Text-Region Matching for Multi-Label Image Recognition with Missing Labels

0
Sign in to get full access
Overview
- Multi-label image recognition with missing labels is a challenging task in computer vision and language understanding.
- The paper proposes a new approach called "Text-Region Matching" that aims to improve performance on this task.
- The key innovation is using text-region matching to better leverage available label information and handle missing labels.
Plain English Explanation
In multi-label image recognition, the goal is to identify all the different objects, scenes, and concepts present in an image. This is a useful capability for applications like image search and content understanding. However, it can be difficult because real-world images often have missing labels - the model may not have access to information about all the relevant elements in the image during training.
The Text-Region Matching for Multi-Label Image Recognition with Missing Labels paper introduces a new approach to address this challenge. The core idea is to match text descriptions to specific regions within the image, rather than just predicting labels independently. This allows the model to better leverage the available label information and handle cases where some labels are missing.
Technical Explanation
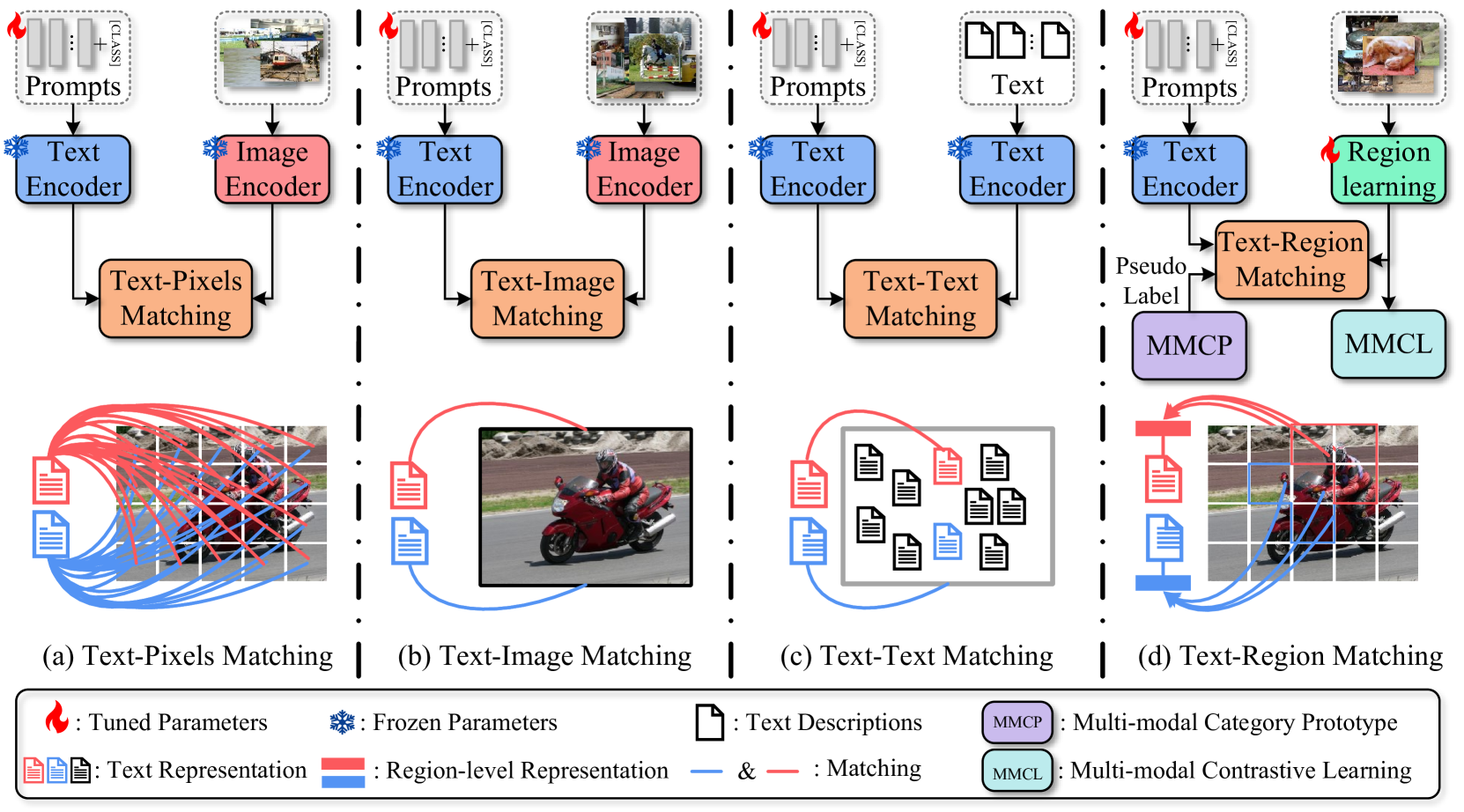
The paper proposes a Text-Region Matching framework for multi-label image recognition. The key components are:
- Visual Encoder: Encodes the input image into visual features.
- Text Encoder: Encodes the text labels into text features.
- Text-Region Matching Module: Computes the similarity between text features and local image regions to identify the most relevant regions for each label.
- Label Prediction Module: Predicts the final multi-label classification based on the text-region matching scores.
This approach allows the model to learn associations between visual regions and text labels, which helps it handle missing labels more effectively compared to standard multi-label classification models.
The authors evaluate their method on benchmark multi-label image recognition datasets and show significant performance improvements over previous state-of-the-art techniques.
Critical Analysis
The paper presents a well-designed and theoretically sound approach to address the challenge of multi-label image recognition with missing labels. The text-region matching innovation is a thoughtful and potentially impactful contribution to the field.
However, the authors acknowledge some limitations of their work, such as the need for further investigation into the optimal text-region matching architecture and the potential for overfitting on specific dataset biases. Additionally, while the experiments demonstrate strong performance, it would be valuable to see the model evaluated on a wider range of real-world datasets and applications to fully assess its generalizability.
Overall, this paper presents a promising new direction for multi-label image recognition and highlights the importance of leveraging both visual and textual information to handle challenging scenarios with incomplete label data.
Conclusion
The Text-Region Matching approach introduced in this paper represents an important step forward in multi-label image recognition, a task with significant practical applications in areas like image search, content understanding, and visual assistants. By explicitly modeling the associations between text labels and visual regions, the model is able to better handle missing label information and achieve state-of-the-art performance.
This work underscores the value of integrating vision and language understanding to tackle complex computer vision challenges. As the field continues to advance, we can expect to see more innovative techniques that leverage the synergies between these two modalities to push the boundaries of what's possible in areas like multi-label image recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text-Region Matching for Multi-Label Image Recognition with Missing Labels
Leilei Ma, Hongxing Xie, Lei Wang, Yanping Fu, Dengdi Sun, Haifeng Zhao
Recently, large-scale visual language pre-trained (VLP) models have demonstrated impressive performance across various downstream tasks. Motivated by these advancements, pioneering efforts have emerged in multi-label image recognition with missing labels, leveraging VLP prompt-tuning technology. However, they usually cannot match text and vision features well, due to complicated semantics gaps and missing labels in a multi-label image. To tackle this challenge, we propose $textbf{T}$ext-$textbf{R}$egion $textbf{M}$atching for optimizing $textbf{M}$ulti-$textbf{L}$abel prompt tuning, namely TRM-ML, a novel method for enhancing meaningful cross-modal matching. Compared to existing methods, we advocate exploring the information of category-aware regions rather than the entire image or pixels, which contributes to bridging the semantic gap between textual and visual representations in a one-to-one matching manner. Concurrently, we further introduce multimodal contrastive learning to narrow the semantic gap between textual and visual modalities and establish intra-class and inter-class relationships. Additionally, to deal with missing labels, we propose a multimodal category prototype that leverages intra- and inter-category semantic relationships to estimate unknown labels, facilitating pseudo-label generation. Extensive experiments on the MS-COCO, PASCAL VOC, Visual Genome, NUS-WIDE, and CUB-200-211 benchmark datasets demonstrate that our proposed framework outperforms the state-of-the-art methods by a significant margin. Our code is available here: https://github.com/yu-gi-oh-leilei/TRM-ML.
Read more8/30/2024
🤿
0
Advanced Multimodal Deep Learning Architecture for Image-Text Matching
Jinyin Wang, Haijing Zhang, Yihao Zhong, Yingbin Liang, Rongwei Ji, Yiru Cang
Image-text matching is a key multimodal task that aims to model the semantic association between images and text as a matching relationship. With the advent of the multimedia information age, image, and text data show explosive growth, and how to accurately realize the efficient and accurate semantic correspondence between them has become the core issue of common concern in academia and industry. In this study, we delve into the limitations of current multimodal deep learning models in processing image-text pairing tasks. Therefore, we innovatively design an advanced multimodal deep learning architecture, which combines the high-level abstract representation ability of deep neural networks for visual information with the advantages of natural language processing models for text semantic understanding. By introducing a novel cross-modal attention mechanism and hierarchical feature fusion strategy, the model achieves deep fusion and two-way interaction between image and text feature space. In addition, we also optimize the training objectives and loss functions to ensure that the model can better map the potential association structure between images and text during the learning process. Experiments show that compared with existing image-text matching models, the optimized new model has significantly improved performance on a series of benchmark data sets. In addition, the new model also shows excellent generalization and robustness on large and diverse open scenario datasets and can maintain high matching performance even in the face of previously unseen complex situations.
Read more6/24/2024

0
Leveraging Text Localization for Scene Text Removal via Text-aware Masked Image Modeling
Zixiao Wang, Hongtao Xie, YuXin Wang, Yadong Qu, Fengjun Guo, Pengwei Liu
Existing scene text removal (STR) task suffers from insufficient training data due to the expensive pixel-level labeling. In this paper, we aim to address this issue by introducing a Text-aware Masked Image Modeling algorithm (TMIM), which can pretrain STR models with low-cost text detection labels (e.g., text bounding box). Different from previous pretraining methods that use indirect auxiliary tasks only to enhance the implicit feature extraction ability, our TMIM first enables the STR task to be directly trained in a weakly supervised manner, which explores the STR knowledge explicitly and efficiently. In TMIM, first, a Background Modeling stream is built to learn background generation rules by recovering the masked non-text region. Meanwhile, it provides pseudo STR labels on the masked text region. Second, a Text Erasing stream is proposed to learn from the pseudo labels and equip the model with end-to-end STR ability. Benefiting from the two collaborative streams, our STR model can achieve impressive performance only with the public text detection datasets, which greatly alleviates the limitation of the high-cost STR labels. Experiments demonstrate that our method outperforms other pretrain methods and achieves state-of-the-art performance (37.35 PSNR on SCUT-EnsText). Code will be available at https://github.com/wzx99/TMIM.
Read more9/23/2024

0
Text-centric Alignment for Multi-Modality Learning
Yun-Da Tsai, Ting-Yu Yen, Pei-Fu Guo, Zhe-Yan Li, Shou-De Lin
This research paper addresses the challenge of modality mismatch in multimodal learning, where the modalities available during inference differ from those available at training. We propose the Text-centric Alignment for Multi-Modality Learning (TAMML) approach, an innovative method that utilizes Large Language Models (LLMs) with in-context learning and foundation models to enhance the generalizability of multimodal systems under these conditions. By leveraging the unique properties of text as a unified semantic space, TAMML demonstrates significant improvements in handling unseen, diverse, and unpredictable modality combinations. TAMML not only adapts to varying modalities but also maintains robust performance, showcasing the potential of foundation models in overcoming the limitations of traditional fixed-modality frameworks in embedding representations. This study contributes to the field by offering a flexible, effective solution for real-world applications where modality availability is dynamic and uncertain.
Read more5/22/2024