Leveraging Text Localization for Scene Text Removal via Text-aware Masked Image Modeling

0

Sign in to get full access
Overview
- Leveraging text localization for scene text removal via text-aware masked image modeling
- Proposes a novel pretraining approach for image models to remove scene text
- Uses text localization information to guide the masked image modeling process
Plain English Explanation
The paper presents a new method to help image models better remove text that appears in real-world scenes, such as text on signs, billboards, or product packaging. The key idea is to leverage information about where text is located in an image during the training process.
The researchers train the image model using a masked image modeling approach, where the model must learn to predict the original pixel values in image regions that have been randomly covered up or "masked" during training. By incorporating information about the location of text in the image, the model can focus its efforts on accurately predicting the underlying scene behind the text, rather than just trying to hallucinate the missing text.
This text-aware masked image modeling approach allows the trained model to more effectively remove scene text during inference, producing cleaner images with the text content removed. The internal text localization information acts as a guide to help the model understand which regions to focus on for text removal.
Technical Explanation
The paper proposes a text-aware masked image modeling pretraining approach to enhance the performance of scene text removal models. The key elements are:
-
Masked Image Modeling: The model is trained to predict the original pixel values in randomly masked regions of the image, forcing it to learn a robust representation of the underlying scene.
-
Text Localization Guidance: During pretraining, the model also has access to text localization information, which indicates the regions of the image containing text. This text-aware guidance helps the model focus its efforts on accurately reconstructing the underlying scene behind the text.
-
Symmetric Masking Strategy: The researchers use a symmetric masking strategy, where the same mask is applied to both the input image and the corresponding text localization map. This ensures the model learns a consistent representation of the text and scene content.
The text-aware masked image modeling pretraining approach is evaluated on scene text removal tasks, demonstrating improved performance compared to baseline models that do not leverage the text localization information.
Critical Analysis
The paper presents a compelling approach to leveraging text localization for more effective scene text removal. However, a few potential limitations and areas for further research are worth considering:
-
Dependency on Text Localization: The approach relies on having accurate text localization information during pretraining. In real-world scenarios, this text localization may not always be available or reliable, which could impact the model's performance.
-
Generalization to Diverse Scenes: The paper evaluates the method on standard scene text removal benchmarks, but it's unclear how well it would generalize to more diverse, real-world scenes with complex text layouts and backgrounds.
-
Computational Overhead: The additional text localization guidance and symmetric masking strategy may increase the computational requirements during pretraining, which could be a practical concern for some applications.
Further research could explore methods to mitigate these limitations, such as developing more robust text localization models or investigating alternative pretraining strategies that don't rely on explicit text region annotations.
Conclusion
The proposed text-aware masked image modeling approach represents a promising step forward in enhancing scene text removal capabilities. By leveraging text localization information during pretraining, the model can learn to more effectively remove text from real-world images, producing cleaner and more visually appealing results. This research has interesting implications for a variety of applications, such as image editing, content moderation, and visual data cleaning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Text Localization for Scene Text Removal via Text-aware Masked Image Modeling
Zixiao Wang, Hongtao Xie, YuXin Wang, Yadong Qu, Fengjun Guo, Pengwei Liu
Existing scene text removal (STR) task suffers from insufficient training data due to the expensive pixel-level labeling. In this paper, we aim to address this issue by introducing a Text-aware Masked Image Modeling algorithm (TMIM), which can pretrain STR models with low-cost text detection labels (e.g., text bounding box). Different from previous pretraining methods that use indirect auxiliary tasks only to enhance the implicit feature extraction ability, our TMIM first enables the STR task to be directly trained in a weakly supervised manner, which explores the STR knowledge explicitly and efficiently. In TMIM, first, a Background Modeling stream is built to learn background generation rules by recovering the masked non-text region. Meanwhile, it provides pseudo STR labels on the masked text region. Second, a Text Erasing stream is proposed to learn from the pseudo labels and equip the model with end-to-end STR ability. Benefiting from the two collaborative streams, our STR model can achieve impressive performance only with the public text detection datasets, which greatly alleviates the limitation of the high-cost STR labels. Experiments demonstrate that our method outperforms other pretrain methods and achieves state-of-the-art performance (37.35 PSNR on SCUT-EnsText). Code will be available at https://github.com/wzx99/TMIM.
Read more9/23/2024

0
Symmetric masking strategy enhances the performance of Masked Image Modeling
Khanh-Binh Nguyen, Chae Jung Park
Masked Image Modeling (MIM) is a technique in self-supervised learning that focuses on acquiring detailed visual representations from unlabeled images by estimating the missing pixels in randomly masked sections. It has proven to be a powerful tool for the preliminary training of Vision Transformers (ViTs), yielding impressive results across various tasks. Nevertheless, most MIM methods heavily depend on the random masking strategy to formulate the pretext task. This strategy necessitates numerous trials to ascertain the optimal dropping ratio, which can be resource-intensive, requiring the model to be pre-trained for anywhere between 800 to 1600 epochs. Furthermore, this approach may not be suitable for all datasets. In this work, we propose a new masking strategy that effectively helps the model capture global and local features. Based on this masking strategy, SymMIM, our proposed training pipeline for MIM is introduced. SymMIM achieves a new SOTA accuracy of 85.9% on ImageNet using ViT-Large and surpasses previous SOTA across downstream tasks such as image classification, semantic segmentation, object detection, instance segmentation tasks, and so on.
Read more8/26/2024

0
Self-Supervised Pre-training with Symmetric Superimposition Modeling for Scene Text Recognition
Zuan Gao, Yuxin Wang, Yadong Qu, Boqiang Zhang, Zixiao Wang, Jianjun Xu, Hongtao Xie
In text recognition, self-supervised pre-training emerges as a good solution to reduce dependence on expansive annotated real data. Previous studies primarily focus on local visual representation by leveraging mask image modeling or sequence contrastive learning. However, they omit modeling the linguistic information in text images, which is crucial for recognizing text. To simultaneously capture local character features and linguistic information in visual space, we propose Symmetric Superimposition Modeling (SSM). The objective of SSM is to reconstruct the direction-specific pixel and feature signals from the symmetrically superimposed input. Specifically, we add the original image with its inverted views to create the symmetrically superimposed inputs. At the pixel level, we reconstruct the original and inverted images to capture character shapes and texture-level linguistic context. At the feature level, we reconstruct the feature of the same original image and inverted image with different augmentations to model the semantic-level linguistic context and the local character discrimination. In our design, we disrupt the character shape and linguistic rules. Consequently, the dual-level reconstruction facilitates understanding character shapes and linguistic information from the perspective of visual texture and feature semantics. Experiments on various text recognition benchmarks demonstrate the effectiveness and generality of SSM, with 4.1% average performance gains and 86.6% new state-of-the-art average word accuracy on Union14M benchmarks. The code is available at https://github.com/FaltingsA/SSM.
Read more5/14/2024
0
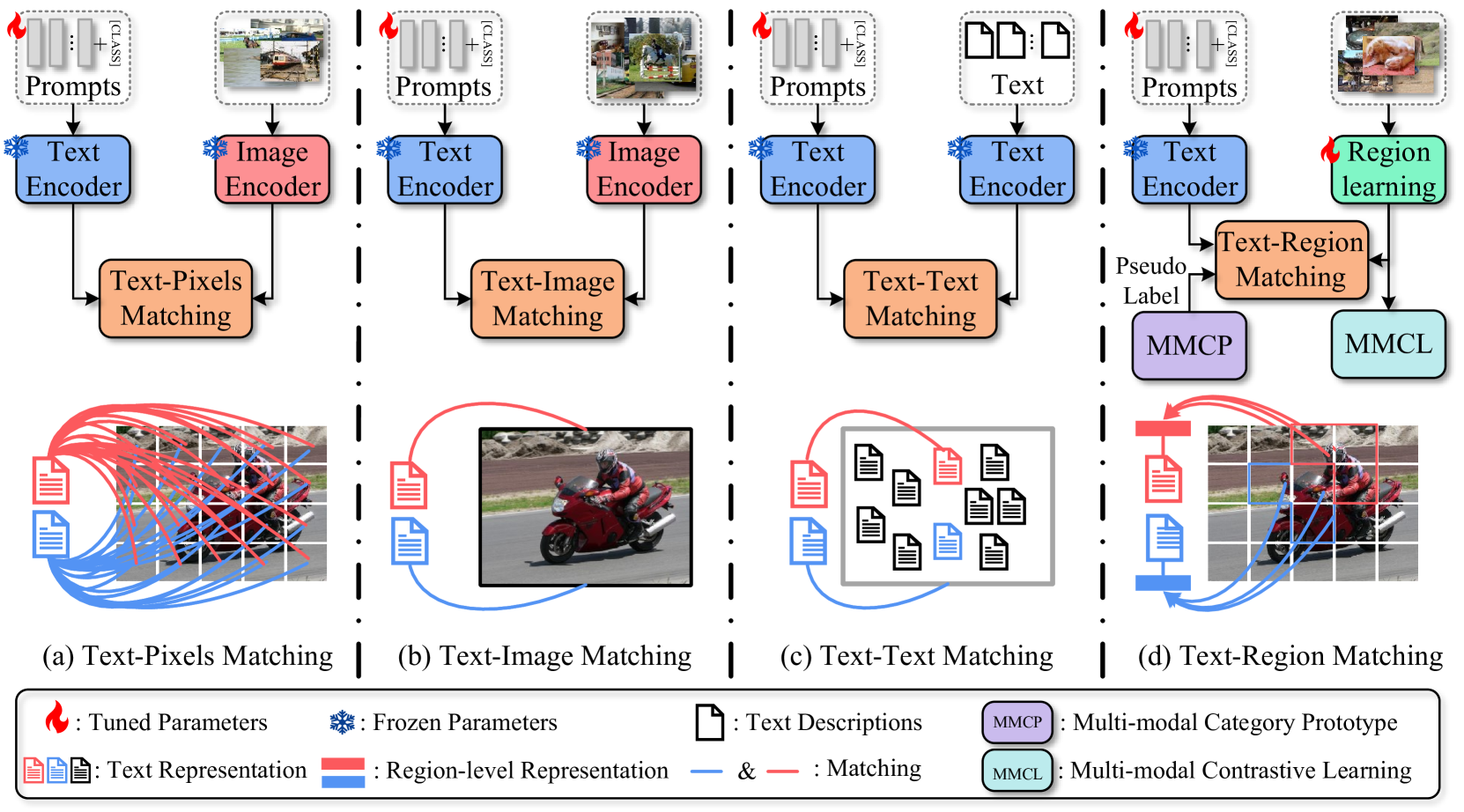
Text-Region Matching for Multi-Label Image Recognition with Missing Labels
Leilei Ma, Hongxing Xie, Lei Wang, Yanping Fu, Dengdi Sun, Haifeng Zhao
Recently, large-scale visual language pre-trained (VLP) models have demonstrated impressive performance across various downstream tasks. Motivated by these advancements, pioneering efforts have emerged in multi-label image recognition with missing labels, leveraging VLP prompt-tuning technology. However, they usually cannot match text and vision features well, due to complicated semantics gaps and missing labels in a multi-label image. To tackle this challenge, we propose $textbf{T}$ext-$textbf{R}$egion $textbf{M}$atching for optimizing $textbf{M}$ulti-$textbf{L}$abel prompt tuning, namely TRM-ML, a novel method for enhancing meaningful cross-modal matching. Compared to existing methods, we advocate exploring the information of category-aware regions rather than the entire image or pixels, which contributes to bridging the semantic gap between textual and visual representations in a one-to-one matching manner. Concurrently, we further introduce multimodal contrastive learning to narrow the semantic gap between textual and visual modalities and establish intra-class and inter-class relationships. Additionally, to deal with missing labels, we propose a multimodal category prototype that leverages intra- and inter-category semantic relationships to estimate unknown labels, facilitating pseudo-label generation. Extensive experiments on the MS-COCO, PASCAL VOC, Visual Genome, NUS-WIDE, and CUB-200-211 benchmark datasets demonstrate that our proposed framework outperforms the state-of-the-art methods by a significant margin. Our code is available here: https://github.com/yu-gi-oh-leilei/TRM-ML.
Read more8/30/2024