Text-like Encoding of Collaborative Information in Large Language Models for Recommendation

0
Sign in to get full access
Overview
- This paper explores a novel approach to encoding collaborative information in large language models for recommendation systems.
- The researchers propose a "text-like encoding" method to effectively integrate user-item interaction data into the language model, improving its performance on recommendation tasks.
- The paper presents experimental results demonstrating the effectiveness of this approach compared to previous methods of incorporating collaborative information into large language models.
Plain English Explanation
The researchers in this paper are trying to find a better way to use large language models, like GPT-3, to make personalized recommendations for users. Large language models are powerful AI systems that can understand and generate human-like text, but they don't naturally capture the kind of user-item interaction data that traditional recommendation systems use.
The key idea in this paper is to encode that collaborative information in a "text-like" format that the language model can understand and learn from. Instead of just feeding the model raw user-item data, the researchers convert it into a special kind of text that the model can process. This allows the model to learn about user preferences and item relationships directly from the text, rather than needing a separate collaborative filtering component.
The paper on adapting large language models by integrating collaborative information and the paper on efficiently combining large language models with collaborative filtering are two related works that explore similar approaches to incorporating collaborative data into language models.
The researchers demonstrate that their text-like encoding method outperforms previous approaches on standard recommendation benchmarks. This suggests that it's a promising way to leverage the power of large language models for personalized recommendation systems, without losing the benefits of collaborative filtering.
Technical Explanation
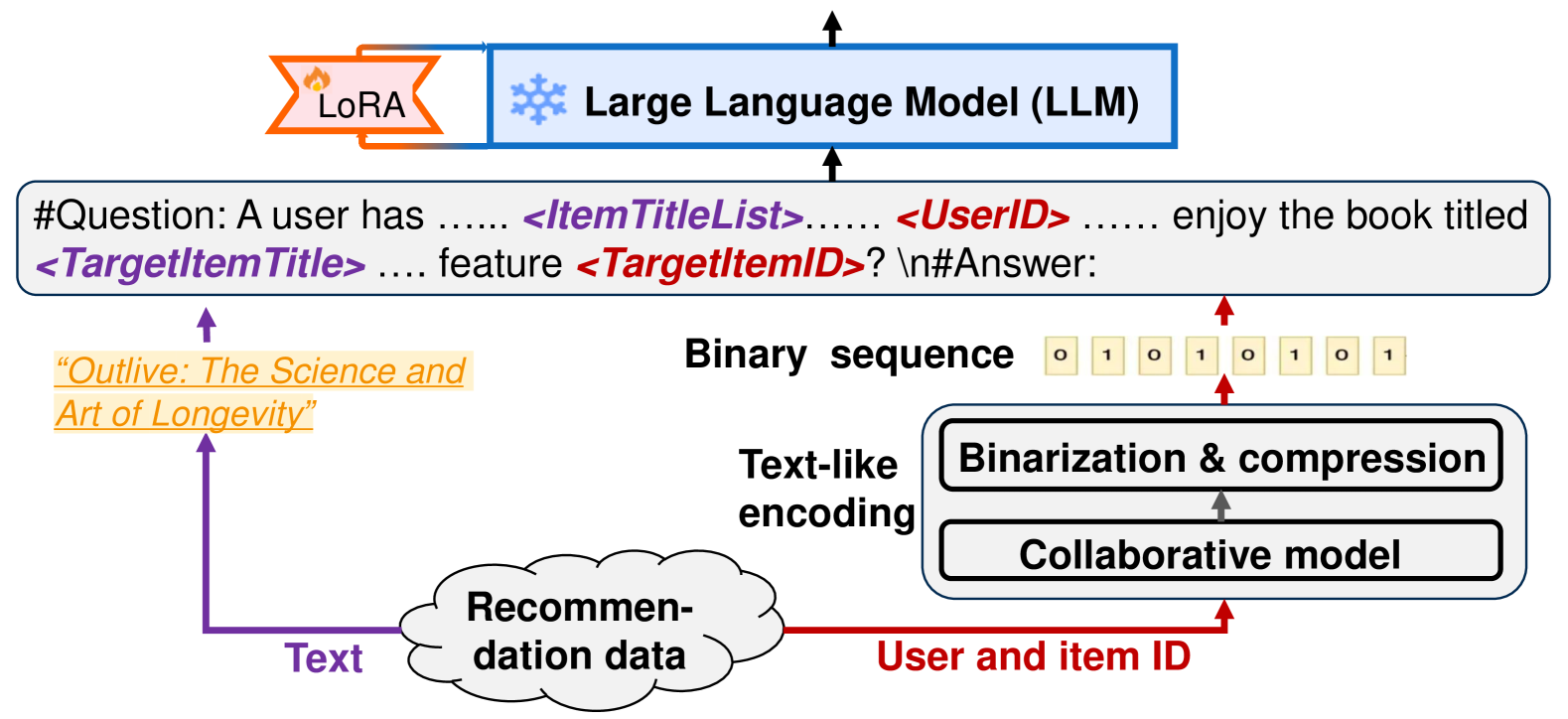
The core of the researchers' approach is a technique they call "text-like encoding" of collaborative information. Instead of directly feeding user-item interaction data into the language model, they convert it into a special textual format that the model can understand and learn from.
Specifically, they create pseudo-sentences that encode information about user preferences and item relationships. For example, a sentence like "User A likes item X" or "Item Y is similar to item Z" can be generated from the underlying user-item interaction data. These sentences are then concatenated into a text corpus that is used to fine-tune the language model.
The paper on knowledge adaptation from large language models and the paper on personalized recommendation via prompting large language models explore related techniques for integrating external knowledge into language models.
In their experiments, the researchers compare this text-like encoding approach to several baselines, including directly feeding the raw user-item data into the language model and using traditional collaborative filtering methods. They find that the text-like encoding consistently outperforms these other approaches on standard recommendation benchmarks, such as rating prediction and item ranking.
The researchers attribute the success of their method to the language model's ability to effectively learn and reason about the encoded collaborative information. By representing user-item interactions in a textual format, the model can leverage its powerful natural language understanding capabilities to capture complex patterns and relationships in the data.
Critical Analysis
The researchers provide a thorough evaluation of their text-like encoding approach, demonstrating its effectiveness across multiple recommendation tasks and datasets. However, the paper does not delve into some potential limitations or areas for further research.
One potential concern is the scalability of the text-like encoding approach, as the size of the pseudo-text corpus may grow rapidly as the number of users and items increases. This could lead to computational and memory challenges when working with large-scale recommendation problems.
Additionally, the paper does not explore how the text-like encoding might perform in scenarios with sparse or noisy user-item interaction data, which are common in real-world recommendation systems. Further research could investigate the robustness of the approach in the face of such challenges.
The paper on multimodal large representation models for recommendation introduces an interesting extension to this work, combining text-like encoding with other data modalities to further improve recommendation performance.
Overall, the researchers present a compelling and well-executed approach to integrating collaborative information into large language models for recommendation. While the paper leaves room for further exploration, it provides valuable insights and a promising direction for enhancing the capabilities of large language models in personalized recommendation systems.
Conclusion
This paper introduces a novel "text-like encoding" method for effectively incorporating collaborative information into large language models for recommendation tasks. The researchers demonstrate that this approach outperforms previous methods of combining language models and collaborative filtering, suggesting it is a promising direction for enhancing the performance of personalized recommendation systems.
The text-like encoding technique allows language models to directly learn from user-item interaction data, leveraging their powerful natural language understanding capabilities. While the paper leaves room for further research on scalability and robustness, it provides valuable insights and a solid foundation for advancing the use of large language models in recommendation applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text-like Encoding of Collaborative Information in Large Language Models for Recommendation
Yang Zhang, Keqin Bao, Ming Yan, Wenjie Wang, Fuli Feng, Xiangnan He
When adapting Large Language Models for Recommendation (LLMRec), it is crucial to integrate collaborative information. Existing methods achieve this by learning collaborative embeddings in LLMs' latent space from scratch or by mapping from external models. However, they fail to represent the information in a text-like format, which may not align optimally with LLMs. To bridge this gap, we introduce BinLLM, a novel LLMRec method that seamlessly integrates collaborative information through text-like encoding. BinLLM converts collaborative embeddings from external models into binary sequences -- a specific text format that LLMs can understand and operate on directly, facilitating the direct usage of collaborative information in text-like format by LLMs. Additionally, BinLLM provides options to compress the binary sequence using dot-decimal notation to avoid excessively long lengths. Extensive experiments validate that BinLLM introduces collaborative information in a manner better aligned with LLMs, resulting in enhanced performance. We release our code at https://github.com/zyang1580/BinLLM.
Read more6/6/2024
💬
0
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Read more4/22/2024

0
Collaborative Cross-modal Fusion with Large Language Model for Recommendation
Zhongzhou Liu, Hao Zhang, Kuicai Dong, Yuan Fang
Despite the success of conventional collaborative filtering (CF) approaches for recommendation systems, they exhibit limitations in leveraging semantic knowledge within the textual attributes of users and items. Recent focus on the application of large language models for recommendation (LLM4Rec) has highlighted their capability for effective semantic knowledge capture. However, these methods often overlook the collaborative signals in user behaviors. Some simply instruct-tune a language model, while others directly inject the embeddings of a CF-based model, lacking a synergistic fusion of different modalities. To address these issues, we propose a framework of Collaborative Cross-modal Fusion with Large Language Models, termed CCF-LLM, for recommendation. In this framework, we translate the user-item interactions into a hybrid prompt to encode both semantic knowledge and collaborative signals, and then employ an attentive cross-modal fusion strategy to effectively fuse latent embeddings of both modalities. Extensive experiments demonstrate that CCF-LLM outperforms existing methods by effectively utilizing semantic and collaborative signals in the LLM4Rec context.
Read more8/19/2024
0
Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, Chanyoung Park
Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
Read more6/4/2024