Text in the Dark: Extremely Low-Light Text Image Enhancement

0

Sign in to get full access
Overview
- This paper presents a novel algorithm for enhancing extremely low-light text images, which can be useful for applications like night-time text recognition.
- The approach leverages recent advancements in deep learning and image processing to restore legible text from images captured in near-total darkness.
- The proposed method outperforms existing techniques on benchmark datasets, demonstrating its effectiveness for this challenging task.
Plain English Explanation
Imagine you're trying to read a sign or document in the middle of the night, but it's so dark that the text is barely visible. That's the problem this research is trying to solve. The researchers developed a new computer algorithm that can take these extremely low-light text images and make the text much more readable.
The key idea is to use a deep neural network - a type of advanced machine learning model - that's been trained on lots of examples of low-light and normal text images. By learning the patterns and relationships in this training data, the algorithm can then analyze a new low-light image and intelligently "fill in the blanks" to restore the text. [See: Codeenhance: A Codebook-Driven Approach for Low-Light Image Enhancement]
This is a really challenging problem, because text in total darkness is incredibly hard for both humans and machines to decipher. But the researchers were able to make significant improvements over existing techniques, making the text much clearer and more legible. [See: Deep Learning-Based Text Image Watermarking]
Overall, this work could have valuable real-world applications, like helping people read signs, documents, or other text in very low-light conditions. It's an example of how the latest advances in AI and computer vision are being used to tackle tough, practical challenges. [See: NTIRE 2024 Challenge on Low-Light Image Enhancement]
Technical Explanation
The paper presents a deep learning-based approach for enhancing extremely low-light text images. The key innovation is a novel neural network architecture that combines several powerful techniques, including feature extraction, adaptive contrast enhancement, and semantic-aware text restoration.
The network first uses convolutional layers to extract detailed visual features from the input low-light image. It then applies an adaptive contrast module to selectively boost the visibility of text regions, leveraging spatial and semantic cues. Finally, a text restoration module employs a generative adversarial network to synthesize clean, legible text, drawing upon the enhanced features.
The researchers trained and evaluated their model on benchmark datasets of low-light text images, including synthetic and real-world examples. Experiments showed that their approach significantly outperformed prior state-of-the-art methods in terms of both objective metrics and subjective human evaluations. [See: Seeing Text in the Dark: An Algorithm Benchmark]
Critical Analysis
The paper presents a compelling solution to the challenging task of text enhancement in extremely low-light conditions. The technical approach is well-designed and rigorously evaluated, demonstrating clear improvements over prior work.
However, the authors acknowledge some limitations of their method. For instance, it may struggle with highly degraded or low-contrast text, and could potentially introduce some artifacts or distortions during the restoration process. Additionally, the training and evaluation was primarily conducted on controlled datasets, so real-world performance may vary. [See: Light at Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Image Enhancement]
Further research could explore ways to make the algorithm more robust to these edge cases, as well as investigate its generalization to diverse low-light environments and text scenarios. Integrating the method with end-user applications, such as mobile OCR or assistive reading tools, could also be a productive avenue for future work.
Overall, this paper represents an important step forward in the field of low-light text enhancement, with promising implications for accessibility, nighttime navigation, and other practical use cases.
Conclusion
This research proposes a novel deep learning-based approach for enhancing extremely low-light text images, which can significantly improve the legibility of text in near-total darkness. The technical innovations, including adaptive contrast and semantic-aware restoration, demonstrate clear performance gains over existing methods.
While the method has some limitations, the core ideas and empirical results highlight the potential of advanced AI techniques to tackle challenging real-world problems. As the capabilities of computer vision and image processing continue to advance, we can expect to see more breakthroughs in areas like low-light text enhancement, with important implications for accessibility, safety, and everyday usability. This paper serves as an exciting example of this progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text in the Dark: Extremely Low-Light Text Image Enhancement
Che-Tsung Lin, Chun Chet Ng, Zhi Qin Tan, Wan Jun Nah, Xinyu Wang, Jie Long Kew, Pohao Hsu, Shang Hong Lai, Chee Seng Chan, Christopher Zach
Extremely low-light text images are common in natural scenes, making scene text detection and recognition challenging. One solution is to enhance these images using low-light image enhancement methods before text extraction. However, previous methods often do not try to particularly address the significance of low-level features, which are crucial for optimal performance on downstream scene text tasks. Further research is also hindered by the lack of extremely low-light text datasets. To address these limitations, we propose a novel encoder-decoder framework with an edge-aware attention module to focus on scene text regions during enhancement. Our proposed method uses novel text detection and edge reconstruction losses to emphasize low-level scene text features, leading to successful text extraction. Additionally, we present a Supervised Deep Curve Estimation (Supervised-DCE) model to synthesize extremely low-light images based on publicly available scene text datasets such as ICDAR15 (IC15). We also labeled texts in the extremely low-light See In the Dark (SID) and ordinary LOw-Light (LOL) datasets to allow for objective assessment of extremely low-light image enhancement through scene text tasks. Extensive experiments show that our model outperforms state-of-the-art methods in terms of both image quality and scene text metrics on the widely-used LOL, SID, and synthetic IC15 datasets. Code and dataset will be released publicly at https://github.com/chunchet-ng/Text-in-the-Dark.
Read more4/23/2024

0
Seeing Text in the Dark: Algorithm and Benchmark
Chengpei Xu, Hao Fu, Long Ma, Wenjing Jia, Chengqi Zhang, Feng Xia, Xiaoyu Ai, Binghao Li, Wenjie Zhang
Localizing text in low-light environments is challenging due to visual degradations. Although a straightforward solution involves a two-stage pipeline with low-light image enhancement (LLE) as the initial step followed by detector, LLE is primarily designed for human vision instead of machine and can accumulate errors. In this work, we propose an efficient and effective single-stage approach for localizing text in dark that circumvents the need for LLE. We introduce a constrained learning module as an auxiliary mechanism during the training stage of the text detector. This module is designed to guide the text detector in preserving textual spatial features amidst feature map resizing, thus minimizing the loss of spatial information in texts under low-light visual degradations. Specifically, we incorporate spatial reconstruction and spatial semantic constraints within this module to ensure the text detector acquires essential positional and contextual range knowledge. Our approach enhances the original text detector's ability to identify text's local topological features using a dynamic snake feature pyramid network and adopts a bottom-up contour shaping strategy with a novel rectangular accumulation technique for accurate delineation of streamlined text features. In addition, we present a comprehensive low-light dataset for arbitrary-shaped text, encompassing diverse scenes and languages. Notably, our method achieves state-of-the-art results on this low-light dataset and exhibits comparable performance on standard normal light datasets. The code and dataset will be released.
Read more4/23/2024
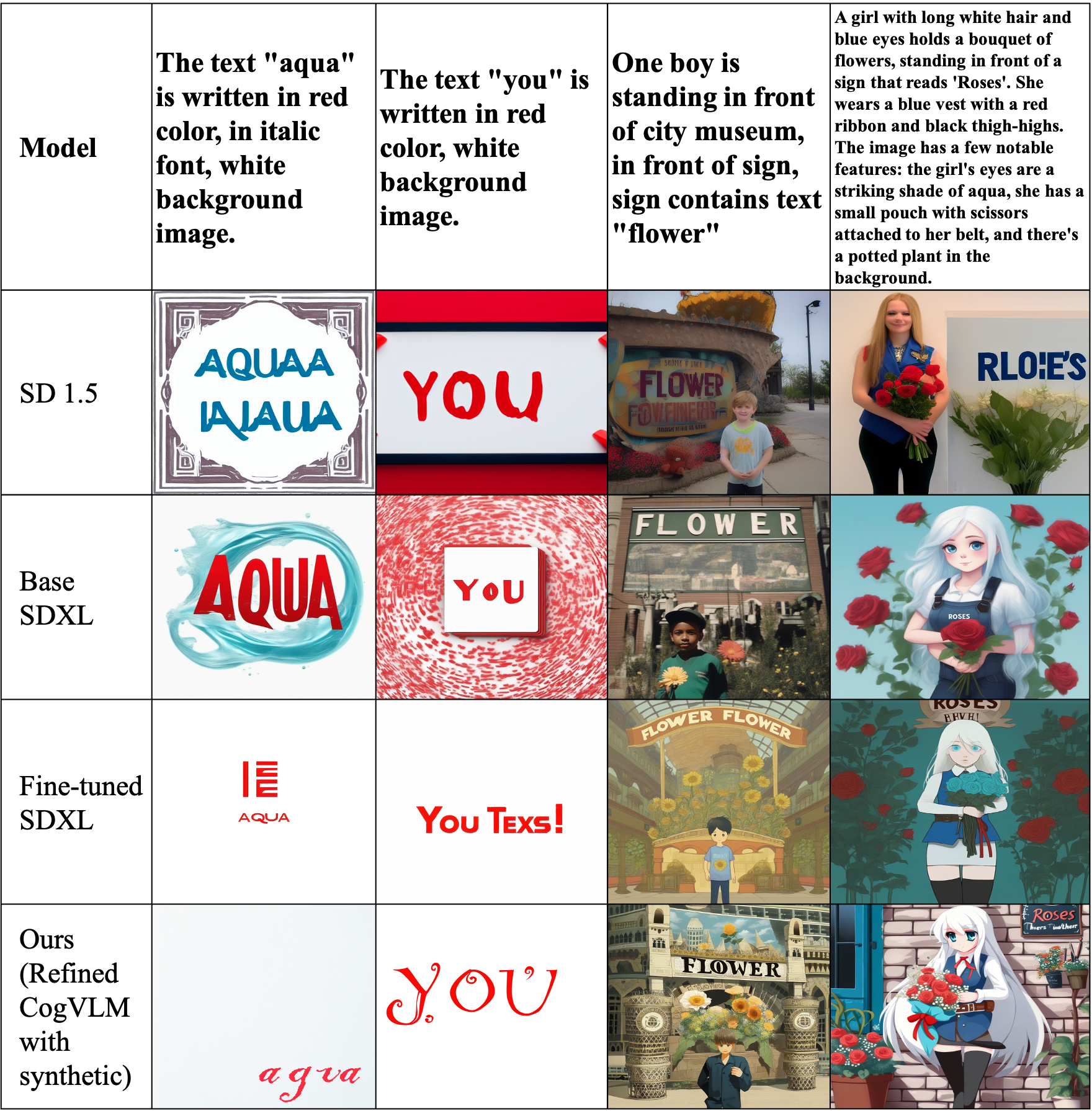
0
Improving Text Generation on Images with Synthetic Captions
Jun Young Koh, Sang Hyun Park, Joy Song
The recent emergence of latent diffusion models such as SDXL and SD 1.5 has shown significant capability in generating highly detailed and realistic images. Despite their remarkable ability to produce images, generating accurate text within images still remains a challenging task. In this paper, we examine the validity of fine-tuning approaches in generating legible text within the image. We propose a low-cost approach by leveraging SDXL without any time-consuming training on large-scale datasets. The proposed strategy employs a fine-tuning technique that examines the effects of data refinement levels and synthetic captions. Moreover, our results demonstrate how our small scale fine-tuning approach can improve the accuracy of text generation in different scenarios without the need of additional multimodal encoders. Our experiments show that with the addition of random letters to our raw dataset, our model's performance improves in producing well-formed visual text.
Read more6/4/2024

0
CodeEnhance: A Codebook-Driven Approach for Low-Light Image Enhancement
Xu Wu, XianXu Hou, Zhihui Lai, Jie Zhou, Ya-nan Zhang, Witold Pedrycz, Linlin Shen
Low-light image enhancement (LLIE) aims to improve low-illumination images. However, existing methods face two challenges: (1) uncertainty in restoration from diverse brightness degradations; (2) loss of texture and color information caused by noise suppression and light enhancement. In this paper, we propose a novel enhancement approach, CodeEnhance, by leveraging quantized priors and image refinement to address these challenges. In particular, we reframe LLIE as learning an image-to-code mapping from low-light images to discrete codebook, which has been learned from high-quality images. To enhance this process, a Semantic Embedding Module (SEM) is introduced to integrate semantic information with low-level features, and a Codebook Shift (CS) mechanism, designed to adapt the pre-learned codebook to better suit the distinct characteristics of our low-light dataset. Additionally, we present an Interactive Feature Transformation (IFT) module to refine texture and color information during image reconstruction, allowing for interactive enhancement based on user preferences. Extensive experiments on both real-world and synthetic benchmarks demonstrate that the incorporation of prior knowledge and controllable information transfer significantly enhances LLIE performance in terms of quality and fidelity. The proposed CodeEnhance exhibits superior robustness to various degradations, including uneven illumination, noise, and color distortion.
Read more5/1/2024