Threshold Decision-Making Dynamics Adaptive to Physical Constraints and Changing Environment
2312.06395
0
0
📉
Abstract
We propose a threshold decision-making framework for controlling the physical dynamics of an agent switching between two spatial tasks. Our framework couples a nonlinear opinion dynamics model that represents the evolution of an agent's preference for a particular task with the physical dynamics of the agent. We prove the bifurcation that governs the behavior of the coupled dynamics. We show by means of the bifurcation behavior how the coupled dynamics are adaptive to the physical constraints of the agent. We also show how the bifurcation can be modulated to allow the agent to switch tasks based on thresholds adaptive to environmental conditions. We illustrate the benefits of the approach through a decentralized multi-robot task allocation application for trash collection.
Create account to get full access
Overview
- The paper explores the dynamics of decision-making in spatial environments, focusing on how physical constraints and changes in the environment can influence the decision-making process.
- It proposes a model that captures the nonlinear opinion dynamics of decision-makers and how they adapt to different scenarios.
- The research aims to provide insights into how decision-making processes can be made more robust and adaptive to changing conditions.
Plain English Explanation
When people make decisions, they often consider the physical environment and any constraints or changes that might affect the outcome. This paper looks at how decision-making dynamics can adapt to these factors.
The researchers developed a model that simulates how people's opinions or "decisions" can change in a spatial environment, like a city or a workplace. The model takes into account things like physical barriers, obstacles, or changes in the environment over time. It shows how people's decisions can shift in a nonlinear way, meaning the changes aren't always predictable or proportional to the changes in the environment.
By understanding this adaptive decision-making process, the researchers hope to find ways to make decision-making more flexible and resilient to different situations. This could be useful in fields like urban planning, robotics, or automated systems where decisions need to be made quickly and effectively in changing environments.
Technical Explanation
The paper presents a model of nonlinear opinion dynamics in spatial decision-making. It assumes that decision-makers are influenced by their neighbors' opinions, as well as physical constraints and changes in the environment. The model uses a Kuramoto-type oscillator equation to capture the collective dynamics of the decision-makers.
The researchers conducted simulations to explore how the decision-making dynamics adapt to different scenarios, such as the introduction of physical barriers or changes in the environment over time. They found that the system can exhibit both "switching" and "threshold" behavior, depending on the parameters and environmental conditions.
In the "switching" regime, the system can transition between multiple stable states, corresponding to different collective decisions. In the "threshold" regime, the system is more sensitive to changes in the environment and can exhibit abrupt transitions between decision states.
The insights from this research could be applicable to various domains, such as robotic motion planning and legged locomotion, where decision-making processes must adapt to changing physical constraints and environments.
Critical Analysis
The paper provides a novel theoretical framework for understanding decision-making dynamics in spatial environments. The use of the Kuramoto-type oscillator model is a well-established approach in the study of collective dynamics, and the researchers have extended it to capture the interplay between decision-making and physical constraints.
One potential limitation of the study is the simplicity of the model, which may not fully capture the complexity of real-world decision-making scenarios. The researchers acknowledge this and suggest that future work could incorporate additional factors, such as social influence, heterogeneity among decision-makers, and more detailed representations of the physical environment.
Moreover, the paper does not provide empirical validation of the model's predictions. Testing the model's performance against experimental data or real-world observations would help strengthen the claims and potential applications of the research.
Despite these caveats, the paper offers a valuable contribution to the understanding of how decision-making processes can adapt to changing physical constraints and environmental conditions. The insights could inspire further research and applications in fields such as urban planning, robotics, and autonomous systems.
Conclusion
The paper presents a model of nonlinear opinion dynamics that captures the adaptive nature of decision-making in spatial environments. It demonstrates how physical constraints and changes in the environment can influence the collective behavior of decision-makers, leading to either "switching" or "threshold" dynamics.
The insights from this research could have important implications for the design of robust and adaptive decision-making systems that can effectively navigate changing physical environments and constraints. Further development and empirical validation of the model could lead to advancements in various fields that require flexible and context-aware decision-making processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Adaptive Framework for Manipulator Skill Reproduction in Dynamic Environments
Ryan Donald, Brendan Hertel, Stephen Misenti, Yan Gu, Reza Azadeh
0
0
Robot skill learning and execution in uncertain and dynamic environments is a challenging task. This paper proposes an adaptive framework that combines Learning from Demonstration (LfD), environment state prediction, and high-level decision making. Proactive adaptation prevents the need for reactive adaptation, which lags behind changes in the environment rather than anticipating them. We propose a novel LfD representation, Elastic-Laplacian Trajectory Editing (ELTE), which continuously adapts the trajectory shape to predictions of future states. Then, a high-level reactive system using an Unscented Kalman Filter (UKF) and Hidden Markov Model (HMM) prevents unsafe execution in the current state of the dynamic environment based on a discrete set of decisions. We first validate our LfD representation in simulation, then experimentally assess the entire framework using a legged mobile manipulator in 36 real-world scenarios. We show the effectiveness of the proposed framework under different dynamic changes in the environment. Our results show that the proposed framework produces robust and stable adaptive behaviors.
5/27/2024

Online Pareto-Optimal Decision-Making for Complex Tasks using Active Inference
Peter Amorese, Shohei Wakayama, Nisar Ahmed, Morteza Lahijanian
0
0
When a robot autonomously performs a complex task, it frequently must balance competing objectives while maintaining safety. This becomes more difficult in uncertain environments with stochastic outcomes. Enhancing transparency in the robot's behavior and aligning with user preferences are also crucial. This paper introduces a novel framework for multi-objective reinforcement learning that ensures safe task execution, optimizes trade-offs between objectives, and adheres to user preferences. The framework has two main layers: a multi-objective task planner and a high-level selector. The planning layer generates a set of optimal trade-off plans that guarantee satisfaction of a temporal logic task. The selector uses active inference to decide which generated plan best complies with user preferences and aids learning. Operating iteratively, the framework updates a parameterized learning model based on collected data. Case studies and benchmarks on both manipulation and mobile robots show that our framework outperforms other methods and (i) learns multiple optimal trade-offs, (ii) adheres to a user preference, and (iii) allows the user to adjust the balance between (i) and (ii).
6/19/2024

Adaptive Gait Modeling and Optimization for Principally Kinematic Systems
Siming Deng, Noah J. Cowan, Brian A. Bittner
0
0
Robotic adaptation to unanticipated operating conditions is crucial to achieving persistence and robustness in complex real world settings. For a wide range of cutting-edge robotic systems, such as micro- and nano-scale robots, soft robots, medical robots, and bio-hybrid robots, it is infeasible to anticipate the operating environment a priori due to complexities that arise from numerous factors including imprecision in manufacturing, chemo-mechanical forces, and poorly understood contact mechanics. Drawing inspiration from data-driven modeling, geometric mechanics (or gauge theory), and adaptive control, we employ an adaptive system identification framework and demonstrate its efficacy in enhancing the performance of principally kinematic locomotors (those governed by Rayleigh dissipation or zero momentum conservation). We showcase the capability of the adaptive model to efficiently accommodate varying terrains and iteratively modified behaviors within a behavior optimization framework. This provides both the ability to improve fundamental behaviors and perform motion tracking to precision. Notably, we are capable of optimizing the gaits of the Purcell swimmer using approximately 10 cycles per link, which for the nine-link Purcell swimmer provides a factor of ten improvement in optimization speed over the state of the art. Beyond simply a computational speed up, this ten-fold improvement may enable this method to be successfully deployed for in-situ behavior refinement, injury recovery, and terrain adaptation, particularly in domains where simulations provide poor guides for the real world.
4/19/2024
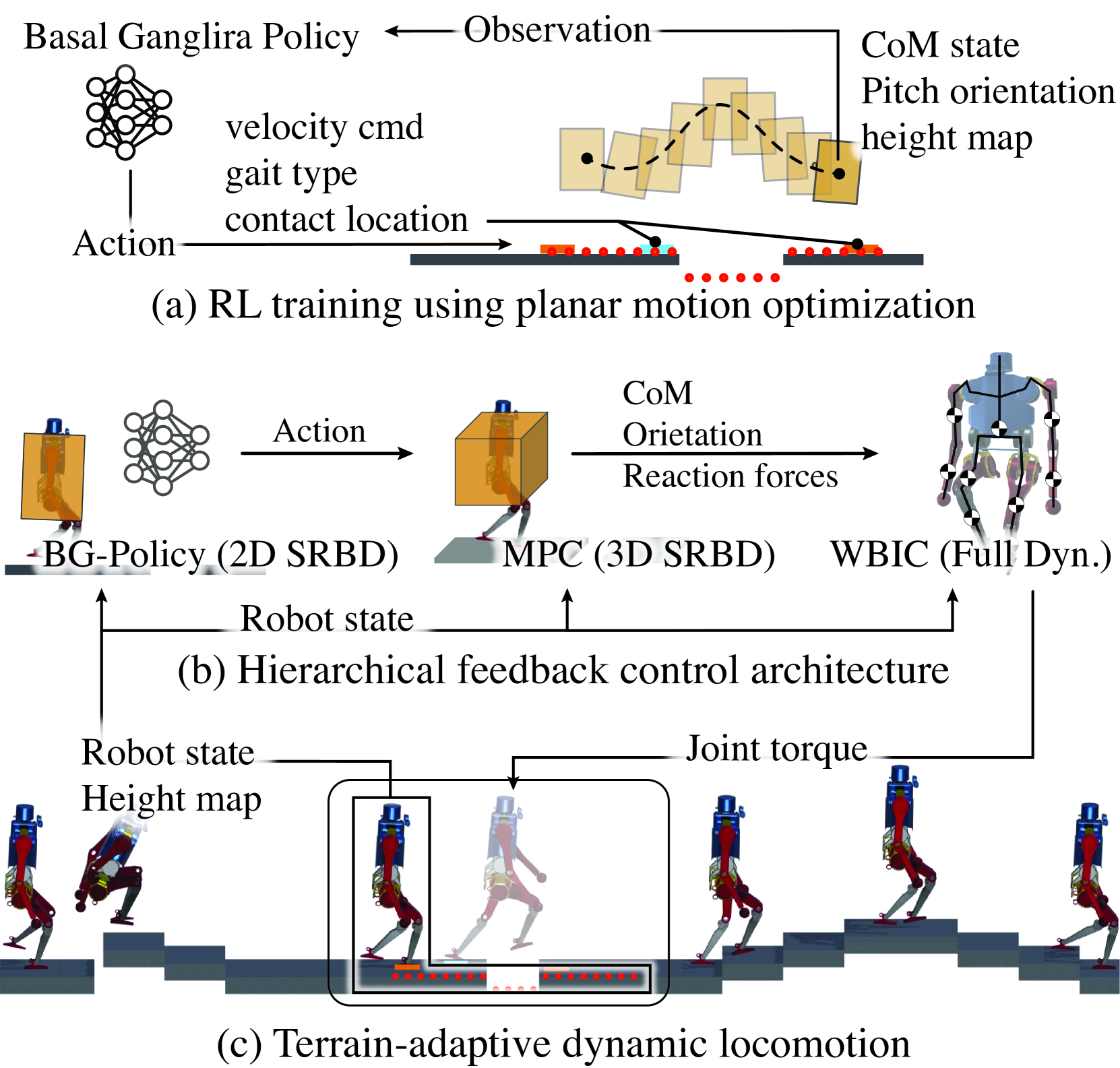
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
0
0
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
5/28/2024