TimeAutoDiff: Combining Autoencoder and Diffusion model for time series tabular data synthesizing
2406.16028
0
0

Abstract
In this paper, we leverage the power of latent diffusion models to generate synthetic time series tabular data. Along with the temporal and feature correlations, the heterogeneous nature of the feature in the table has been one of the main obstacles in time series tabular data modeling. We tackle this problem by combining the ideas of the variational auto-encoder (VAE) and the denoising diffusion probabilistic model (DDPM). Our model named as texttt{TimeAutoDiff} has several key advantages including (1) Generality: the ability to handle the broad spectrum of time series tabular data from single to multi-sequence datasets; (2) Good fidelity and utility guarantees: numerical experiments on six publicly available datasets demonstrating significant improvements over state-of-the-art models in generating time series tabular data, across four metrics measuring fidelity and utility; (3) Fast sampling speed: entire time series data generation as opposed to the sequential data sampling schemes implemented in the existing diffusion-based models, eventually leading to significant improvements in sampling speed, (4) Entity conditional generation: the first implementation of conditional generation of multi-sequence time series tabular data with heterogenous features in the literature, enabling scenario exploration across multiple scientific and engineering domains. Codes are in preparation for release to the public, but available upon request.
Create account to get full access
Overview
- Presents a novel approach called TimeAutoDiff for synthesizing time series tabular data
- Combines an autoencoder and a diffusion model to generate realistic and diverse synthetic data
- Aims to address the challenges of modeling complex temporal dependencies and mixed data types in tabular data
Plain English Explanation
TimeAutoDiff is a new method for generating synthetic time series tabular data. It combines two powerful machine learning techniques - an autoencoder and a diffusion model - to create realistic and diverse artificial data.
The autoencoder learns a compact representation of the input data, capturing its key features. The diffusion model generates new samples by adding noise to this representation and then gradually removing the noise, similar to how a image can be created from random noise.
This combined approach allows TimeAutoDiff to model the complex temporal dependencies and mixed data types (e.g. numerical, categorical) often found in real-world tabular datasets. The generated synthetic data can then be used to train other machine learning models or for data augmentation, without the privacy concerns of using the original data.
Technical Explanation
TimeAutoDiff is a novel framework that leverages an autoencoder and a diffusion model to synthesize time series tabular data. The autoencoder learns a compressed representation of the input data, capturing its key features. The diffusion model then generates new samples by adding noise to this representation and gradually removing the noise, similar to how a high-quality image can be created from random noise.
This combined approach allows TimeAutoDiff to effectively model the complex temporal dependencies and mixed data types (e.g. numerical, categorical) often found in real-world tabular datasets. The generated synthetic data can then be used to train other machine learning models or for data augmentation, without the privacy concerns of using the original data.
Critical Analysis
The authors acknowledge several limitations and areas for future research. For example, the performance of TimeAutoDiff may be sensitive to the choice of hyperparameters and architecture, and the method has not been extensively evaluated on a wide range of real-world datasets. Additionally, the paper does not provide a comprehensive comparison to other state-of-the-art tabular data synthesis methods, which could help contextualize the strengths and weaknesses of the approach.
Further research could explore ways to improve the stability and robustness of the TimeAutoDiff framework, as well as investigate its applicability to causal modeling and counterfactual generation tasks. Integrating additional techniques, such as variable interaction modeling, could also enhance the method's ability to capture complex relationships in the data.
Conclusion
TimeAutoDiff presents a promising approach for synthesizing high-quality time series tabular data by combining the strengths of autoencoders and diffusion models. The method's ability to model temporal dependencies and mixed data types makes it a valuable tool for a variety of applications, such as data augmentation, privacy-preserving data sharing, and synthetic data generation for machine learning. As the field of tabular data synthesis continues to evolve, techniques like TimeAutoDiff will play an important role in unlocking the potential of this data for a wide range of research and real-world use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
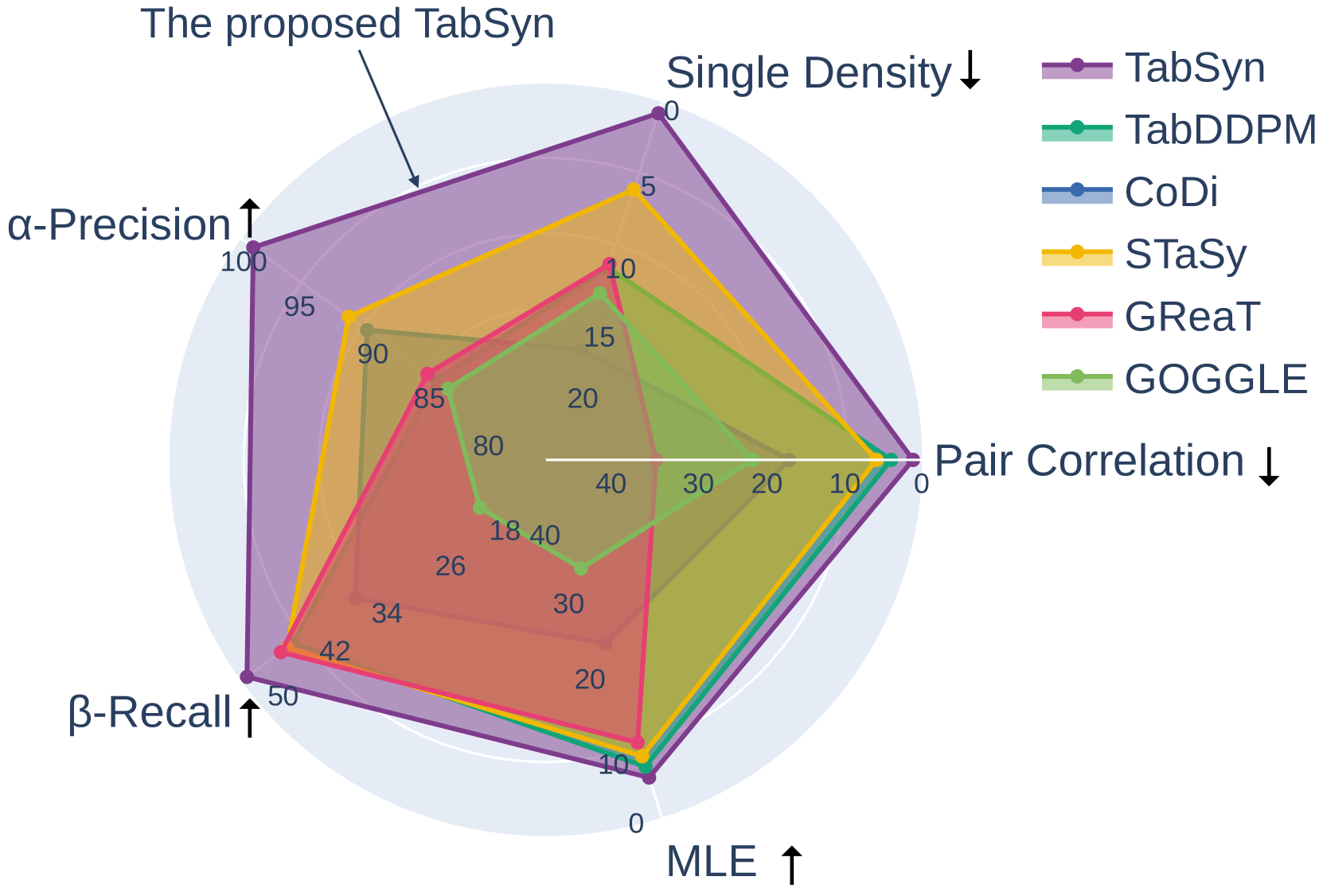
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
5/14/2024
An improved tabular data generator with VAE-GMM integration
Patricia A. Apell'aniz, Juan Parras, Santiago Zazo
0
0
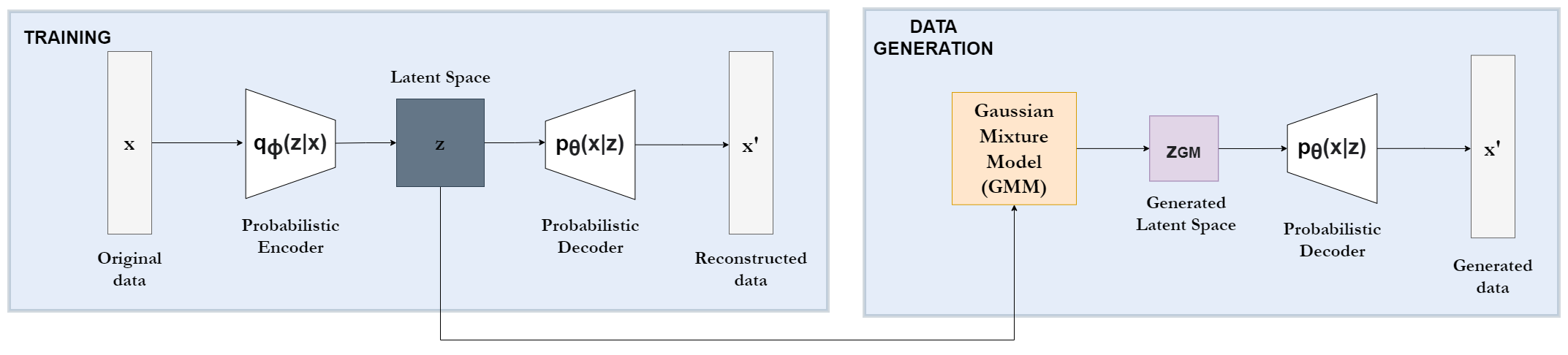
The rising use of machine learning in various fields requires robust methods to create synthetic tabular data. Data should preserve key characteristics while addressing data scarcity challenges. Current approaches based on Generative Adversarial Networks, such as the state-of-the-art CTGAN model, struggle with the complex structures inherent in tabular data. These data often contain both continuous and discrete features with non-Gaussian distributions. Therefore, we propose a novel Variational Autoencoder (VAE)-based model that addresses these limitations. Inspired by the TVAE model, our approach incorporates a Bayesian Gaussian Mixture model (BGM) within the VAE architecture. This avoids the limitations imposed by assuming a strictly Gaussian latent space, allowing for a more accurate representation of the underlying data distribution during data generation. Furthermore, our model offers enhanced flexibility by allowing the use of various differentiable distributions for individual features, making it possible to handle both continuous and discrete data types. We thoroughly validate our model on three real-world datasets with mixed data types, including two medically relevant ones, based on their resemblance and utility. This evaluation demonstrates significant outperformance against CTGAN and TVAE, establishing its potential as a valuable tool for generating synthetic tabular data in various domains, particularly in healthcare.
4/15/2024

New!Diffusion Models for Tabular Data Imputation and Synthetic Data Generation
Mario Villaiz'an-Vallelado, Matteo Salvatori, Carlos Segura, Ioannis Arapakis
0
0
Data imputation and data generation have important applications for many domains, like healthcare and finance, where incomplete or missing data can hinder accurate analysis and decision-making. Diffusion models have emerged as powerful generative models capable of capturing complex data distributions across various data modalities such as image, audio, and time series data. Recently, they have been also adapted to generate tabular data. In this paper, we propose a diffusion model for tabular data that introduces three key enhancements: (1) a conditioning attention mechanism, (2) an encoder-decoder transformer as the denoising network, and (3) dynamic masking. The conditioning attention mechanism is designed to improve the model's ability to capture the relationship between the condition and synthetic data. The transformer layers help model interactions within the condition (encoder) or synthetic data (decoder), while dynamic masking enables our model to efficiently handle both missing data imputation and synthetic data generation tasks within a unified framework. We conduct a comprehensive evaluation by comparing the performance of diffusion models with transformer conditioning against state-of-the-art techniques, such as Variational Autoencoders, Generative Adversarial Networks and Diffusion Models, on benchmark datasets. Our evaluation focuses on the assessment of the generated samples with respect to three important criteria, namely: (1) Machine Learning efficiency, (2) statistical similarity, and (3) privacy risk mitigation. For the task of data imputation, we consider the efficiency of the generated samples across different levels of missing features.
7/4/2024

Neural Network Parameter Diffusion
Kai Wang, Zhaopan Xu, Yukun Zhou, Zelin Zang, Trevor Darrell, Zhuang Liu, Yang You
0
0
Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also textit{generate high-performing neural network parameters}. Our approach is simple, utilizing an autoencoder and a standard latent diffusion model. The autoencoder extracts latent representations of a subset of the trained network parameters. A diffusion model is then trained to synthesize these latent parameter representations from random noise. It then generates new representations that are passed through the autoencoder's decoder, whose outputs are ready to use as new subsets of network parameters. Across various architectures and datasets, our diffusion process consistently generates models of comparable or improved performance over trained networks, with minimal additional cost. Notably, we empirically find that the generated models are not memorizing the trained networks. Our results encourage more exploration on the versatile use of diffusion models.
5/29/2024