich motion information in videos, thereby improving the side network's ability to capture and learn motion information. Extensive experiments are conducted on three benchmark datasets, including Something-Something V1&V2, and Kinetics-400. Experimental results demonstrate that our approach achieves competitive performance.
Read more8/21/2024

0
Leveraging Temporal Contextualization for Video Action Recognition
Minji Kim, Dongyoon Han, Taekyung Kim, Bohyung Han
We propose a novel framework for video understanding, called Temporally Contextualized CLIP (TC-CLIP), which leverages essential temporal information through global interactions in a spatio-temporal domain within a video. To be specific, we introduce Temporal Contextualization (TC), a layer-wise temporal information infusion mechanism for videos, which 1) extracts core information from each frame, 2) connects relevant information across frames for the summarization into context tokens, and 3) leverages the context tokens for feature encoding. Furthermore, the Video-conditional Prompting (VP) module processes context tokens to generate informative prompts in the text modality. Extensive experiments in zero-shot, few-shot, base-to-novel, and fully-supervised action recognition validate the effectiveness of our model. Ablation studies for TC and VP support our design choices. Our project page with the source code is available at https://github.com/naver-ai/tc-clip
Read more7/25/2024
0
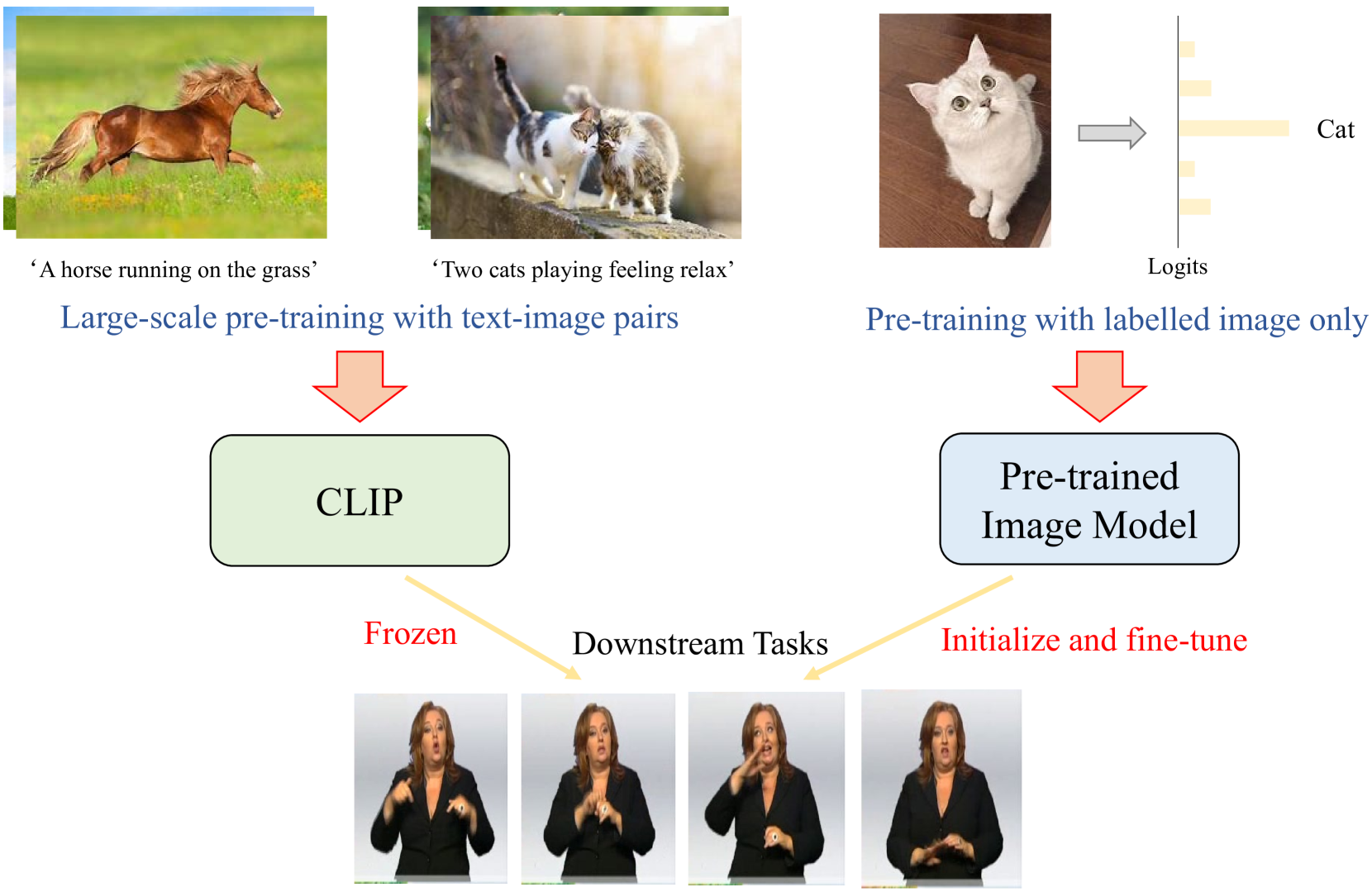
Improving Continuous Sign Language Recognition with Adapted Image Models
Lianyu Hu, Tongkai Shi, Liqing Gao, Zekang Liu, Wei Feng
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Read more4/15/2024
0
D$^2$ST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
Wenjie Pei, Qizhong Tan, Guangming Lu, Jiandong Tian
Adapting large pre-trained image models to few-shot action recognition has proven to be an effective and efficient strategy for learning robust feature extractors, which is essential for few-shot learning. Typical fine-tuning based adaptation paradigm is prone to overfitting in the few-shot learning scenarios and offers little modeling flexibility for learning temporal features in video data. In this work we present the Disentangled-and-Deformable Spatio-Temporal Adapter (D$^2$ST-Adapter), which is a novel adapter tuning framework well-suited for few-shot action recognition due to lightweight design and low parameter-learning overhead. It is designed in a dual-pathway architecture to encode spatial and temporal features in a disentangled manner. In particular, we devise the anisotropic Deformable Spatio-Temporal Attention module as the core component of D$^2$ST-Adapter, which can be tailored with anisotropic sampling densities along spatial and temporal domains to learn spatial and temporal features specifically in corresponding pathways, allowing our D$^2$ST-Adapter to encode features in a global view in 3D spatio-temporal space while maintaining a lightweight design. Extensive experiments with instantiations of our method on both pre-trained ResNet and ViT demonstrate the superiority of our method over state-of-the-art methods for few-shot action recognition. Our method is particularly well-suited to challenging scenarios where temporal dynamics are critical for action recognition.
Read more4/23/2024