Temporal Attention for Cross-View Sequential Image Localization

0

Sign in to get full access
Overview
- This paper proposes a temporal attention model for cross-view sequential image localization.
- The model aims to localize a series of ground-level images in a top-down aerial map by exploiting the temporal consistency between consecutive frames.
- The key innovation is the use of temporal attention to capture the dependence between current and past observations.
Plain English Explanation
The paper describes a system that can take a sequence of ground-level photos, such as those taken by a person walking down a street, and use those images to figure out where the person is located on an aerial map. This is a challenging task because the ground-level photos and the aerial map have very different perspectives - the ground-level photos show the world from eye level, while the aerial map shows the world from above.
To solve this problem, the researchers developed a temporal attention model. This model looks at the sequence of ground-level photos and pays attention to how the current photo relates to the previous photos in the sequence. By understanding how the photos are connected over time, the model can better match the ground-level photos to the corresponding location on the aerial map.
The key insight is that the current location on the map is not independent from the previous locations - there is a temporal consistency that the model can exploit. For example, if you see a person walking down a street in a series of photos, you can use that information to infer where they are on the map, even if individual photos might be ambiguous on their own.
Technical Explanation
The paper presents a temporal attention-based model for cross-view sequential image localization. The core idea is to leverage the temporal consistency between consecutive ground-level images to improve localization performance.
The model takes a sequence of ground-level images as input and outputs the corresponding location on an aerial map. It consists of a CNN-based image encoder to extract visual features from each image, and a temporal attention module that captures the dependencies between the current and past observations.
The temporal attention mechanism computes attention weights that highlight relevant past features for localizing the current image. This allows the model to focus on salient elements in the sequence that are predictive of the current location, rather than treating each image in isolation.
The authors evaluate their approach on two cross-view localization datasets, demonstrating improved performance compared to baseline methods that do not utilize temporal information. The results highlight the benefits of modeling the sequential nature of the input data for this task.
Critical Analysis
The paper presents a compelling approach for leveraging temporal consistency in cross-view localization. The temporal attention mechanism is a key innovation that effectively captures the dependencies between consecutive images, which is crucial for this problem.
One potential limitation is that the model assumes the input is a well-structured sequence of images, whereas in practice, the image sequence may be more irregular or incomplete. The authors do not discuss how the model would handle missing frames or out-of-order images, which could be an important consideration for real-world applications.
Additionally, the paper does not provide a thorough analysis of the types of visual features and temporal patterns the model learns to focus on. Understanding these details could provide insights into the model's strengths and weaknesses, and inform future research directions.
Overall, the paper makes a valuable contribution by demonstrating the benefits of temporal modeling for cross-view localization. Further research could explore ways to make the approach more robust to noisy or irregular input data, and provide a deeper analysis of the model's internal workings.
Conclusion
This paper introduces a temporal attention-based model for cross-view sequential image localization. The key innovation is the use of a temporal attention mechanism to capture the dependencies between consecutive ground-level images, allowing the model to better infer the current location on an aerial map.
The results show that leveraging temporal information can significantly improve localization performance compared to approaches that treat each image independently. This work highlights the importance of modeling the sequential nature of the input data for cross-view tasks, and opens up interesting avenues for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Temporal Attention for Cross-View Sequential Image Localization
Dong Yuan, Frederic Maire, Feras Dayoub
This paper introduces a novel approach to enhancing cross-view localization, focusing on the fine-grained, sequential localization of street-view images within a single known satellite image patch, a significant departure from traditional one-to-one image retrieval methods. By expanding to sequential image fine-grained localization, our model, equipped with a novel Temporal Attention Module (TAM), leverages contextual information to significantly improve sequential image localization accuracy. Our method shows substantial reductions in both mean and median localization errors on the Cross-View Image Sequence (CVIS) dataset, outperforming current state-of-the-art single-image localization techniques. Additionally, by adapting the KITTI-CVL dataset into sequential image sets, we not only offer a more realistic dataset for future research but also demonstrate our model's robust generalization capabilities across varying times and areas, evidenced by a 75.3% reduction in mean distance error in cross-view sequential image localization.
Read more8/29/2024

0
Multi-Modal Vision Transformers for Crop Mapping from Satellite Image Time Series
Theresa Follath, David Mickisch, Jan Hemmerling, Stefan Erasmi, Marcel Schwieder, Begum Demir
Using images acquired by different satellite sensors has shown to improve classification performance in the framework of crop mapping from satellite image time series (SITS). Existing state-of-the-art architectures use self-attention mechanisms to process the temporal dimension and convolutions for the spatial dimension of SITS. Motivated by the success of purely attention-based architectures in crop mapping from single-modal SITS, we introduce several multi-modal multi-temporal transformer-based architectures. Specifically, we investigate the effectiveness of Early Fusion, Cross Attention Fusion and Synchronized Class Token Fusion within the Temporo-Spatial Vision Transformer (TSViT). Experimental results demonstrate significant improvements over state-of-the-art architectures with both convolutional and self-attention components.
Read more6/26/2024

0
TemporalStory: Enhancing Consistency in Story Visualization using Spatial-Temporal Attention
Sixiao Zheng, Yanwei Fu
Visual storytelling involves generating a sequence of coherent frames from a textual storyline while maintaining consistency in characters and scenes. Existing autoregressive methods, which rely on previous frame-sentence pairs, struggle with high memory usage, slow generation speeds, and limited context integration. To address these issues, we propose ContextualStory, a novel framework designed to generate coherent story frames and extend frames for story continuation. ContextualStory utilizes Spatially-Enhanced Temporal Attention to capture spatial and temporal dependencies, handling significant character movements effectively. Additionally, we introduces a Storyline Contextualizer to enrich context in storyline embedding and a StoryFlow Adapter to measure scene changes between frames for guiding model. Extensive experiments on PororoSV and FlintstonesSV benchmarks demonstrate that ContextualStory significantly outperforms existing methods in both story visualization and story continuation.
Read more8/22/2024
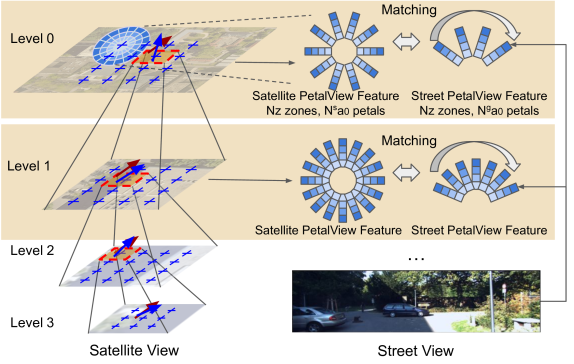
0
PetalView: Fine-grained Location and Orientation Extraction of Street-view Images via Cross-view Local Search with Supplementary Materials
Wenmiao Hu, Yichen Zhang, Yuxuan Liang, Xianjing Han, Yifang Yin, Hannes Kruppa, See-Kiong Ng, Roger Zimmermann
Satellite-based street-view information extraction by cross-view matching refers to a task that extracts the location and orientation information of a given street-view image query by using one or multiple geo-referenced satellite images. Recent work has initiated a new research direction to find accurate information within a local area covered by one satellite image centered at a location prior (e.g., from GPS). It can be used as a standalone solution or complementary step following a large-scale search with multiple satellite candidates. However, these existing works require an accurate initial orientation (angle) prior (e.g., from IMU) and/or do not efficiently search through all possible poses. To allow efficient search and to give accurate prediction regardless of the existence or the accuracy of the angle prior, we present PetalView extractors with multi-scale search. The PetalView extractors give semantically meaningful features that are equivalent across two drastically different views, and the multi-scale search strategy efficiently inspects the satellite image from coarse to fine granularity to provide sub-meter and sub-degree precision extraction. Moreover, when an angle prior is given, we propose a learnable prior angle mixer to utilize this information. Our method obtains the best performance on the VIGOR dataset and successfully improves the performance on KITTI dataset test 1 set with the recall within 1 meter (r@1m) for location estimation to 68.88% and recall within 1 degree (r@1d) 21.10% when no angle prior is available, and with angle prior achieves stable estimations at r@1m and r@1d above 70% and 21%, up to a 40-degree noise level.
Read more6/21/2024