SERPENT-VLM : Self-Refining Radiology Report Generation Using Vision Language Models

0
Sign in to get full access
Overview
- This paper introduces SERPENT-VLM, a self-refining radiology report generation system that uses vision-language models.
- The system aims to generate high-quality radiology reports by iteratively refining the output based on feedback from radiologists.
- The authors propose a novel approach to incorporate radiologist feedback and update the model during inference to improve report quality.
Plain English Explanation
The paper describes a new system called SERPENT-VLM that can generate detailed radiology reports from medical images. Radiology reports are important documents that summarize the key findings from medical scans like X-rays or MRIs. Generating these reports accurately and efficiently is a challenging task, as radiologists need to carefully examine the images and communicate their observations in a clear, concise way.
SERPENT-VLM tackles this challenge by using a vision-language model - a type of AI system that can understand both visual and textual information. The key innovation is that the system can refine and improve its reports based on feedback from radiologists. As radiologists review the initial report, they can provide comments or edits. SERPENT-VLM then uses this feedback to update and fine-tune the model, making it better able to generate high-quality reports in the future.
This self-refining capability is crucial, as it allows the system to learn from human experts and continuously improve its performance. Compared to previous approaches that generated reports from scratch, SERPENT-VLM can leverage the knowledge and feedback of radiologists to produce reports that are more accurate, comprehensive, and tailored to the needs of medical professionals.
Technical Explanation
The core of SERPENT-VLM is a vision-language model, which is trained to generate textual radiology reports given medical images as input. This builds on recent advances in vision-language models for medical report generation.
The key innovation of SERPENT-VLM is its ability to iteratively refine the generated reports based on feedback from radiologists. During inference, the system first generates an initial report. Radiologists can then review this report and provide feedback, such as corrections, edits, or additional details they would like to see. SERPENT-VLM then uses this feedback to update the model's parameters and generate an improved report. This process can be repeated multiple times until the radiologist is satisfied with the final report.
The authors propose a novel training procedure to enable this self-refining capability. During pre-training, the model is exposed to a large corpus of radiology reports and their corresponding medical images. Then, during fine-tuning, the model is trained to not only generate reports from images, but also to update its outputs based on simulated radiologist feedback. This allows the model to learn how to effectively incorporate human feedback and improve its performance.
The authors evaluate SERPENT-VLM on several benchmark datasets for radiology report generation and demonstrate that it outperforms previous state-of-the-art models, both in terms of initial report quality and the ability to refine reports based on feedback.
Critical Analysis
The SERPENT-VLM approach represents an important step forward in radiology report generation, as it addresses a key limitation of prior systems that generated reports from scratch without the ability to learn from human feedback. By incorporating radiologist input, the system can produce more accurate and clinically relevant reports.
However, the paper does not fully address the potential limitations and challenges of this approach. For example, the authors do not discuss how the system would scale to handle feedback from multiple radiologists with potentially conflicting opinions. Additionally, the paper does not explore the potential biases that could be introduced by relying on human feedback, which may not be representative of the broader population.
Furthermore, the authors do not provide a detailed analysis of the types of errors or shortcomings in the initial reports that the self-refining process is able to address. A deeper understanding of these issues could help guide future improvements to the system.
Overall, SERPENT-VLM represents an exciting and promising approach, but there are still several areas for further research and development to ensure the system is robust, scalable, and fair in a real-world clinical setting.
Conclusion
The SERPENT-VLM system introduces a novel approach to radiology report generation that leverages vision-language models and iterative refinement based on radiologist feedback. By enabling the model to learn from human experts, the system can produce more accurate and clinically relevant reports, which could have significant implications for improving the efficiency and quality of medical imaging workflows.
While the paper demonstrates promising results, there are still several areas for further research and development to address potential limitations and ensure the system is robust and scalable. Nonetheless, the self-refining capabilities of SERPENT-VLM represent an important step forward in the field of medical report generation and could inspire similar innovations in other domains where expert feedback is critical.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SERPENT-VLM : Self-Refining Radiology Report Generation Using Vision Language Models
Manav Nitin Kapadnis, Sohan Patnaik, Abhilash Nandy, Sourjyadip Ray, Pawan Goyal, Debdoot Sheet
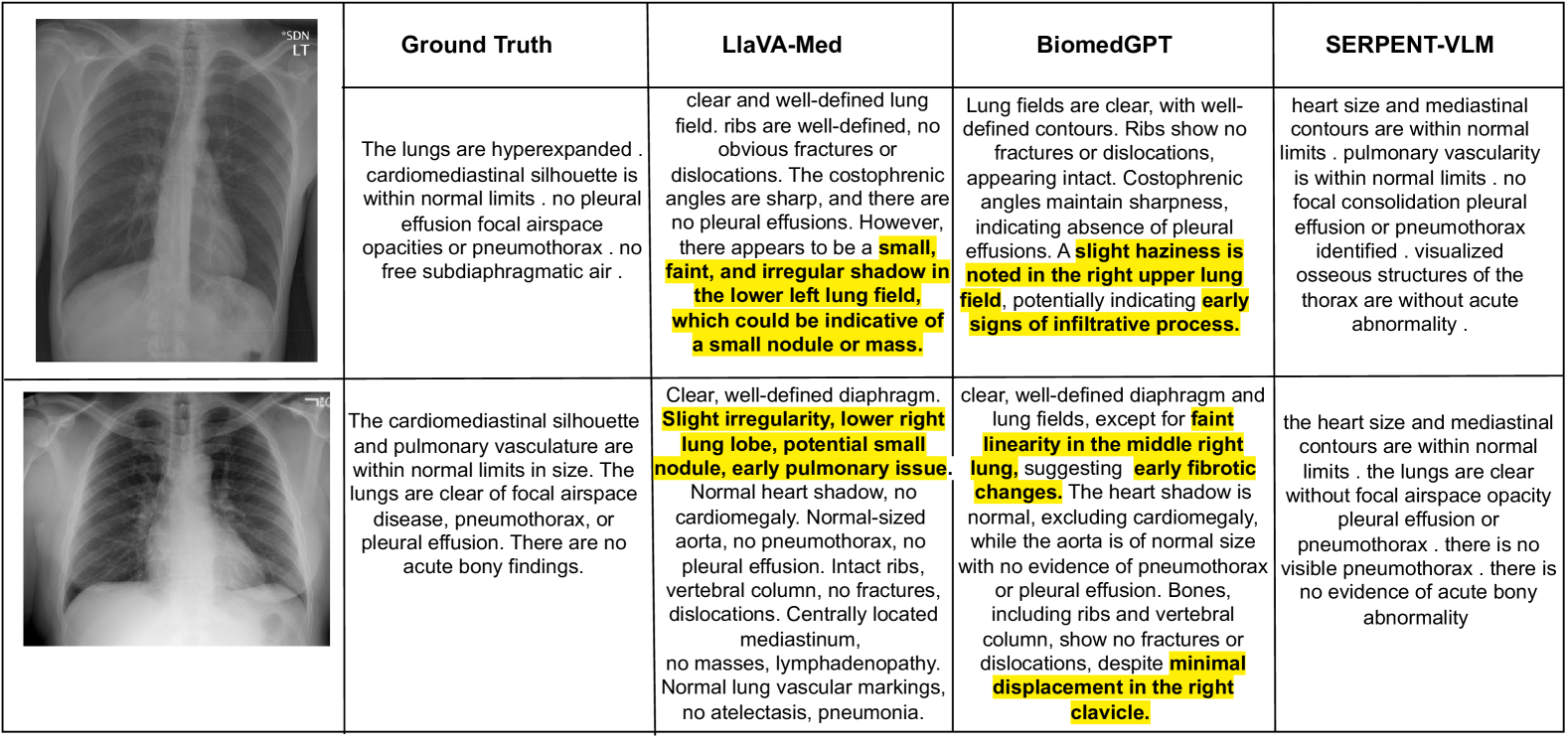
Radiology Report Generation (R2Gen) demonstrates how Multi-modal Large Language Models (MLLMs) can automate the creation of accurate and coherent radiological reports. Existing methods often hallucinate details in text-based reports that don't accurately reflect the image content. To mitigate this, we introduce a novel strategy, SERPENT-VLM (SElf Refining Radiology RePort GENeraTion using Vision Language Models), which improves the R2Gen task by integrating a self-refining mechanism into the MLLM framework. We employ a unique self-supervised loss that leverages similarity between pooled image representations and the contextual representations of the generated radiological text, alongside the standard Causal Language Modeling objective, to refine image-text representations. This allows the model to scrutinize and align the generated text through dynamic interaction between a given image and the generated text, therefore reducing hallucination and continuously enhancing nuanced report generation. SERPENT-VLM outperforms existing baselines such as LLaVA-Med, BiomedGPT, etc., achieving SoTA performance on the IU X-ray and Radiology Objects in COntext (ROCO) datasets, and also proves to be robust against noisy images. A qualitative case study emphasizes the significant advancements towards more sophisticated MLLM frameworks for R2Gen, opening paths for further research into self-supervised refinement in the medical imaging domain.
Read more7/19/2024

0
KARGEN: Knowledge-enhanced Automated Radiology Report Generation Using Large Language Models
Yingshu Li, Zhanyu Wang, Yunyi Liu, Lei Wang, Lingqiao Liu, Luping Zhou
Harnessing the robust capabilities of Large Language Models (LLMs) for narrative generation, logical reasoning, and common-sense knowledge integration, this study delves into utilizing LLMs to enhance automated radiology report generation (R2Gen). Despite the wealth of knowledge within LLMs, efficiently triggering relevant knowledge within these large models for specific tasks like R2Gen poses a critical research challenge. This paper presents KARGEN, a Knowledge-enhanced Automated radiology Report GENeration framework based on LLMs. Utilizing a frozen LLM to generate reports, the framework integrates a knowledge graph to unlock chest disease-related knowledge within the LLM to enhance the clinical utility of generated reports. This is achieved by leveraging the knowledge graph to distill disease-related features in a designed way. Since a radiology report encompasses both normal and disease-related findings, the extracted graph-enhanced disease-related features are integrated with regional image features, attending to both aspects. We explore two fusion methods to automatically prioritize and select the most relevant features. The fused features are employed by LLM to generate reports that are more sensitive to diseases and of improved quality. Our approach demonstrates promising results on the MIMIC-CXR and IU-Xray datasets.
Read more9/10/2024

0
TRRG: Towards Truthful Radiology Report Generation With Cross-modal Disease Clue Enhanced Large Language Model
Yuhao Wang, Chao Hao, Yawen Cui, Xinqi Su, Weicheng Xie, Tao Tan, Zitong Yu
The vision-language modeling capability of multi-modal large language models has attracted wide attention from the community. However, in medical domain, radiology report generation using vision-language models still faces significant challenges due to the imbalanced data distribution caused by numerous negated descriptions in radiology reports and issues such as rough alignment between radiology reports and radiography. In this paper, we propose a truthful radiology report generation framework, namely TRRG, based on stage-wise training for cross-modal disease clue injection into large language models. In pre-training stage, During the pre-training phase, contrastive learning is employed to enhance the ability of visual encoder to perceive fine-grained disease details. In fine-tuning stage, the clue injection module we proposed significantly enhances the disease-oriented perception capability of the large language model by effectively incorporating the robust zero-shot disease perception. Finally, through the cross-modal clue interaction module, our model effectively achieves the multi-granular interaction of visual embeddings and an arbitrary number of disease clue embeddings. This significantly enhances the report generation capability and clinical effectiveness of multi-modal large language models in the field of radiology reportgeneration. Experimental results demonstrate that our proposed pre-training and fine-tuning framework achieves state-of-the-art performance in radiology report generation on datasets such as IU-Xray and MIMIC-CXR. Further analysis indicates that our proposed method can effectively enhance the model to perceive diseases and improve its clinical effectiveness.
Read more8/23/2024

0
MRScore: Evaluating Radiology Report Generation with LLM-based Reward System
Yunyi Liu, Zhanyu Wang, Yingshu Li, Xinyu Liang, Lingqiao Liu, Lei Wang, Luping Zhou
In recent years, automated radiology report generation has experienced significant growth. This paper introduces MRScore, an automatic evaluation metric tailored for radiology report generation by leveraging Large Language Models (LLMs). Conventional NLG (natural language generation) metrics like BLEU are inadequate for accurately assessing the generated radiology reports, as systematically demonstrated by our observations within this paper. To address this challenge, we collaborated with radiologists to develop a framework that guides LLMs for radiology report evaluation, ensuring alignment with human analysis. Our framework includes two key components: i) utilizing GPT to generate large amounts of training data, i.e., reports with different qualities, and ii) pairing GPT-generated reports as accepted and rejected samples and training LLMs to produce MRScore as the model reward. Our experiments demonstrate MRScore's higher correlation with human judgments and superior performance in model selection compared to traditional metrics. Our code and datasets will be available on GitHub.
Read more4/30/2024