TSpec-LLM: An Open-source Dataset for LLM Understanding of 3GPP Specifications

0

Sign in to get full access
Overview
- This paper introduces TSpec-LLM, an open-source dataset for evaluating large language models' (LLMs) understanding of 3GPP telecommunications specifications.
- The dataset consists of 3GPP technical documents and associated question-answer pairs, designed to assess an LLM's ability to comprehend and reason about the content.
- The goal is to provide a standardized benchmark for measuring the performance of LLMs on this specialized domain, which is crucial for applications like automated assistants and document summarization in the telecommunications industry.
Plain English Explanation
The paper presents a new dataset called TSpec-LLM, which is designed to test how well large language models (LLMs) can understand technical documents related to 3GPP telecommunications standards. Telecommunications standards are the guidelines and protocols that define how different communication technologies, like 5G, should work.
The dataset includes a collection of 3GPP technical specifications, along with a set of questions and answers about the content of those documents. The goal is to provide a standardized way to evaluate how well LLMs can comprehend and reason about the information in these specialized technical materials. This is important because LLMs are increasingly being used for tasks like automated assistance and document summarization in the telecom industry, where a deep understanding of the technical details is crucial.
By having a consistent, open-source dataset to test LLM performance on this domain, researchers and developers can more easily compare the capabilities of different language models and identify areas for improvement. This could help advance the development of LLMs that are better equipped to handle the complex terminology and concepts found in telecom industry documents.
Technical Explanation
The TSpec-LLM dataset consists of a collection of 3GPP technical specifications, which are the official standards that define the requirements and protocols for various telecommunications technologies, such as 5G, LTE, and others. These specifications are highly technical and use specialized terminology, making them challenging for language models to comprehend.
To create the dataset, the authors first selected a subset of 3GPP specifications covering a range of telecom-related topics. They then generated question-answer pairs based on the content of these documents, designed to test an LLM's ability to understand and reason about the information. The questions cover various aspects, including factual knowledge, logical reasoning, and language understanding.
The authors evaluated the performance of several popular LLMs, including GPT-3, BERT, and T5, on the TSpec-LLM dataset. Their results showed that while the models performed reasonably well on some tasks, they struggled with others, particularly those that required deep technical knowledge or complex reasoning. This highlights the need for further research and development to improve the language understanding capabilities of LLMs in specialized domains like telecommunications.
Critical Analysis
The TSpec-LLM dataset represents a valuable contribution to the field of language model evaluation, as it provides a standardized benchmark for assessing LLM performance on technical telecom-related content. However, the dataset is limited to a specific subset of 3GPP specifications, and it may not fully capture the breadth and complexity of the entire telecom industry.
Additionally, the authors note that the dataset is primarily focused on factual knowledge and reasoning, and it may not adequately test an LLM's ability to handle more open-ended or creative tasks, such as generating coherent summaries or drafting technical reports. Further research is needed to develop more comprehensive evaluation frameworks that can better assess the real-world capabilities of LLMs in the telecommunications domain.
It is also worth considering the potential biases and limitations of the language models themselves, which may be influenced by the data they were trained on and the specific techniques used in their development. Ongoing efforts to improve the robustness and fairness of LLMs will be crucial for ensuring their effective deployment in critical industries like telecommunications.
Conclusion
The TSpec-LLM dataset provides a valuable tool for researchers and developers working on improving the language understanding capabilities of LLMs in the telecommunications domain. By offering a standardized benchmark for evaluating model performance on technical telecom-related content, the dataset can help advance the development of LLMs that are better equipped to handle the specialized terminology and complex reasoning required in this industry.
As LLMs continue to be integrated into a wide range of applications, including those in the telecommunications sector, ensuring their robust and reliable performance will be of utmost importance. The TSpec-LLM dataset represents an important step in this direction, paving the way for further research and innovation in this critical field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TSpec-LLM: An Open-source Dataset for LLM Understanding of 3GPP Specifications
Rasoul Nikbakht, Mohamed Benzaghta, Giovanni Geraci
Understanding telecom standards involves sorting through numerous technical documents, such as those produced by the 3rd Generation Partnership Project (3GPP), which is time-consuming and labor-intensive. While large language models (LLMs) can assist with the extensive 3GPP knowledge base, an inclusive dataset is crucial for their effective pre-training and fine-tuning. In this paper, we introduce textit{TSpec-LLM}, an open-source comprehensive dataset covering all 3GPP documents from Release 8 to Release 19 (1999--2023). To evaluate its efficacy, we first select a representative sample of 3GPP documents, create corresponding technical questions, and assess the baseline performance of various LLMs. We then incorporate a retrieval-augmented generation (RAG) framework to enhance LLM capabilities by retrieving relevant context from the textit{TSpec-LLM} dataset. Our evaluation shows that using a naive-RAG framework on textit{TSpec-LLM} improves the accuracy of GPT-3.5, Gemini 1.0 Pro, and GPT-4 from 44%, 46%, and 51% to 71%, 75%, and 72%, respectively.
Read more6/7/2024
0
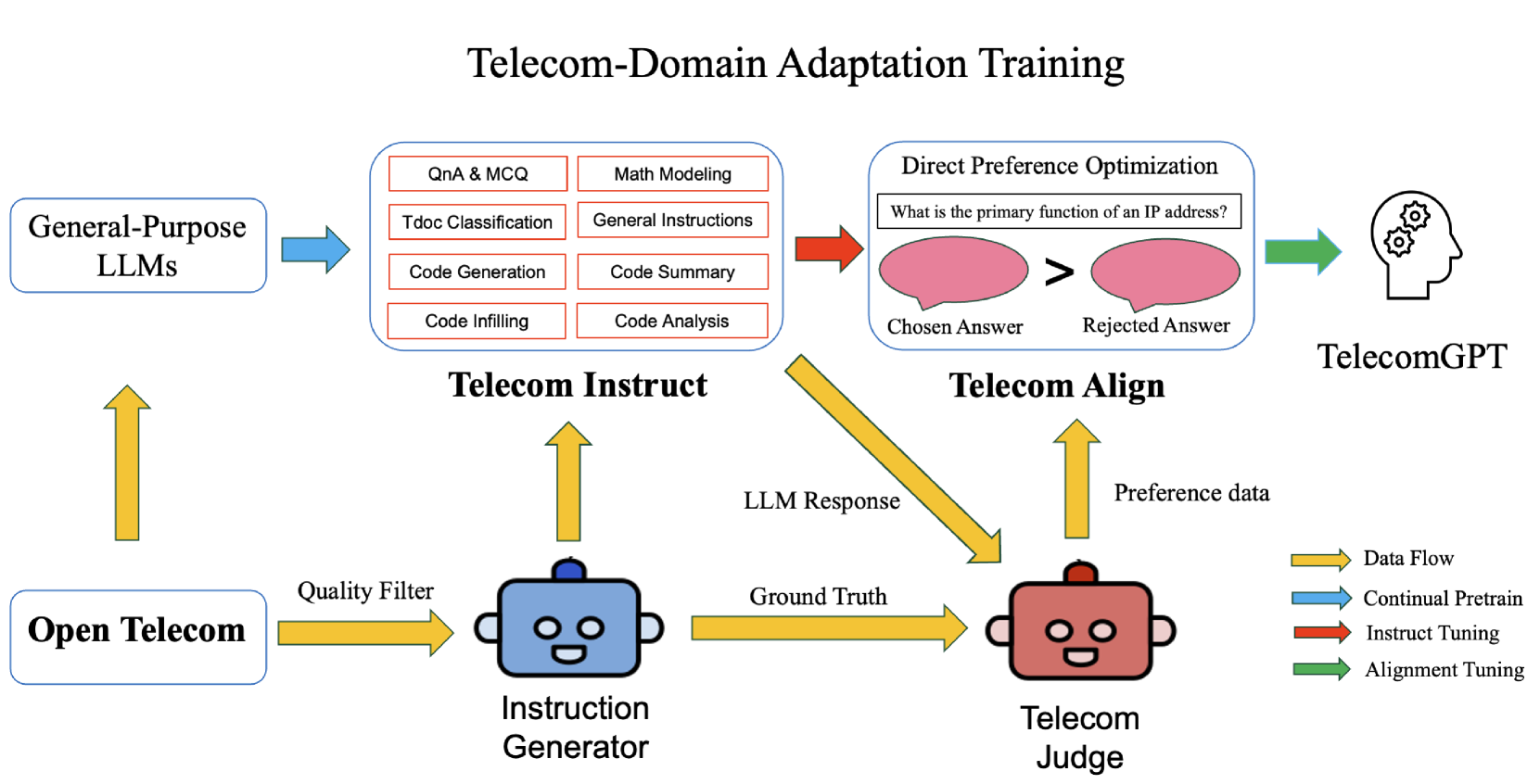
TelecomGPT: A Framework to Build Telecom-Specfic Large Language Models
Hang Zou, Qiyang Zhao, Yu Tian, Lina Bariah, Faouzi Bader, Thierry Lestable, Merouane Debbah
Large Language Models (LLMs) have the potential to revolutionize the Sixth Generation (6G) communication networks. However, current mainstream LLMs generally lack the specialized knowledge in telecom domain. In this paper, for the first time, we propose a pipeline to adapt any general purpose LLMs to a telecom-specific LLMs. We collect and build telecom-specific pre-train dataset, instruction dataset, preference dataset to perform continual pre-training, instruct tuning and alignment tuning respectively. Besides, due to the lack of widely accepted evaluation benchmarks in telecom domain, we extend existing evaluation benchmarks and proposed three new benchmarks, namely, Telecom Math Modeling, Telecom Open QnA and Telecom Code Tasks. These new benchmarks provide a holistic evaluation of the capabilities of LLMs including math modeling, Open-Ended question answering, code generation, infilling, summarization and analysis in telecom domain. Our fine-tuned LLM TelecomGPT outperforms state of the art (SOTA) LLMs including GPT-4, Llama-3 and Mistral in Telecom Math Modeling benchmark significantly and achieve comparable performance in various evaluation benchmarks such as TeleQnA, 3GPP technical documents classification, telecom code summary and generation and infilling.
Read more7/15/2024

0
TelecomRAG: Taming Telecom Standards with Retrieval Augmented Generation and LLMs
Girma M. Yilma, Jose A. Ayala-Romero, Andres Garcia-Saavedra, Xavier Costa-Perez
Large Language Models (LLMs) have immense potential to transform the telecommunications industry. They could help professionals understand complex standards, generate code, and accelerate development. However, traditional LLMs struggle with the precision and source verification essential for telecom work. To address this, specialized LLM-based solutions tailored to telecommunication standards are needed. Retrieval-augmented generation (RAG) offers a way to create precise, fact-based answers. This paper proposes TelecomRAG, a framework for a Telecommunication Standards Assistant that provides accurate, detailed, and verifiable responses. Our implementation, using a knowledge base built from 3GPP Release 16 and Release 18 specification documents, demonstrates how this assistant surpasses generic LLMs, offering superior accuracy, technical depth, and verifiability, and thus significant value to the telecommunications field.
Read more6/12/2024

0
Leveraging Fine-Tuned Retrieval-Augmented Generation with Long-Context Support: For 3GPP Standards
Omar Erak, Nouf Alabbasi, Omar Alhussein, Ismail Lotfi, Amr Hussein, Sami Muhaidat, Merouane Debbah
Recent studies show that large language models (LLMs) struggle with technical standards in telecommunications. We propose a fine-tuned retrieval-augmented generation (RAG) system based on the Phi-2 small language model (SLM) to serve as an oracle for communication networks. Our developed system leverages forward-looking semantic chunking to adaptively determine parsing breakpoints based on embedding similarity, enabling effective processing of diverse document formats. To handle the challenge of multiple similar contexts in technical standards, we employ a re-ranking algorithm to prioritize the most relevant retrieved chunks. Recognizing the limitations of Phi-2's small context window, we implement a recent technique, namely SelfExtend, to expand the context window during inference, which not only boosts the performance but also can accommodate a wider range of user queries and design requirements from customers to specialized technicians. For fine-tuning, we utilize the low-rank adaptation (LoRA) technique to enhance computational efficiency during training and enable effective fine-tuning on small datasets. Our comprehensive experiments demonstrate substantial improvements over existing question-answering approaches in the telecom domain, achieving performance that exceeds larger language models such as GPT-4 (which is about 880 times larger in size). This work presents a novel approach to leveraging SLMs for communication networks, offering a balance of efficiency and performance. This work can serve as a foundation towards agentic language models for networks.
Read more8/22/2024