Tender: Accelerating Large Language Models via Tensor Decomposition and Runtime Requantization
2406.12930
0
0

Abstract
Large language models (LLMs) demonstrate outstanding performance in various tasks in machine learning and have thus become one of the most important workloads in today's computing landscape. However, deploying LLM inference poses challenges due to the high compute and memory requirements stemming from the enormous model size and the difficulty of running it in the integer pipelines. In this paper, we present Tender, an algorithm-hardware co-design solution that enables efficient deployment of LLM inference at low precision. Based on our analysis of outlier values in LLMs, we propose a decomposed quantization technique in which the scale factors of decomposed matrices are powers of two apart. The proposed scheme allows us to avoid explicit requantization (i.e., dequantization/quantization) when accumulating the partial sums from the decomposed matrices, with a minimal extension to the commodity tensor compute hardware. Our evaluation shows that Tender achieves higher accuracy and inference performance compared to the state-of-the-art methods while also being significantly less intrusive to the existing accelerators.
Create account to get full access
Overview
- The paper "Tender: Accelerating Large Language Models via Tensor Decomposition and Runtime Requantization" explores techniques to speed up the inference of large language models (LLMs).
- The researchers propose two key approaches: tensor decomposition and runtime requantization.
- Tensor decomposition involves breaking down the large weight matrices in LLMs into smaller, more efficient representations.
- Runtime requantization reduces the precision of model computations during inference, leading to faster processing without significant accuracy loss.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have revolutionized natural language processing, but they can be computationally expensive and slow to run, especially on resource-constrained devices. The researchers behind the "Tender" paper set out to find ways to speed up LLM inference without compromising their performance.
One of the key ideas they explored is tensor decomposition. Just like how you can break down a complicated math problem into simpler steps, the researchers found a way to break down the large weight matrices inside LLMs into smaller, more efficient pieces. This allows the models to run faster without losing accuracy.
The other main technique they used is runtime requantization. Imagine you're trying to fit a lot of information onto a small storage device - you might decide to store the information using fewer bits, even though that means some precision is lost. The researchers applied a similar idea to LLMs, reducing the precision of the computations during inference. This makes the models run faster, while still maintaining high accuracy.
By combining these two techniques, the researchers were able to significantly accelerate the inference of large language models, potentially enabling their use in a wider range of applications, including on resource-constrained devices.
Technical Explanation
The paper proposes two key techniques to accelerate the inference of large language models (LLMs):
-
Tensor Decomposition: The researchers leveraged tensor decomposition to factorize the large weight matrices in LLMs into smaller, more efficient representations. This allows for faster model computation without significant accuracy loss.
-
Runtime Requantization: The paper introduces runtime requantization, which reduces the precision of model computations during inference. This leads to faster processing while maintaining high model accuracy.
The researchers conducted extensive experiments to evaluate their techniques, comparing against other quantization strategies and low-rank adaptation methods. They demonstrated significant speedups in LLM inference, with only minor accuracy degradation.
The tensor decomposition approach involves basis selection and low-rank decomposition of the pre-trained model weights, allowing for efficient matrix-vector multiplications during inference. The runtime requantization technique dynamically adjusts the precision of computations to further optimize for speed without compromising quality.
Critical Analysis
The "Tender" paper presents a compelling approach to accelerating large language models, addressing an important challenge in the field of natural language processing. The researchers have demonstrated the effectiveness of their techniques through thorough experimentation and comparison to existing methods.
However, the paper does not delve deeply into the potential limitations or caveats of their approach. For example, it would be valuable to understand how the techniques scale with increasing model size and complexity, or how they might perform on a wider range of LLM architectures and tasks.
Additionally, the paper could have discussed the potential trade-offs between the degree of acceleration and the resultant model accuracy. It would be interesting to see how the researchers' methods perform when pushed to the limits of speed, and whether there are any diminishing returns or critical thresholds that need to be considered.
Overall, the "Tender" paper makes a valuable contribution to the ongoing efforts to optimize the performance of large language models. The techniques presented have the potential to enable the deployment of these powerful models in a wider range of real-world applications, including on resource-constrained devices. However, further research and analysis could help to fully understand the capabilities and limitations of the proposed approaches.
Conclusion
The "Tender" paper introduces two innovative techniques, tensor decomposition and runtime requantization, to significantly accelerate the inference of large language models. By breaking down the large weight matrices into more efficient representations and dynamically adjusting the precision of computations, the researchers were able to achieve substantial speedups without substantial accuracy degradation.
These findings have important implications for the broader adoption and deployment of large language models, potentially enabling their use in a wider range of applications, including on resource-constrained devices. As the field of natural language processing continues to evolve, the techniques presented in this paper could serve as a valuable foundation for further optimizing the performance and accessibility of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SDQ: Sparse Decomposed Quantization for LLM Inference
Geonhwa Jeong, Po-An Tsai, Stephen W. Keckler, Tushar Krishna
0
0
Recently, large language models (LLMs) have shown surprising performance in task-specific workloads as well as general tasks with the given prompts. However, to achieve unprecedented performance, recent LLMs use billions to trillions of parameters, which hinder the wide adaptation of those models due to their extremely large compute and memory requirements. To resolve the issue, various model compression methods are being actively investigated. In this work, we propose SDQ (Sparse Decomposed Quantization) to exploit both structured sparsity and quantization to achieve both high compute and memory efficiency. From our evaluations, we observe that SDQ can achieve 4x effective compute throughput with <1% quality drop.
6/21/2024
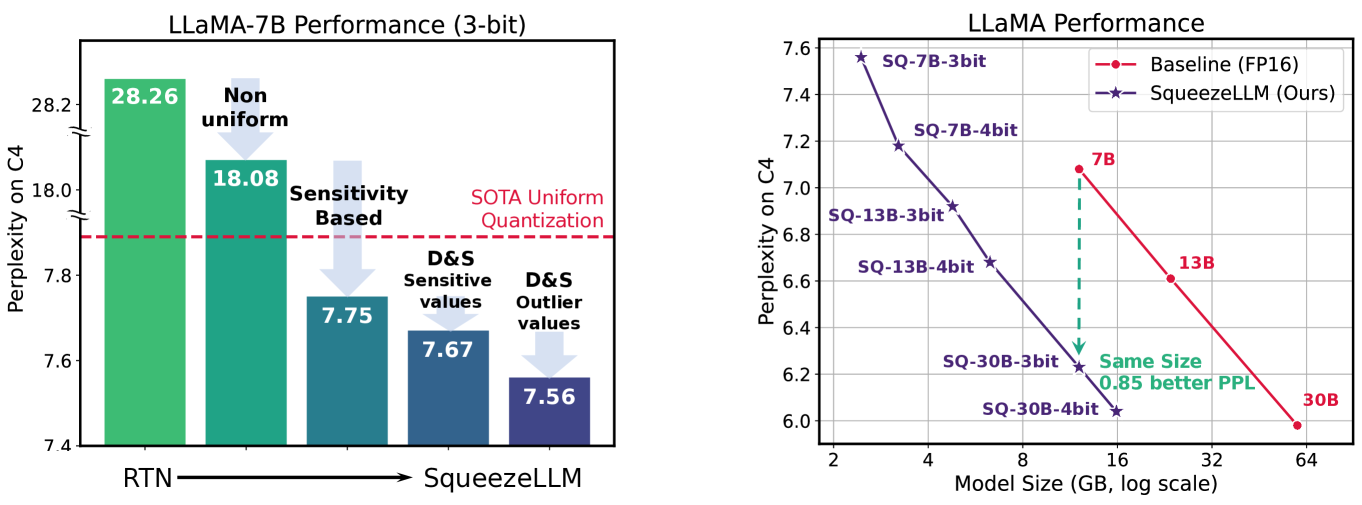
SqueezeLLM: Dense-and-Sparse Quantization
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer
0
0
Generative Large Language Models (LLMs) have demonstrated remarkable results for a wide range of tasks. However, deploying these models for inference has been a significant challenge due to their unprecedented resource requirements. This has forced existing deployment frameworks to use multi-GPU inference pipelines, which are often complex and costly, or to use smaller and less performant models. In this work, we demonstrate that the main bottleneck for generative inference with LLMs is memory bandwidth, rather than compute, specifically for single batch inference. While quantization has emerged as a promising solution by representing weights with reduced precision, previous efforts have often resulted in notable performance degradation. To address this, we introduce SqueezeLLM, a post-training quantization framework that not only enables lossless compression to ultra-low precisions of up to 3-bit, but also achieves higher quantization performance under the same memory constraint. Our framework incorporates two novel ideas: (i) sensitivity-based non-uniform quantization, which searches for the optimal bit precision assignment based on second-order information; and (ii) the Dense-and-Sparse decomposition that stores outliers and sensitive weight values in an efficient sparse format. When applied to the LLaMA models, our 3-bit quantization significantly reduces the perplexity gap from the FP16 baseline by up to 2.1x as compared to the state-of-the-art methods with the same memory requirement. Furthermore, when deployed on an A6000 GPU, our quantized models achieve up to 2.3x speedup compared to the baseline. Our code is available at https://github.com/SqueezeAILab/SqueezeLLM.
6/6/2024

A Comprehensive Evaluation of Quantization Strategies for Large Language Models
Renren Jin, Jiangcun Du, Wuwei Huang, Wei Liu, Jian Luan, Bin Wang, Deyi Xiong
0
0
Increasing the number of parameters in large language models (LLMs) usually improves performance in downstream tasks but raises compute and memory costs, making deployment difficult in resource-limited settings. Quantization techniques, which reduce the bits needed for model weights or activations with minimal performance loss, have become popular due to the rise of LLMs. However, most quantization studies use pre-trained LLMs, and the impact of quantization on instruction-tuned LLMs and the relationship between perplexity and benchmark performance of quantized LLMs are not well understood. Evaluation of quantized LLMs is often limited to language modeling and a few classification tasks, leaving their performance on other benchmarks unclear. To address these gaps, we propose a structured evaluation framework consisting of three critical dimensions: (1) knowledge & capacity, (2) alignment, and (3) efficiency, and conduct extensive experiments across ten diverse benchmarks. Our experimental results indicate that LLMs with 4-bit quantization can retain performance comparable to their non-quantized counterparts, and perplexity can serve as a proxy metric for quantized LLMs on most benchmarks. Furthermore, quantized LLMs with larger parameter scales can outperform smaller LLMs. Despite the memory savings achieved through quantization, it can also slow down the inference speed of LLMs. Consequently, substantial engineering efforts and hardware support are imperative to achieve a balanced optimization of decoding speed and memory consumption in the context of quantized LLMs.
6/7/2024

Basis Selection: Low-Rank Decomposition of Pretrained Large Language Models for Target Applications
Yang Li, Changsheng Zhao, Hyungtak Lee, Ernie Chang, Yangyang Shi, Vikas Chandra
0
0
Large language models (LLMs) significantly enhance the performance of various applications, but they are computationally intensive and energy-demanding. This makes it challenging to deploy them on devices with limited resources, such as personal computers and mobile/wearable devices, and results in substantial inference costs in resource-rich environments like cloud servers. To extend the use of LLMs, we introduce a low-rank decomposition approach to effectively compress these models, tailored to the requirements of specific applications. We observe that LLMs pretrained on general datasets contain many redundant components not needed for particular applications. Our method focuses on identifying and removing these redundant parts, retaining only the necessary elements for the target applications. Specifically, we represent the weight matrices of LLMs as a linear combination of base components. We then prune the irrelevant bases and enhance the model with new bases beneficial for specific applications. Deep compression results on the Llama 2-7b and -13B models, conducted on target applications including mathematical reasoning and code generation, show that our method significantly reduces model size while maintaining comparable accuracy to state-of-the-art low-rank compression techniques.
5/28/2024