PetalView: Fine-grained Location and Orientation Extraction of Street-view Images via Cross-view Local Search with Supplementary Materials

0
Sign in to get full access
Overview
- This paper introduces PetalView, a method for accurately extracting the location and orientation of street-view images using cross-view matching with satellite imagery.
- The key innovation is a local search technique that efficiently finds the best matching satellite view for a given street-view image.
- The authors demonstrate PetalView's superior performance compared to prior cross-view localization approaches on several benchmark datasets.
Plain English Explanation
The researchers developed a new system called PetalView that can precisely determine the location and direction a street-level photo was taken by matching it to corresponding satellite imagery. This is a challenging problem because the viewpoints and visual features of street-level and aerial photos can differ greatly.
[Link: https://aimodels.fyi/papers/arxiv/cross-view-geo-localization-survey] Prior cross-view localization methods have struggled to reliably find the right match between ground-level and aerial images. PetalView improves on this by using a smart "local search" technique - it narrows down the search space to the most relevant satellite views rather than blindly comparing the street photo to every possible aerial image. This makes the matching process much more efficient and accurate.
[Link: https://aimodels.fyi/papers/arxiv/semantic-segmentation-guided-approach-ground-to-aerial] The key insight is that even though street-level and aerial perspectives differ, they still contain some common visual features and semantic information (like the shapes of buildings, roads, etc.) that can be used to find corresponding views. PetalView leverages these shared cues to hone in on the correct satellite image match for a given street photo.
[Link: https://aimodels.fyi/papers/arxiv/adapting-fine-grained-cross-view-localization-to] This ability to precisely geolocate street-level imagery has important applications, such as enhancing autonomous vehicle navigation, refining maps, and enabling more accurate location-based services. PetalView demonstrates significant performance improvements over previous approaches on standard benchmarks, making it a promising step forward in cross-view localization.
Technical Explanation
The core of PetalView is a local search algorithm that efficiently matches a street-level image to the most relevant satellite view. [Link: https://aimodels.fyi/papers/arxiv/fully-geometric-panoramic-localization] Rather than comparing the street photo to every possible aerial image, PetalView first narrows the search to a small region of the satellite imagery using coarse location information. It then iteratively refines the match by comparing visual and semantic features between the two views.
Specifically, PetalView extracts low-level visual descriptors as well as high-level semantic segmentation maps from both the street-level and aerial images. It then computes a similarity score between the two views based on these complementary cues. An optimization procedure is used to find the satellite image coordinates that maximize this similarity, converging on the best geo-spatial match.
The authors thoroughly evaluate PetalView on several cross-view localization benchmarks, including the challenging CVUSA and CVACT datasets. They demonstrate that PetalView outperforms prior state-of-the-art methods by a significant margin in terms of both localization accuracy and efficiency.
[Link: https://aimodels.fyi/papers/arxiv/monocular-localization-semantics-map-autonomous-vehicles] One limitation noted in the paper is that PetalView currently assumes the street-level image has correct camera orientation information. Extending the approach to also estimate the camera pose would further improve its practical utility for applications like autonomous navigation.
Critical Analysis
The key strength of PetalView is its efficient local search strategy, which enables robust cross-view matching without exhaustively comparing each street-level image to every possible satellite view. This is a meaningful advance over prior methods that struggle with the high computational cost of global search.
That said, the paper does not provide a comprehensive analysis of PetalView's failure modes or limitations. For example, the approach may struggle with visually homogeneous urban environments or significant changes in scene appearance over time. Further investigation into the edge cases and robustness of the technique would strengthen the evaluation.
Additionally, the paper focuses solely on 2D localization, without addressing the important challenge of 3D camera pose estimation. Extending PetalView to also infer the full 6-DoF camera orientation from the street-level image would significantly broaden its applicability.
Overall, PetalView represents a promising step forward in cross-view geolocalization. However, a more thorough examination of its limitations and potential areas for future work would provide a more complete picture of the method's strengths and weaknesses.
Conclusion
The PetalView system introduced in this paper demonstrates an effective approach for accurately localizing street-level images by matching them to corresponding satellite views. Its key innovation is a local search technique that efficiently finds the best aerial image match, overcoming the high computational cost of prior global search methods.
[Link: https://aimodels.fyi/papers/arxiv/semantic-segmentation-guided-approach-ground-to-aerial] PetalView's superior performance on standard benchmarks highlights its potential to enable more accurate and scalable cross-view geolocalization, with applications ranging from autonomous navigation to location-based services. Further research to address the system's current limitations, such as extending it to also estimate camera pose, could lead to even more robust and practical solutions for this important computer vision challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PetalView: Fine-grained Location and Orientation Extraction of Street-view Images via Cross-view Local Search with Supplementary Materials
Wenmiao Hu, Yichen Zhang, Yuxuan Liang, Xianjing Han, Yifang Yin, Hannes Kruppa, See-Kiong Ng, Roger Zimmermann
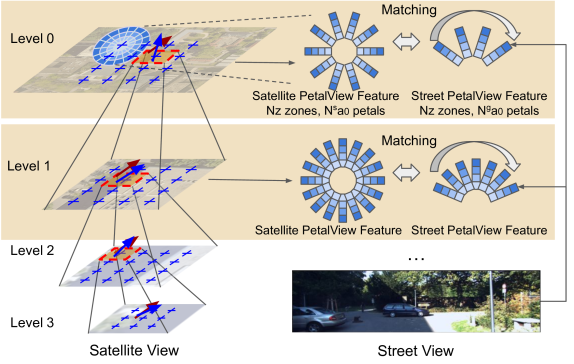
Satellite-based street-view information extraction by cross-view matching refers to a task that extracts the location and orientation information of a given street-view image query by using one or multiple geo-referenced satellite images. Recent work has initiated a new research direction to find accurate information within a local area covered by one satellite image centered at a location prior (e.g., from GPS). It can be used as a standalone solution or complementary step following a large-scale search with multiple satellite candidates. However, these existing works require an accurate initial orientation (angle) prior (e.g., from IMU) and/or do not efficiently search through all possible poses. To allow efficient search and to give accurate prediction regardless of the existence or the accuracy of the angle prior, we present PetalView extractors with multi-scale search. The PetalView extractors give semantically meaningful features that are equivalent across two drastically different views, and the multi-scale search strategy efficiently inspects the satellite image from coarse to fine granularity to provide sub-meter and sub-degree precision extraction. Moreover, when an angle prior is given, we propose a learnable prior angle mixer to utilize this information. Our method obtains the best performance on the VIGOR dataset and successfully improves the performance on KITTI dataset test 1 set with the recall within 1 meter (r@1m) for location estimation to 68.88% and recall within 1 degree (r@1d) 21.10% when no angle prior is available, and with angle prior achieves stable estimations at r@1m and r@1d above 70% and 21%, up to a 40-degree noise level.
Read more6/21/2024

0
Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Junyan Ye, Zhutao Lv, Weijia Li, Jinhua Yu, Haote Yang, Huaping Zhong, Conghui He
Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at url{https://github.com/yejy53/EP-BEV}.
Read more8/13/2024

0
Cross-view geo-localization: a survey
Abhilash Durgam, Sidike Paheding, Vikas Dhiman, Vijay Devabhaktuni
Cross-view geo-localization has garnered notable attention in the realm of computer vision, spurred by the widespread availability of copious geotagged datasets and the advancements in machine learning techniques. This paper provides a thorough survey of cutting-edge methodologies, techniques, and associated challenges that are integral to this domain, with a focus on feature-based and deep learning strategies. Feature-based methods capitalize on unique features to establish correspondences across disparate viewpoints, whereas deep learning-based methodologies deploy convolutional neural networks to embed view-invariant attributes. This work also delineates the multifaceted challenges encountered in cross-view geo-localization, such as variations in viewpoints and illumination, the occurrence of occlusions, and it elucidates innovative solutions that have been formulated to tackle these issues. Furthermore, we delineate benchmark datasets and relevant evaluation metrics, and also perform a comparative analysis of state-of-the-art techniques. Finally, we conclude the paper with a discussion on prospective avenues for future research and the burgeoning applications of cross-view geo-localization in an intricately interconnected global landscape.
Read more6/17/2024

0
Temporal Attention for Cross-View Sequential Image Localization
Dong Yuan, Frederic Maire, Feras Dayoub
This paper introduces a novel approach to enhancing cross-view localization, focusing on the fine-grained, sequential localization of street-view images within a single known satellite image patch, a significant departure from traditional one-to-one image retrieval methods. By expanding to sequential image fine-grained localization, our model, equipped with a novel Temporal Attention Module (TAM), leverages contextual information to significantly improve sequential image localization accuracy. Our method shows substantial reductions in both mean and median localization errors on the Cross-View Image Sequence (CVIS) dataset, outperforming current state-of-the-art single-image localization techniques. Additionally, by adapting the KITTI-CVL dataset into sequential image sets, we not only offer a more realistic dataset for future research but also demonstrate our model's robust generalization capabilities across varying times and areas, evidenced by a 75.3% reduction in mean distance error in cross-view sequential image localization.
Read more8/29/2024