TEDNet: Twin Encoder Decoder Neural Network for 2D Camera and LiDAR Road Detection
2405.08429
0
0

Abstract
Robust road surface estimation is required for autonomous ground vehicles to navigate safely. Despite it becoming one of the main targets for autonomous mobility researchers in recent years, it is still an open problem in which cameras and LiDAR sensors have demonstrated to be adequate to predict the position, size and shape of the road a vehicle is driving on in different environments. In this work, a novel Convolutional Neural Network model is proposed for the accurate estimation of the roadway surface. Furthermore, an ablation study has been conducted to investigate how different encoding strategies affect model performance, testing 6 slightly different neural network architectures. Our model is based on the use of a Twin Encoder-Decoder Neural Network (TEDNet) for independent camera and LiDAR feature extraction, and has been trained and evaluated on the Kitti-Road dataset. Bird's Eye View projections of the camera and LiDAR data are used in this model to perform semantic segmentation on whether each pixel belongs to the road surface. The proposed method performs among other state-of-the-art methods and operates at the same frame-rate as the LiDAR and cameras, so it is adequate for its use in real-time applications.
Create account to get full access
Overview
- Presents a novel neural network architecture called TEDNet (Twin Encoder Decoder Neural Network) for road detection using 2D camera and LiDAR data
- Combines two encoder-decoder networks to leverage both camera and LiDAR sensors for improved road detection performance
- Demonstrates state-of-the-art results on publicly available road detection datasets
Plain English Explanation
TEDNet is a machine learning model designed to help self-driving cars and robots better detect roads and navigate their surroundings. Many vehicles today use a combination of cameras and LiDAR (light detection and ranging) sensors to perceive the world, but the researchers behind TEDNet found that existing approaches don't always do a great job of combining this information effectively.
To address this, the researchers developed a neural network with two separate "encoder-decoder" modules - one that processes the camera data and one that processes the LiDAR data. These modules work together to paint a more complete picture of the road, allowing the system to detect the road boundaries more accurately than previous methods. The team demonstrated that this "twin" architecture outperforms other leading road detection techniques on standard benchmarks.
The key innovation of TEDNet is its ability to fuse the complementary strengths of camera and LiDAR data. Cameras provide detailed color and texture information, while LiDAR gives precise 3D shape and distance measurements. By learning to intelligently combine these two data sources, TEDNet can robustly identify roads even in challenging conditions like poor lighting or complex environments.
Technical Explanation
The core of TEDNet is a pair of encoder-decoder neural networks - one that processes 2D camera images and one that processes 3D LiDAR point clouds. These two networks operate in parallel and their outputs are then fused together to produce the final road detection result.
The camera encoder-decoder network follows a standard U-Net architecture, with convolutional layers to extract visual features followed by upsampling layers to generate a dense pixel-wise road segmentation map. The LiDAR encoder-decoder network uses a similar design, but with 3D convolutions and a voxel-based input representation to handle the structured point cloud data.
To integrate the two modalities, the researchers introduce a novel "cross-attention" module that learns to dynamically weight and combine the features from the camera and LiDAR networks. This allows the model to adaptively focus on the most relevant visual and geometric cues for accurate road detection.
The team evaluated TEDNet on several public benchmarks, including the Argoverse and nuScenes datasets. They found that the dual-encoder approach consistently outperformed single-modality baselines as well as other state-of-the-art camera-LiDAR fusion methods like CLFT and HENet. This demonstrates the effectiveness of TEDNet's architecture in leveraging complementary sensor data for robust road detection.
Critical Analysis
The main strength of TEDNet is its ability to seamlessly fuse camera and LiDAR data to achieve superior road detection performance. The cross-attention mechanism appears to be a key innovation that allows the model to adaptively combine the visual and geometric cues from the two modalities.
However, the paper does not provide much insight into the internal workings of this cross-attention module or how it learns to prioritize the different sensor inputs. Additionally, the authors do not explore the model's robustness to sensor failures or degradation, which would be an important consideration for real-world autonomous systems.
Another potential limitation is the computational complexity of running two separate encoder-decoder networks in parallel. While the authors report real-time inference speeds, the overall model size and latency may be a concern for deployment on resource-constrained platforms like self-driving cars. Approaches like 3D-LiDAR Mapping or Real-Time Vehicle/Pedestrian Detection that aim to reduce model complexity could be interesting avenues for further research.
Overall, TEDNet represents a promising step forward in camera-LiDAR fusion for road detection, but there are still opportunities to improve the model's interpretability, efficiency, and robustness for real-world autonomous applications.
Conclusion
The TEDNet paper presents a novel neural network architecture that effectively combines 2D camera and 3D LiDAR data for road detection. By using two parallel encoder-decoder networks and a cross-attention module, the model is able to leverage the complementary strengths of the two sensor modalities to achieve state-of-the-art performance on standard benchmarks.
This work demonstrates the value of sensor fusion for building robust perception systems, and the authors' insights on adaptively combining visual and geometric cues could inspire future developments in areas like camera-agnostic lane detection. As autonomous vehicles and robotics continue to advance, techniques like TEDNet will play an increasingly important role in helping these systems better understand and navigate their environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
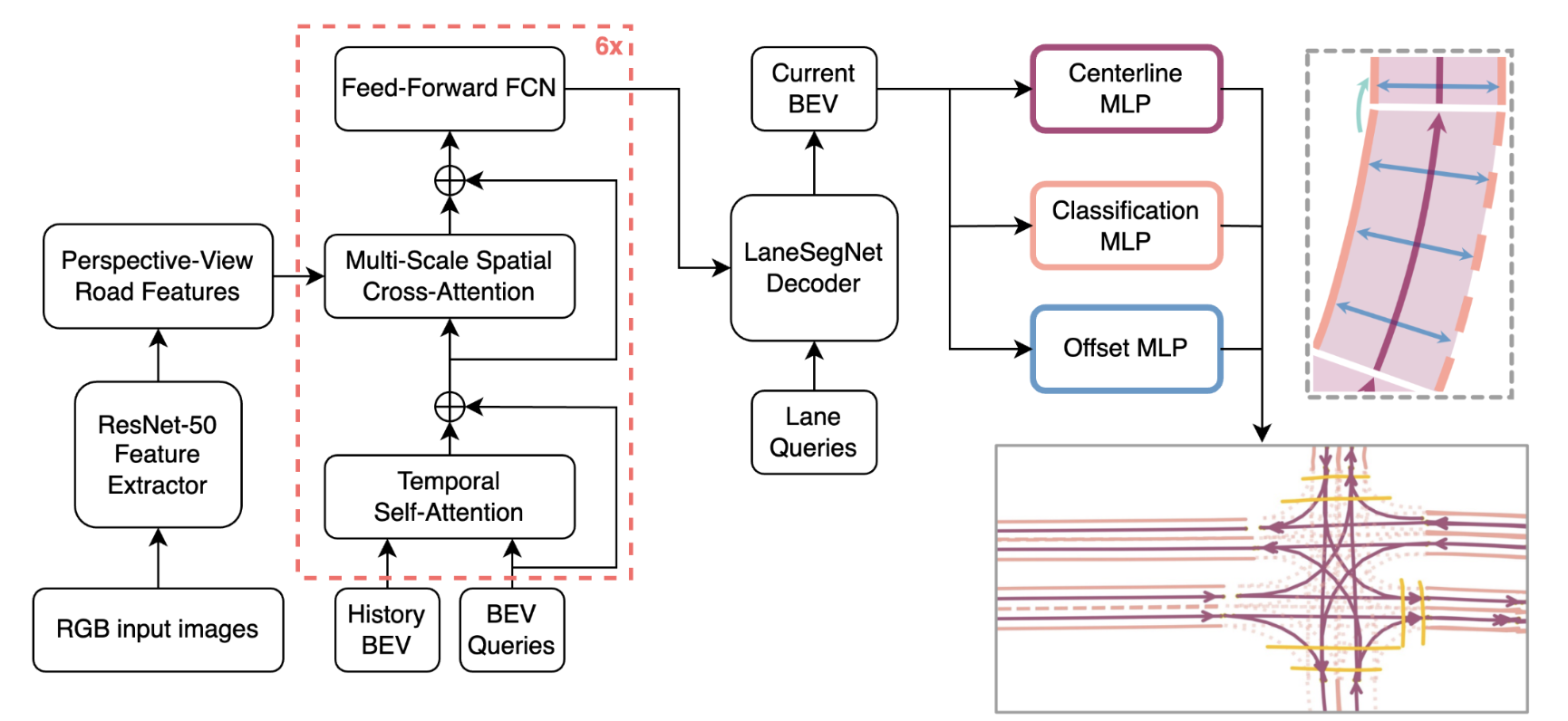
LaneSegNet Design Study
William Stevens, Vishal Urs, Karthik Selvaraj, Gabriel Torres, Gaurish Lakhanpal
0
0
With the increasing prevalence of autonomous vehicles, it is essential for computer vision algorithms to accurately assess road features in real-time. This study explores the LaneSegNet architecture, a new approach to lane topology prediction which integrates topological information with lane-line data to provide a more contextual understanding of road environments. The LaneSegNet architecture includes a feature extractor, lane encoder, lane decoder, and prediction head, leveraging components from ResNet-50, BEVFormer, and various attention mechanisms. We experimented with optimizations to the LaneSegNet architecture through feature extractor modification and transformer encoder-decoder stack modification. We found that modifying the encoder and decoder stacks offered an interesting tradeoff between training time and prediction accuracy, with certain combinations showing promising results. Our implementation, trained on a single NVIDIA Tesla A100 GPU, found that a 2:4 ratio reduced training time by 22.3% with only a 7.1% drop in mean average precision, while a 4:8 ratio increased training time by only 11.1% but improved mean average precision by a significant 23.7%. These results indicate that strategic hyperparameter tuning can yield substantial improvements depending on the resources of the user. This study provides valuable insights for optimizing LaneSegNet according to available computation power, making it more accessible for users with limited resources and increasing the capabilities for users with more powerful resources.
6/26/2024

HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
Zhongyu Xia, ZhiWei Lin, Xinhao Wang, Yongtao Wang, Yun Xing, Shengxiang Qi, Nan Dong, Ming-Hsuan Yang
0
0
Three-dimensional perception from multi-view cameras is a crucial component in autonomous driving systems, which involves multiple tasks like 3D object detection and bird's-eye-view (BEV) semantic segmentation. To improve perception precision, large image encoders, high-resolution images, and long-term temporal inputs have been adopted in recent 3D perception models, bringing remarkable performance gains. However, these techniques are often incompatible in training and inference scenarios due to computational resource constraints. Besides, modern autonomous driving systems prefer to adopt an end-to-end framework for multi-task 3D perception, which can simplify the overall system architecture and reduce the implementation complexity. However, conflict between tasks often arises when optimizing multiple tasks jointly within an end-to-end 3D perception model. To alleviate these issues, we present an end-to-end framework named HENet for multi-task 3D perception in this paper. Specifically, we propose a hybrid image encoding network, using a large image encoder for short-term frames and a small image encoder for long-term temporal frames. Then, we introduce a temporal feature integration module based on the attention mechanism to fuse the features of different frames extracted by the two aforementioned hybrid image encoders. Finally, according to the characteristics of each perception task, we utilize BEV features of different grid sizes, independent BEV encoders, and task decoders for different tasks. Experimental results show that HENet achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, including 3D object detection and BEV semantic segmentation. The source code and models will be released at https://github.com/VDIGPKU/HENet.
5/21/2024

NeRO: Neural Road Surface Reconstruction
Ruibo Wang, Song Zhang, Ping Huang, Donghai Zhang, Haoyu Chen
0
0
Accurately reconstructing road surfaces is pivotal for various applications especially in autonomous driving. This paper introduces a position encoding Multi-Layer Perceptrons (MLPs) framework to reconstruct road surfaces, with input as world coordinates x and y, and output as height, color, and semantic information. The effectiveness of this method is demonstrated through its compatibility with a variety of road height sources like vehicle camera poses, LiDAR point clouds, and SFM point clouds, robust to the semantic noise of images like sparse labels and noise semantic prediction, and fast training speed, which indicates a promising application for rendering road surfaces with semantics, particularly in applications demanding visualization of road surface, 4D labeling, and semantic groupings.
5/29/2024
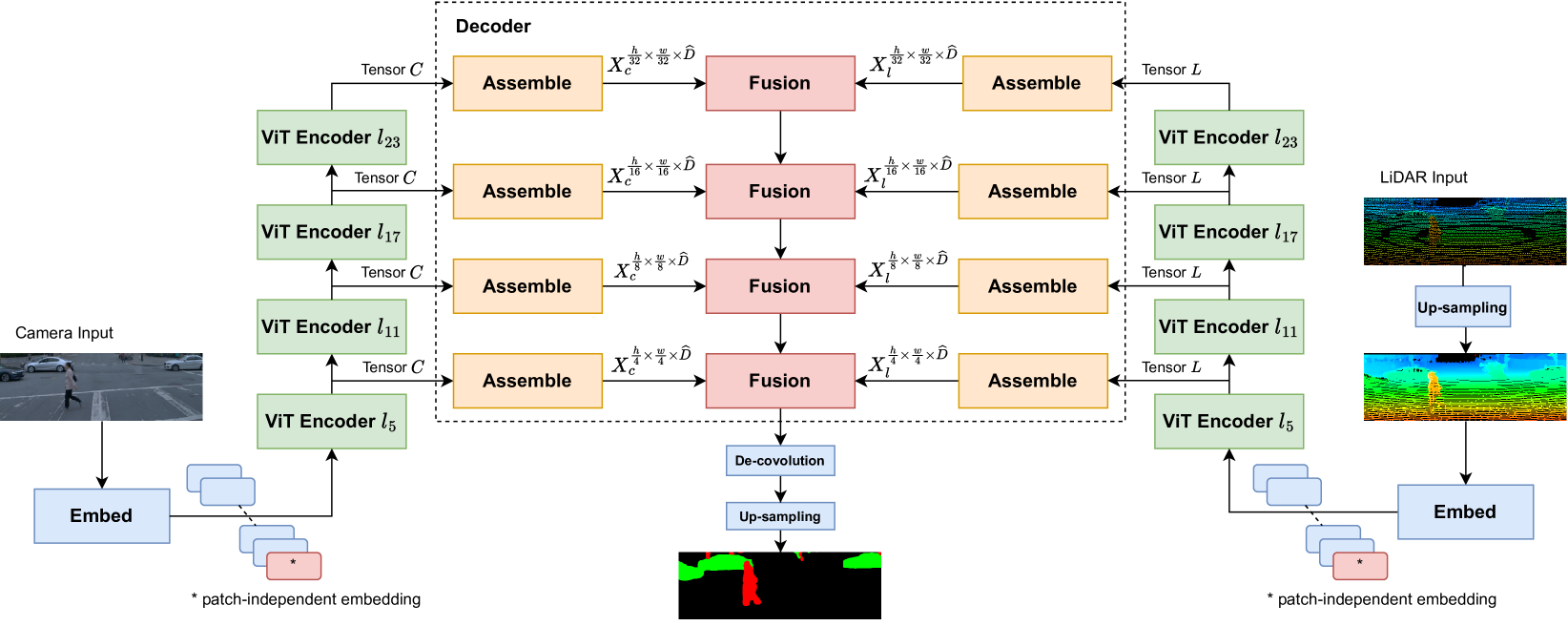
CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation in Autonomous Driving
Junyi Gu, Mauro Bellone, Tom'av{s} Pivov{n}ka, Raivo Sell
0
0
Critical research about camera-and-LiDAR-based semantic object segmentation for autonomous driving significantly benefited from the recent development of deep learning. Specifically, the vision transformer is the novel ground-breaker that successfully brought the multi-head-attention mechanism to computer vision applications. Therefore, we propose a vision-transformer-based network to carry out camera-LiDAR fusion for semantic segmentation applied to autonomous driving. Our proposal uses the novel progressive-assemble strategy of vision transformers on a double-direction network and then integrates the results in a cross-fusion strategy over the transformer decoder layers. Unlike other works in the literature, our camera-LiDAR fusion transformers have been evaluated in challenging conditions like rain and low illumination, showing robust performance. The paper reports the segmentation results over the vehicle and human classes in different modalities: camera-only, LiDAR-only, and camera-LiDAR fusion. We perform coherent controlled benchmark experiments of CLFT against other networks that are also designed for semantic segmentation. The experiments aim to evaluate the performance of CLFT independently from two perspectives: multimodal sensor fusion and backbone architectures. The quantitative assessments show our CLFT networks yield an improvement of up to 10% for challenging dark-wet conditions when comparing with Fully-Convolutional-Neural-Network-based (FCN) camera-LiDAR fusion neural network. Contrasting to the network with transformer backbone but using single modality input, the all-around improvement is 5-10%.
6/21/2024