ThinK: Thinner Key Cache by Query-Driven Pruning

0

Sign in to get full access
Overview
- The paper introduces ThinK, a technique for reducing the memory footprint of key-value caches used in large language models.
- ThinK uses query-driven pruning to selectively remove less important key-value pairs from the cache, making it "thinner" and more memory-efficient.
- The key innovations include a novel pruning algorithm and an adaptive caching mechanism that adjusts the cache size based on the current workload.
Plain English Explanation
ThinK: Thinner Key Cache by Query-Driven Pruning is a technique for optimizing the memory usage of key-value caches in large language models. These caches store key-value pairs that help the model quickly retrieve relevant information during inference.
The main idea behind ThinK is to selectively remove less important key-value pairs from the cache, making it "thinner" and more memory-efficient. This is done through a novel pruning algorithm that analyzes the current query and determines which cache entries are least useful. By pruning the cache in this query-driven way, ThinK can significantly reduce the memory footprint without significantly impacting the model's accuracy or performance.
ThinK also includes an adaptive caching mechanism that adjusts the cache size based on the current workload. This helps ensure that the cache is always an appropriate size, further improving efficiency.
Technical Explanation
The key-value cache is a crucial component of large language models, allowing them to quickly retrieve relevant information during inference. However, the size of these caches can become prohibitively large, especially for deployed models with limited memory resources.
ThinK addresses this problem by using a query-driven pruning algorithm to selectively remove less important key-value pairs from the cache. The algorithm analyzes the current query and the relevance of each cache entry, then removes the least useful entries to "thin" the cache.
The adaptive caching mechanism in ThinK adjusts the cache size based on the current workload, ensuring that the cache is not too large or too small. This helps maintain the performance benefits of the cache while minimizing the memory footprint.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to reducing the memory footprint of key-value caches in large language models. The query-driven pruning algorithm and adaptive caching mechanism are novel and appear to be effective based on the experimental results.
However, the paper does not discuss any potential limitations or caveats of the ThinK approach. For example, it would be useful to know how the pruning algorithm performs in edge cases, such as when the cache is already very small or when the query patterns change significantly over time. Additionally, the paper could have explored the trade-offs between cache size, model accuracy, and inference latency in more depth.
Conclusion
ThinK is a promising technique for reducing the memory footprint of key-value caches in large language models. By using a query-driven pruning algorithm and an adaptive caching mechanism, ThinK can significantly reduce memory usage without significantly impacting model performance. This could be particularly useful for deploying large language models on resource-constrained devices or in edge computing scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ThinK: Thinner Key Cache by Query-Driven Pruning
Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, Doyen Sahoo
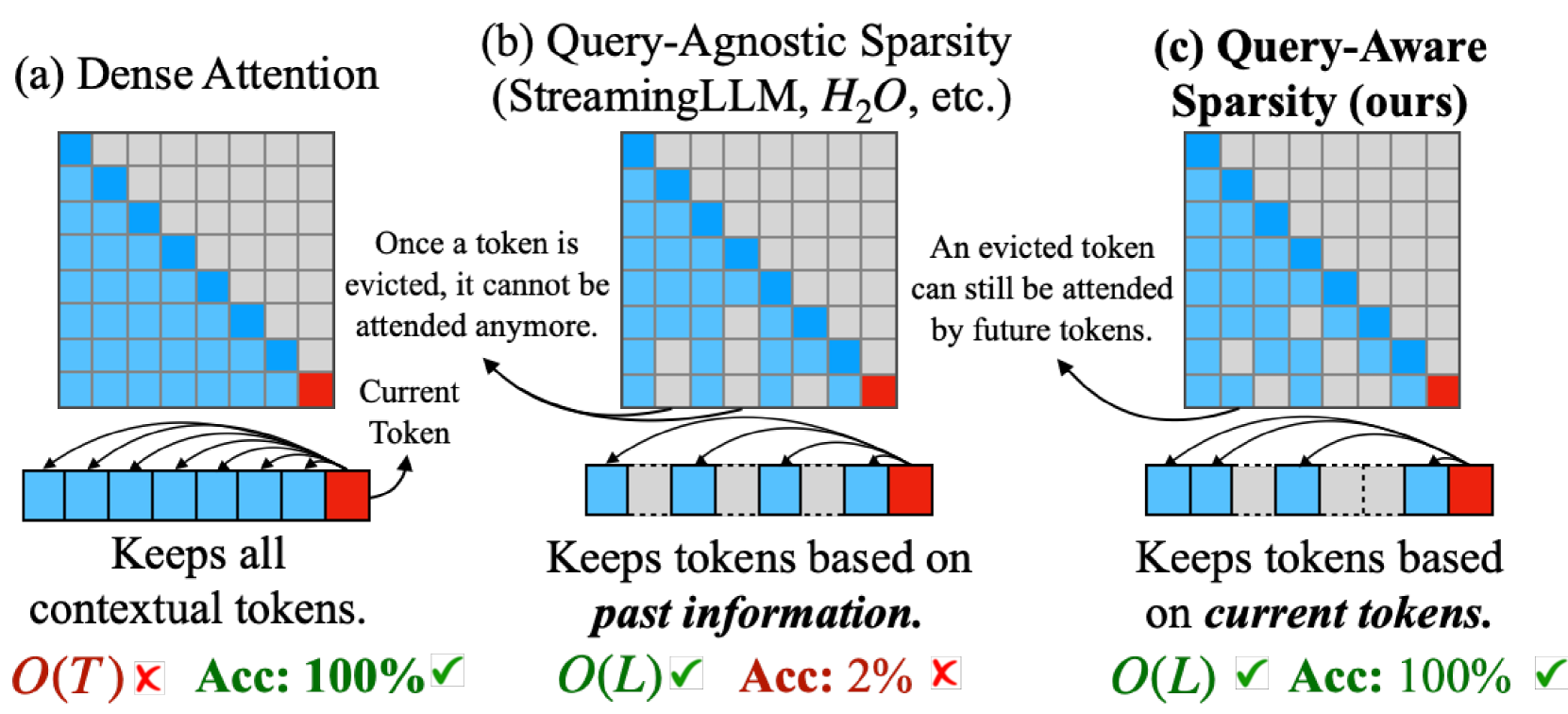
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications by leveraging increased model sizes and sequence lengths. However, the associated rise in computational and memory costs poses significant challenges, particularly in managing long sequences due to the quadratic complexity of the transformer attention mechanism. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory consumption during inference. Unlike existing approaches that optimize the memory based on the sequence lengths, we uncover that the channel dimension of the KV cache exhibits significant redundancy, characterized by unbalanced magnitude distribution and low-rank structure in attention weights. Based on these observations, we propose ThinK, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels. Our approach not only maintains or enhances model accuracy but also achieves a reduction in memory costs by over 20% compared with vanilla KV cache eviction methods. Extensive evaluations on the LLaMA3 and Mistral models across various long-sequence datasets confirm the efficacy of ThinK, setting a new precedent for efficient LLM deployment without compromising performance. We also outline the potential of extending our method to value cache pruning, demonstrating ThinK's versatility and broad applicability in reducing both memory and computational overheads.
Read more7/31/2024
0
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, Song Han
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss. Code is available at http://github.com/mit-han-lab/Quest .
Read more8/28/2024
🛸
0
SnapKV: LLM Knows What You are Looking for Before Generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, Deming Chen
Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an 'observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to the baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to the baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
Read more6/18/2024
0
CORM: Cache Optimization with Recent Message for Large Language Model Inference
Jincheng Dai, Zhuowei Huang, Haiyun Jiang, Chen Chen, Deng Cai, Wei Bi, Shuming Shi
Large Language Models (LLMs), despite their remarkable performance across a wide range of tasks, necessitate substantial GPU memory and consume significant computational resources. Beyond the memory taken up by model weights, the memory used by the KV cache rises linearly with sequence length, becoming a primary bottleneck for inference. In this paper, we introduce an innovative method for optimizing the KV cache, which considerably minimizes its memory footprint. Upon thorough investigation, we discover that in most Transformer models, (i) there is a striking similarity between adjacent tokens' query vectors, and (ii) the attention calculation of the current query can rely exclusively on the attention information of a small fraction of preceding queries. Based on these observations, we present CORM, a KV cache eviction policy that dynamically retains essential key-value pairs for inference without the need for model fine-tuning. Our validation shows that CORM reduces the inference memory usage of KV cache by up to 70% with negligible performance degradation across six tasks in LongBench. Furthermore, we demonstrate that CORM is compatible with GQA for further compression rate.
Read more6/24/2024