Textual Inversion and Self-supervised Refinement for Radiology Report Generation

0

Sign in to get full access
Overview
- This paper explores textual inversion and self-supervised refinement techniques for improving radiology report generation.
- The proposed approach aims to enhance the quality and accuracy of automatically generated radiology reports by leveraging cross-modal learning and self-supervised refinement.
- The research builds upon recent advancements in information-theoretic text-to-image alignment, topical separable sentence retrieval for medical report generation, and self-refining radiology report generation.
Plain English Explanation
Radiology reports are essential for communicating findings from medical imaging tests like X-rays, CT scans, and MRIs. Traditionally, these reports are written by radiologists, but there is growing interest in automating the report generation process using artificial intelligence (AI) systems.
This paper presents a new approach that aims to improve the quality and accuracy of automatically generated radiology reports. The key ideas are:
-
Textual Inversion: The system learns to associate specific medical terms and concepts with the corresponding visual features in the medical images. This allows the system to "invert" the relationship and generate relevant text descriptions when presented with a new image.
-
Self-supervised Refinement: After the initial report generation, the system further refines the output by learning from its own mistakes. It analyzes the generated report and the original image, and then makes targeted improvements to the text to better match the visual information.
By combining these two techniques - textual inversion and self-supervised refinement - the researchers show that the quality of the automatically generated radiology reports can be significantly improved compared to previous methods. This could ultimately help radiologists save time and improve the efficiency of medical reporting workflows.
Technical Explanation
The proposed approach builds on recent advancements in cross-modal learning and self-supervised refinement for radiology report generation.
The textual inversion component learns to associate specific medical terms and concepts with their corresponding visual features in the medical images. This is achieved through a cross-modal alignment process that maps the textual and visual representations into a shared latent space. This allows the system to "invert" the relationship and generate relevant text descriptions when presented with a new image.
The self-supervised refinement module then analyzes the initially generated report and the original image, and makes targeted improvements to the text to better match the visual information. This is done through a iterative process of analysis, error identification, and report refinement. The system learns from its own mistakes to gradually improve the quality of the generated reports.
The combined approach of textual inversion and self-supervised refinement is evaluated on several radiology report generation benchmarks. The results demonstrate significant improvements in both the fluency and accuracy of the generated reports compared to previous state-of-the-art methods, such as those based on topical separable sentence retrieval and symmetric superimposition modeling.
Critical Analysis
The paper makes a compelling case for the effectiveness of the proposed textual inversion and self-supervised refinement techniques in improving radiology report generation. However, the authors acknowledge several limitations and areas for further research:
-
Dataset Bias: The performance of the system may be influenced by biases present in the training datasets, which could lead to suboptimal or even biased report generation for certain medical conditions or demographic groups. Further investigation into dataset bias and debiasing techniques would be valuable.
-
Generalization to Diverse Modalities: The current evaluation focuses on a limited set of medical imaging modalities, such as X-rays and CT scans. It would be important to assess the system's performance and adaptability across a wider range of imaging modalities, including more complex ones like MRI and ultrasound.
-
Clinician Involvement: While the paper demonstrates improvements in automated report generation, the ultimate goal should be to support and enhance the work of human radiologists, not replace them entirely. Closer collaboration with clinicians and incorporating their feedback into the system design could lead to more practical and user-friendly solutions.
-
Ethical Considerations: As with any AI system deployed in the medical domain, there are important ethical considerations around issues like privacy, accountability, and potential biases. The authors should address these concerns more thoroughly in future work.
Conclusion
This paper presents an innovative approach to radiology report generation that combines textual inversion and self-supervised refinement techniques. The results demonstrate significant improvements in the quality and accuracy of the automatically generated reports, which could potentially increase the efficiency and consistency of medical reporting workflows.
However, the authors acknowledge several limitations and areas for further research, such as dataset bias, generalization to diverse modalities, clinician involvement, and ethical considerations. Addressing these challenges will be crucial for the successful deployment and adoption of such AI-powered radiology report generation systems in real-world clinical settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Textual Inversion and Self-supervised Refinement for Radiology Report Generation
Yuanjiang Luo, Hongxiang Li, Xuan Wu, Meng Cao, Xiaoshuang Huang, Zhihong Zhu, Peixi Liao, Hu Chen, Yi Zhang
Existing mainstream approaches follow the encoder-decoder paradigm for generating radiology reports. They focus on improving the network structure of encoders and decoders, which leads to two shortcomings: overlooking the modality gap and ignoring report content constraints. In this paper, we proposed Textual Inversion and Self-supervised Refinement (TISR) to address the above two issues. Specifically, textual inversion can project text and image into the same space by representing images as pseudo words to eliminate the cross-modeling gap. Subsequently, self-supervised refinement refines these pseudo words through contrastive loss computation between images and texts, enhancing the fidelity of generated reports to images. Notably, TISR is orthogonal to most existing methods, plug-and-play. We conduct experiments on two widely-used public datasets and achieve significant improvements on various baselines, which demonstrates the effectiveness and generalization of TISR. The code will be available soon.
Read more6/7/2024
🖼️
0
Medical diffusion on a budget: Textual Inversion for medical image generation
Bram de Wilde, Anindo Saha, Maarten de Rooij, Henkjan Huisman, Geert Litjens
Diffusion models for text-to-image generation, known for their efficiency, accessibility, and quality, have gained popularity. While inference with these systems on consumer-grade GPUs is increasingly feasible, training from scratch requires large captioned datasets and significant computational resources. In medical image generation, the limited availability of large, publicly accessible datasets with text reports poses challenges due to legal and ethical concerns. This work shows that adapting pre-trained Stable Diffusion models to medical imaging modalities is achievable by training text embeddings using Textual Inversion. In this study, we experimented with small medical datasets (100 samples each from three modalities) and trained within hours to generate diagnostically accurate images, as judged by an expert radiologist. Experiments with Textual Inversion training and inference parameters reveal the necessity of larger embeddings and more examples in the medical domain. Classification experiments show an increase in diagnostic accuracy (AUC) for detecting prostate cancer on MRI, from 0.78 to 0.80. Further experiments demonstrate embedding flexibility through disease interpolation, combining pathologies, and inpainting for precise disease appearance control. The trained embeddings are compact (less than 1 MB), enabling easy data sharing with reduced privacy concerns.
Read more9/12/2024
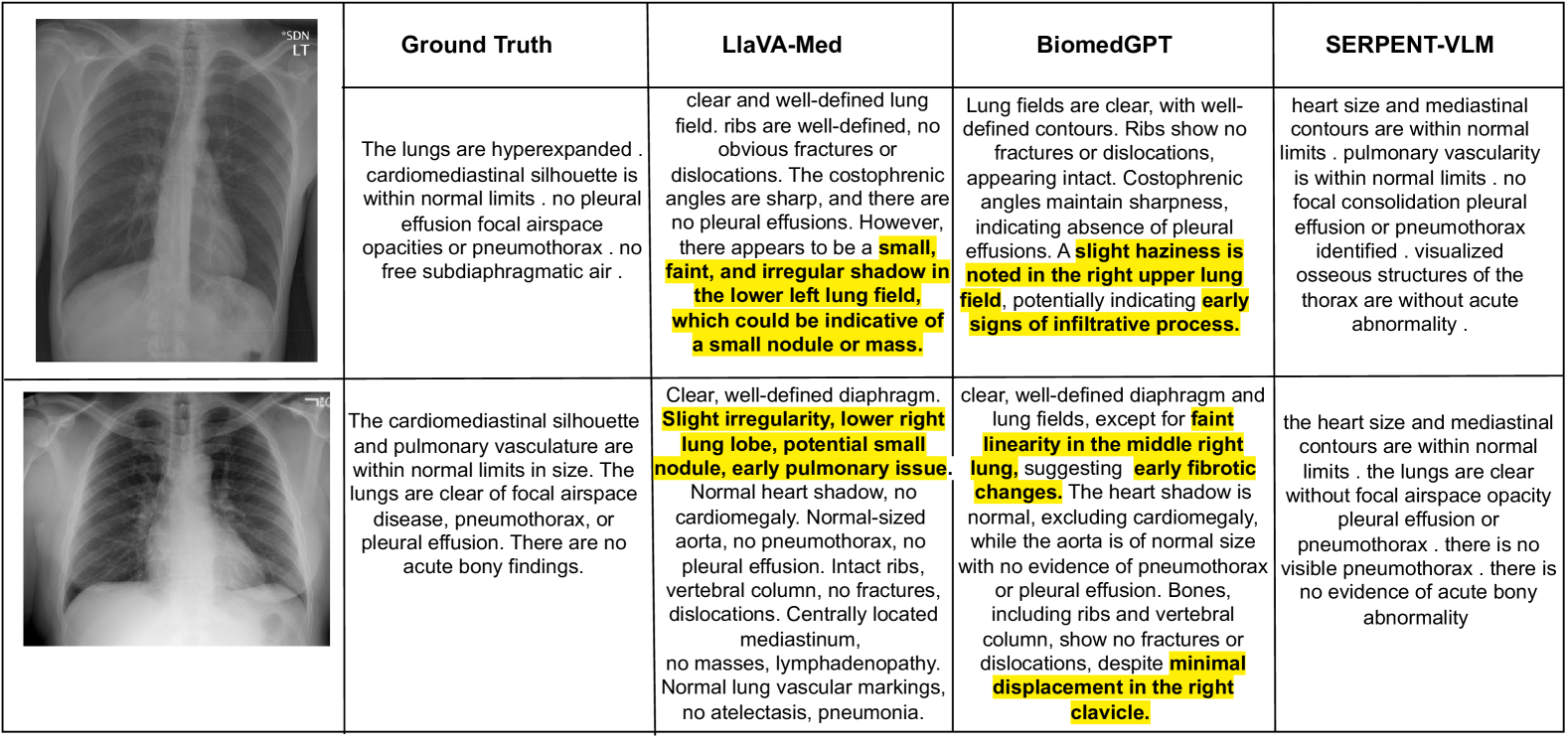
0
SERPENT-VLM : Self-Refining Radiology Report Generation Using Vision Language Models
Manav Nitin Kapadnis, Sohan Patnaik, Abhilash Nandy, Sourjyadip Ray, Pawan Goyal, Debdoot Sheet
Radiology Report Generation (R2Gen) demonstrates how Multi-modal Large Language Models (MLLMs) can automate the creation of accurate and coherent radiological reports. Existing methods often hallucinate details in text-based reports that don't accurately reflect the image content. To mitigate this, we introduce a novel strategy, SERPENT-VLM (SElf Refining Radiology RePort GENeraTion using Vision Language Models), which improves the R2Gen task by integrating a self-refining mechanism into the MLLM framework. We employ a unique self-supervised loss that leverages similarity between pooled image representations and the contextual representations of the generated radiological text, alongside the standard Causal Language Modeling objective, to refine image-text representations. This allows the model to scrutinize and align the generated text through dynamic interaction between a given image and the generated text, therefore reducing hallucination and continuously enhancing nuanced report generation. SERPENT-VLM outperforms existing baselines such as LLaVA-Med, BiomedGPT, etc., achieving SoTA performance on the IU X-ray and Radiology Objects in COntext (ROCO) datasets, and also proves to be robust against noisy images. A qualitative case study emphasizes the significant advancements towards more sophisticated MLLM frameworks for R2Gen, opening paths for further research into self-supervised refinement in the medical imaging domain.
Read more7/19/2024

0
Information Theoretic Text-to-Image Alignment
Chao Wang, Giulio Franzese, Alessandro Finamore, Massimo Gallo, Pietro Michiardi
Diffusion models for Text-to-Image (T2I) conditional generation have seen tremendous success recently. Despite their success, accurately capturing user intentions with these models still requires a laborious trial and error process. This challenge is commonly identified as a model alignment problem, an issue that has attracted considerable attention by the research community. Instead of relying on fine-grained linguistic analyses of prompts, human annotation, or auxiliary vision-language models to steer image generation, in this work we present a novel method that relies on an information-theoretic alignment measure. In a nutshell, our method uses self-supervised fine-tuning and relies on point-wise mutual information between prompts and images to define a synthetic training set to induce model alignment. Our comparative analysis shows that our method is on-par or superior to the state-of-the-art, yet requires nothing but a pre-trained denoising network to estimate MI and a lightweight fine-tuning strategy.
Read more6/3/2024