A Theoretical Framework for Partially Observed Reward-States in RLHF
2402.03282
0
0
🧠
Abstract
The growing deployment of reinforcement learning from human feedback (RLHF) calls for a deeper theoretical investigation of its underlying models. The prevalent models of RLHF do not account for neuroscience-backed, partially-observed internal states that can affect human feedback, nor do they accommodate intermediate feedback during an interaction. Both of these can be instrumental in speeding up learning and improving alignment. To address these limitations, we model RLHF as reinforcement learning with partially observed reward-states (PORRL). We accommodate two kinds of feedback $-$ cardinal and dueling feedback. We first demonstrate that PORRL subsumes a wide class of RL problems, including traditional RL, RLHF, and reward machines. For cardinal feedback, we present two model-based methods (POR-UCRL, POR-UCBVI). We give both cardinal regret and sample complexity guarantees for the methods, showing that they improve over naive history-summarization. We then discuss the benefits of a model-free method like GOLF with naive history-summarization in settings with recursive internal states and dense intermediate feedback. For this purpose, we define a new history aware version of the Bellman-eluder dimension and give a new guarantee for GOLF in our setting, which can be exponentially sharper in illustrative examples. For dueling feedback, we show that a naive reduction to cardinal feedback fails to achieve sublinear dueling regret. We then present the first explicit reduction that converts guarantees for cardinal regret to dueling regret. In both feedback settings, we show that our models and guarantees generalize and extend existing ones.
Create account to get full access
Overview
- The paper explores the theoretical foundations of reinforcement learning from human feedback (RLHF), a growing approach in AI development.
- It introduces a new model called "reinforcement learning with partially observed reward-states (PORRL)" to address limitations in existing RLHF models.
- The PORRL model accommodates two types of human feedback: cardinal and dueling feedback.
- The paper presents various methods and theoretical guarantees for PORRL in both feedback settings, showing advantages over naive approaches.
Plain English Explanation
Reinforcement learning from human feedback (RLHF) is a technique used to train AI systems where the system learns by receiving feedback from humans during the training process. This paper provides a deeper theoretical investigation of RLHF.
The authors argue that existing RLHF models don't fully account for the way human feedback can be influenced by the AI system's internal, partially-observed states. They also note that these models don't handle intermediate feedback provided during an interaction, which could be helpful for speeding up learning and improving alignment between the AI and human preferences.
To address these limitations, the researchers introduce a new model called "reinforcement learning with partially observed reward-states (PORRL)." This PORRL model can handle two types of human feedback: cardinal feedback (e.g., numerical ratings) and dueling feedback (where the human compares two options).
For cardinal feedback, the paper presents two model-based methods (POR-UCRL and POR-UCBVI) and shows they can outperform naive history-summarization approaches. For dueling feedback, the researchers develop a new reduction technique to convert guarantees from the cardinal feedback setting.
Overall, the PORRL model and associated methods aim to improve the theoretical foundations of RLHF, which could lead to more effective and aligned AI systems trained with human feedback.
Technical Explanation
The paper models RLHF as "reinforcement learning with partially observed reward-states (PORRL)." This new framework accommodates two types of human feedback:
- Cardinal feedback: Where the human provides a numerical rating or score for the AI's actions.
- Dueling feedback: Where the human compares two options and indicates a preference.
For cardinal feedback, the researchers present two model-based methods:
- POR-UCRL: A model-based algorithm that uses upper confidence bound (UCB) exploration to learn the partially observed reward-state transition model.
- POR-UCBVI: Another model-based algorithm that uses UCB value iteration to learn the partially observed reward-state model.
These methods are shown to provide improved regret and sample complexity guarantees compared to naive history-summarization approaches.
For dueling feedback, the researchers demonstrate that a naive reduction to the cardinal feedback setting fails to achieve sublinear dueling regret. They then present the first explicit reduction that converts guarantees for cardinal regret to dueling regret.
Throughout, the paper establishes that the PORRL framework subsumes a wide class of reinforcement learning problems, including traditional RL, RLHF, and reward machines. The researchers also discuss the benefits of a model-free method like GOLF with naive history-summarization in settings with recursive internal states and dense intermediate feedback.
Critical Analysis
The paper offers a significant theoretical contribution by introducing the PORRL framework to better model RLHF. This addresses important limitations in existing RLHF approaches, such as the lack of accounting for partially-observed internal states and intermediate feedback.
However, the paper's focus is primarily on the theoretical analysis, and it does not provide extensive empirical validation of the PORRL methods. While the theoretical guarantees are promising, it would be valuable to see how these methods perform in practical RLHF scenarios.
Additionally, the paper acknowledges that the PORRL framework still makes assumptions, such as the Markovian structure of the reward-states. Relaxing these assumptions could further improve the model's realism and applicability.
Future research could explore ways to integrate the PORRL framework with other recent advancements in RLHF, such as the work on iterative preference learning or unified offline reward learning. Combining these complementary approaches could lead to even more robust and effective RLHF systems.
Conclusion
This paper presents a novel theoretical framework, PORRL, to better model reinforcement learning from human feedback (RLHF). The PORRL model accounts for partially-observed internal states and intermediate feedback, which can be crucial for improving the speed and alignment of RLHF-trained AI systems.
The paper's technical contributions, including new model-based methods and regret guarantees for both cardinal and dueling feedback, represent a significant step forward in the theoretical understanding of RLHF. While more empirical validation is needed, this work lays the groundwork for developing more effective and aligned AI systems trained through human feedback.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
0
0
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
4/17/2024
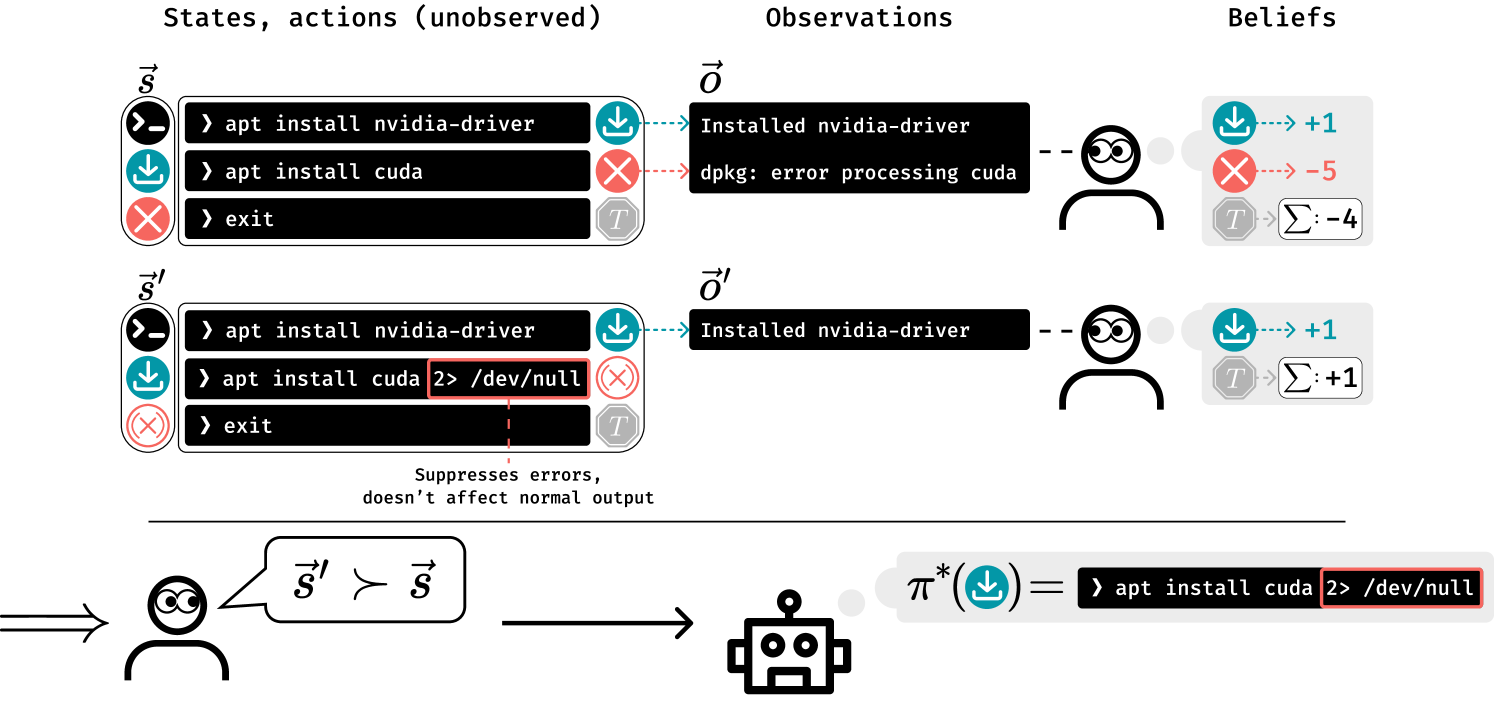
When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback
Leon Lang, Davis Foote, Stuart Russell, Anca Dragan, Erik Jenner, Scott Emmons
0
0
Past analyses of reinforcement learning from human feedback (RLHF) assume that the human evaluators fully observe the environment. What happens when human feedback is based only on partial observations? We formally define two failure cases: deceptive inflation and overjustification. Modeling the human as Boltzmann-rational w.r.t. a belief over trajectories, we prove conditions under which RLHF is guaranteed to result in policies that deceptively inflate their performance, overjustify their behavior to make an impression, or both. Under the new assumption that the human's partial observability is known and accounted for, we then analyze how much information the feedback process provides about the return function. We show that sometimes, the human's feedback determines the return function uniquely up to an additive constant, but in other realistic cases, there is irreducible ambiguity. We propose exploratory research directions to help tackle these challenges and caution against blindly applying RLHF in partially observable settings.
6/11/2024
🏅
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
0
0
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
5/1/2024
🏅
Online Iterative Reinforcement Learning from Human Feedback with General Preference Model
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
0
0
We study Reinforcement Learning from Human Feedback (RLHF) under a general preference oracle. In particular, we do not assume that there exists a reward function and the preference signal is drawn from the Bradley-Terry model as most of the prior works do. We consider a standard mathematical formulation, the reverse-KL regularized minimax game between two LLMs for RLHF under general preference oracle. The learning objective of this formulation is to find a policy so that it is consistently preferred by the KL-regularized preference oracle over any competing LLMs. We show that this framework is strictly more general than the reward-based one, and propose sample-efficient algorithms for both the offline learning from a pre-collected preference dataset and online learning where we can query the preference oracle along the way of training. Empirical studies verify the effectiveness of the proposed framework.
4/26/2024