TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models

0
Sign in to get full access
Overview
- Introduces a framework called TelecomGPT for building telecom-specific large language models (LLMs)
- Addresses the need for specialized LLMs in the telecom industry, which has unique terminology, use cases, and data
- Outlines key components of the TelecomGPT framework, including telecom-specific pretraining, fine-tuning, and evaluation
Plain English Explanation
TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models is a framework that aims to create large language models (LLMs) tailored for the telecom industry. LLMs are powerful AI systems that can understand and generate human-like text, but they are typically trained on general-purpose data, which may not capture the specialized terminology and use cases in the telecom domain.
The researchers behind TelecomGPT recognized that the telecom industry has unique needs and challenges, such as understanding technical specifications, automating customer support, and analyzing network data. To address these needs, they developed a framework to build LLMs that are specifically trained on telecom-related data and fine-tuned for telecom-specific tasks.
The key components of the TelecomGPT framework include:
-
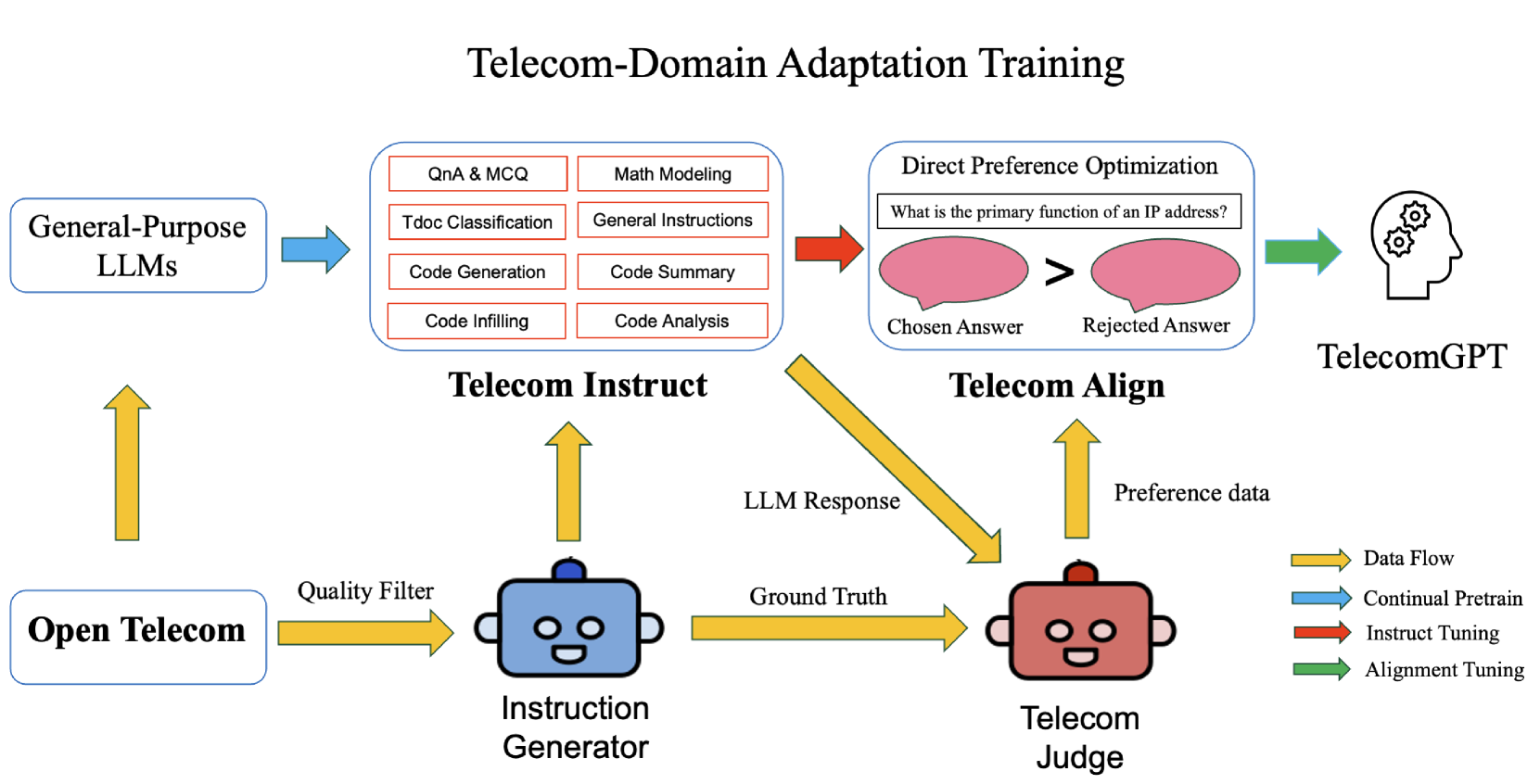
Telecom-Specific Pretraining: The LLM is first trained on a large corpus of telecom-related data, such as technical language processing of telecommunications specifications and open-source telecom datasets, to learn the vocabulary, syntax, and patterns of the telecom domain.
-
Telecom-Specific Fine-Tuning: After the initial pretraining, the LLM is fine-tuned on specific telecom tasks, such as understanding telecom standards and regulations or generating telecom-related content.
-
Telecom-Specific Evaluation: The researchers developed specialized benchmarks and evaluation metrics to assess the performance of the TelecomGPT model on telecom-specific tasks, ensuring that the model meets the industry's unique requirements.
By tailoring the LLM to the telecom domain, the TelecomGPT framework aims to create more accurate and useful language models for telecom companies, enabling them to automate various tasks, improve customer experience, and gain deeper insights from their data.
Technical Explanation
TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models presents a framework for developing large language models (LLMs) that are specifically designed for the telecom industry. The researchers recognized that while LLMs have shown impressive performance on a wide range of natural language processing tasks, their performance may be suboptimal when applied to specialized domains like telecom due to the unique vocabulary, syntax, and use cases.
The TelecomGPT framework consists of three key components:
-
Telecom-Specific Pretraining: The researchers first pretrain the LLM on a large corpus of telecom-related data, including technical specifications, open-source telecom datasets, and industry publications. This allows the model to learn the domain-specific language and patterns inherent in the telecom industry.
-
Telecom-Specific Fine-Tuning: After the initial pretraining, the LLM is fine-tuned on specific telecom tasks, such as understanding and summarizing telecom standards and regulations or generating telecom-related content. This step further specializes the model to the telecom domain and ensures it can perform well on industry-specific applications.
-
Telecom-Specific Evaluation: The researchers developed specialized benchmarks and evaluation metrics to assess the performance of the TelecomGPT model on telecom-specific tasks. This allows them to measure the model's effectiveness in meeting the unique requirements of the telecom industry.
By incorporating these three components, the TelecomGPT framework aims to create LLMs that can better understand and generate telecom-related content, automate various tasks, and provide more accurate insights for telecom companies.
Critical Analysis
The TelecomGPT framework presented in the paper addresses an important need in the telecom industry for specialized language models that can handle the unique terminology, use cases, and data inherent to the domain. The researchers have taken a comprehensive approach by focusing on telecom-specific pretraining, fine-tuning, and evaluation, which is a strength of the framework.
However, the paper does not provide a detailed evaluation of the TelecomGPT model's performance compared to other telecom-specific language models or general-purpose LLMs. It would be helpful to see more quantitative results and benchmarking to understand the actual improvements and limitations of the framework.
Additionally, the paper does not address the potential challenges in curating and accessing the large amounts of telecom-specific data required for pretraining and fine-tuning. This could be a significant hurdle for organizations looking to implement the TelecomGPT framework, especially smaller telecom companies or startups.
It would also be valuable for the researchers to discuss the ethical implications of deploying such specialized language models in the telecom industry, particularly around issues of bias, transparency, and accountability. As these models become more integrated into critical telecom applications, it will be important to ensure they are developed and used responsibly.
Overall, the TelecomGPT framework represents an important step towards addressing the unique needs of the telecom industry in the era of large language models. However, further research and evaluation are needed to fully understand the framework's capabilities and limitations.
Conclusion
TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models introduces a comprehensive framework for developing large language models (LLMs) tailored specifically for the telecom industry. The researchers recognized that the unique terminology, use cases, and data in the telecom domain require specialized models that can better understand and generate telecom-related content.
The TelecomGPT framework addresses this need by incorporating three key components: telecom-specific pretraining, telecom-specific fine-tuning, and telecom-specific evaluation. By following this approach, the researchers aim to create LLMs that can be more effectively deployed in various telecom applications, such as automating customer support, analyzing network data, and understanding technical specifications.
While the framework represents an important step forward, further research and evaluation are needed to fully understand its capabilities and limitations. Addressing potential challenges in data curation and access, as well as the ethical implications of deploying such specialized language models, will be crucial as the telecom industry continues to integrate advanced AI technologies into its operations.
Overall, the TelecomGPT framework showcases the potential for domain-specific LLMs to unlock new opportunities and drive innovation in specialized industries like telecom. As the field of natural language processing continues to evolve, this type of targeted approach may become increasingly important for meeting the unique needs of various sectors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models
Hang Zou, Qiyang Zhao, Yu Tian, Lina Bariah, Faouzi Bader, Thierry Lestable, Merouane Debbah
Large Language Models (LLMs) have the potential to revolutionize the Sixth Generation (6G) communication networks. However, current mainstream LLMs generally lack the specialized knowledge in telecom domain. In this paper, for the first time, we propose a pipeline to adapt any general purpose LLMs to a telecom-specific LLMs. We collect and build telecom-specific pre-train dataset, instruction dataset, preference dataset to perform continual pre-training, instruct tuning and alignment tuning respectively. Besides, due to the lack of widely accepted evaluation benchmarks in telecom domain, we extend existing evaluation benchmarks and proposed three new benchmarks, namely, Telecom Math Modeling, Telecom Open QnA and Telecom Code Tasks. These new benchmarks provide a holistic evaluation of the capabilities of LLMs including math modeling, Open-Ended question answering, code generation, infilling, summarization and analysis in telecom domain. Our fine-tuned LLM TelecomGPT outperforms state of the art (SOTA) LLMs including GPT-4, Llama-3 and Mistral in Telecom Math Modeling benchmark significantly and achieve comparable performance in various evaluation benchmarks such as TeleQnA, 3GPP technical documents classification, telecom code summary and generation and infilling.
Read more7/15/2024
0
Large Language Model (LLM) for Telecommunications: A Comprehensive Survey on Principles, Key Techniques, and Opportunities
Hao Zhou, Chengming Hu, Ye Yuan, Yufei Cui, Yili Jin, Can Chen, Haolun Wu, Dun Yuan, Li Jiang, Di Wu, Xue Liu, Charlie Zhang, Xianbin Wang, Jiangchuan Liu
Large language models (LLMs) have received considerable attention recently due to their outstanding comprehension and reasoning capabilities, leading to great progress in many fields. The advancement of LLM techniques also offers promising opportunities to automate many tasks in the telecommunication (telecom) field. After pre-training and fine-tuning, LLMs can perform diverse downstream tasks based on human instructions, paving the way to artificial general intelligence (AGI)-enabled 6G. Given the great potential of LLM technologies, this work aims to provide a comprehensive overview of LLM-enabled telecom networks. In particular, we first present LLM fundamentals, including model architecture, pre-training, fine-tuning, inference and utilization, model evaluation, and telecom deployment. Then, we introduce LLM-enabled key techniques and telecom applications in terms of generation, classification, optimization, and prediction problems. Specifically, the LLM-enabled generation applications include telecom domain knowledge, code, and network configuration generation. After that, the LLM-based classification applications involve network security, text, image, and traffic classification problems. Moreover, multiple LLM-enabled optimization techniques are introduced, such as automated reward function design for reinforcement learning and verbal reinforcement learning. Furthermore, for LLM-aided prediction problems, we discussed time-series prediction models and multi-modality prediction problems for telecom. Finally, we highlight the challenges and identify the future directions of LLM-enabled telecom networks.
Read more9/17/2024

0
Tele-LLMs: A Series of Specialized Large Language Models for Telecommunications
Ali Maatouk, Kenny Chirino Ampudia, Rex Ying, Leandros Tassiulas
The emergence of large language models (LLMs) has significantly impacted various fields, from natural language processing to sectors like medicine and finance. However, despite their rapid proliferation, the applications of LLMs in telecommunications remain limited, often relying on general-purpose models that lack domain-specific specialization. This lack of specialization results in underperformance, particularly when dealing with telecommunications-specific technical terminology and their associated mathematical representations. This paper addresses this gap by first creating and disseminating Tele-Data, a comprehensive dataset of telecommunications material curated from relevant sources, and Tele-Eval, a large-scale question-and-answer dataset tailored to the domain. Through extensive experiments, we explore the most effective training techniques for adapting LLMs to the telecommunications domain, ranging from examining the division of expertise across various telecommunications aspects to employing parameter-efficient techniques. We also investigate how models of different sizes behave during adaptation and analyze the impact of their training data on this behavior. Leveraging these findings, we develop and open-source Tele-LLMs, the first series of language models ranging from 1B to 8B parameters, specifically tailored for telecommunications. Our evaluations demonstrate that these models outperform their general-purpose counterparts on Tele-Eval while retaining their previously acquired capabilities, thus avoiding the catastrophic forgetting phenomenon.
Read more9/17/2024

0
Using Large Language Models to Understand Telecom Standards
Athanasios Karapantelakis, Mukesh Thakur, Alexandros Nikou, Farnaz Moradi, Christian Orlog, Fitsum Gaim, Henrik Holm, Doumitrou Daniil Nimara, Vincent Huang
The Third Generation Partnership Project (3GPP) has successfully introduced standards for global mobility. However, the volume and complexity of these standards has increased over time, thus complicating access to relevant information for vendors and service providers. Use of Generative Artificial Intelligence (AI) and in particular Large Language Models (LLMs), may provide faster access to relevant information. In this paper, we evaluate the capability of state-of-art LLMs to be used as Question Answering (QA) assistants for 3GPP document reference. Our contribution is threefold. First, we provide a benchmark and measuring methods for evaluating performance of LLMs. Second, we do data preprocessing and fine-tuning for one of these LLMs and provide guidelines to increase accuracy of the responses that apply to all LLMs. Third, we provide a model of our own, TeleRoBERTa, that performs on-par with foundation LLMs but with an order of magnitude less number of parameters. Results show that LLMs can be used as a credible reference tool on telecom technical documents, and thus have potential for a number of different applications from troubleshooting and maintenance, to network operations and software product development.
Read more4/15/2024