TinySV: Speaker Verification in TinyML with On-device Learning

0

Sign in to get full access
Overview
- This paper introduces TinySV, a speaker verification system designed for tiny machine learning (TinyML) devices with on-device learning capabilities.
- The goal is to enable efficient and accurate speaker verification on resource-constrained IoT devices.
- Key aspects include a compact neural network architecture, on-device incremental learning, and strategies for managing speaker enrollment data.
Plain English Explanation
The paper describes a new speaker verification system called TinySV that is designed to work on small, low-power devices like smart home speakers or wearables. The main idea is to enable these devices to learn to recognize specific people's voices over time, without requiring a lot of computational power or memory.
Traditionally, speaker verification has been done on larger, more powerful computers or servers. But the researchers wanted to make this capability available on the tiny devices themselves, so users could authenticate their identity and access personalized features just by speaking.
To do this, they developed a compact neural network architecture that can run efficiently on resource-constrained hardware. They also came up with ways for the system to continuously learn and update its voice models, rather than requiring the entire training process to happen on a server. This allows the system to adapt to changes in a person's voice over time.
The paper discusses the technical details of how they achieved these goals, and presents experimental results showing the system's performance on different hardware platforms. Overall, the TinySV approach aims to bring robust speaker verification to the edge, enabling more personalized and secure experiences on a wide range of smart devices.
Technical Explanation
The core of the TinySV system is a compact neural network architecture designed for low-resource TinyML devices. It uses a combination of convolutional and recurrent layers to efficiently process audio data and extract speaker-discriminative features.
To enable on-device learning, the researchers developed an incremental learning strategy that allows the system to continuously update its speaker models without retraining the entire network from scratch. This is critical for adapting to changes in a user's voice over time.
They also addressed the challenge of managing speaker enrollment data on resource-constrained devices, proposing techniques to selectively retain and distill the most relevant information.
The paper presents experimental results evaluating TinySV's performance on different hardware platforms, including microcontrollers and embedded systems. The findings demonstrate the system's ability to achieve high accuracy while maintaining low computational and memory footprints.
Critical Analysis
The researchers acknowledge several limitations and areas for further exploration:
- The on-device learning capabilities of TinySV have only been evaluated in a simulated setting, and the real-world performance may differ.
- The data management strategies proposed in the paper rely on certain assumptions about the distribution of speaker enrollment data, which may not always hold true in practice.
- The experiments were conducted on a limited set of hardware platforms, and the system's performance may vary on other TinyML devices.
Additionally, while the paper addresses important challenges in bringing speaker verification to the edge, it would be valuable to explore other aspects, such as:
- The robustness of TinySV to noisy or diverse audio environments, which are common in real-world IoT settings.
- The security and privacy implications of storing and processing speaker models on-device, and how to mitigate potential risks.
- The integration of TinySV with other TinyML components or IoT systems to enable more holistic, personalized experiences.
Overall, the TinySV system represents an important step towards enabling efficient and adaptive speaker verification on resource-constrained devices. Further research and development in this area could lead to more secure and personalized interactions with a wide range of smart home, wearable, and IoT technologies.
Conclusion
The TinySV paper introduces a novel speaker verification system designed for tiny machine learning (TinyML) devices with on-device learning capabilities. By developing a compact neural network architecture and techniques for incremental learning and data management, the researchers have demonstrated the feasibility of bringing robust speaker verification to resource-constrained IoT platforms.
The proposed approach aims to enable personalized and secure experiences on a wide range of smart devices, from home assistants to wearables, by allowing them to continuously adapt to users' voices over time. While the paper highlights some limitations and areas for further exploration, the TinySV system represents an important step forward in the field of edge-based speaker recognition.
As the IoT ecosystem continues to expand, innovations like TinySV could play a crucial role in unlocking more personalized and intuitive interactions with the growing number of smart devices in our everyday lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TinySV: Speaker Verification in TinyML with On-device Learning
Massimo Pavan, Gioele Mombelli, Francesco Sinacori, Manuel Roveri
TinyML is a novel area of machine learning that gained huge momentum in the last few years thanks to the ability to execute machine learning algorithms on tiny devices (such as Internet-of-Things or embedded systems). Interestingly, research in this area focused on the efficient execution of the inference phase of TinyML models on tiny devices, while very few solutions for on-device learning of TinyML models are available in the literature due to the relevant overhead introduced by the learning algorithms. The aim of this paper is to introduce a new type of adaptive TinyML solution that can be used in tasks, such as the presented textit{Tiny Speaker Verification} (TinySV), that require to be tackled with an on-device learning algorithm. Achieving this goal required (i) reducing the memory and computational demand of TinyML learning algorithms, and (ii) designing a TinyML learning algorithm operating with few and possibly unlabelled training data. The proposed TinySV solution relies on a two-layer hierarchical TinyML solution comprising Keyword Spotting and Adaptive Speaker Verification module. We evaluated the effectiveness and efficiency of the proposed TinySV solution on a dataset collected expressly for the task and tested the proposed solution on a real-world IoT device (Infineon PSoC 62S2 Wi-Fi BT Pioneer Kit).
Read more6/5/2024
🤷
0
On-device Online Learning and Semantic Management of TinyML Systems
Haoyu Ren, Xue Li, Darko Anicic, Thomas A. Runkler
Recent advances in Tiny Machine Learning (TinyML) empower low-footprint embedded devices for real-time on-device Machine Learning. While many acknowledge the potential benefits of TinyML, its practical implementation presents unique challenges. This study aims to bridge the gap between prototyping single TinyML models and developing reliable TinyML systems in production: (1) Embedded devices operate in dynamically changing conditions. Existing TinyML solutions primarily focus on inference, with models trained offline on powerful machines and deployed as static objects. However, static models may underperform in the real world due to evolving input data distributions. We propose online learning to enable training on constrained devices, adapting local models towards the latest field conditions. (2) Nevertheless, current on-device learning methods struggle with heterogeneous deployment conditions and the scarcity of labeled data when applied across numerous devices. We introduce federated meta-learning incorporating online learning to enhance model generalization, facilitating rapid learning. This approach ensures optimal performance among distributed devices by knowledge sharing. (3) Moreover, TinyML's pivotal advantage is widespread adoption. Embedded devices and TinyML models prioritize extreme efficiency, leading to diverse characteristics ranging from memory and sensors to model architectures. Given their diversity and non-standardized representations, managing these resources becomes challenging as TinyML systems scale up. We present semantic management for the joint management of models and devices at scale. We demonstrate our methods through a basic regression example and then assess them in three real-world TinyML applications: handwritten character image classification, keyword audio classification, and smart building presence detection, confirming our approaches' effectiveness.
Read more5/17/2024
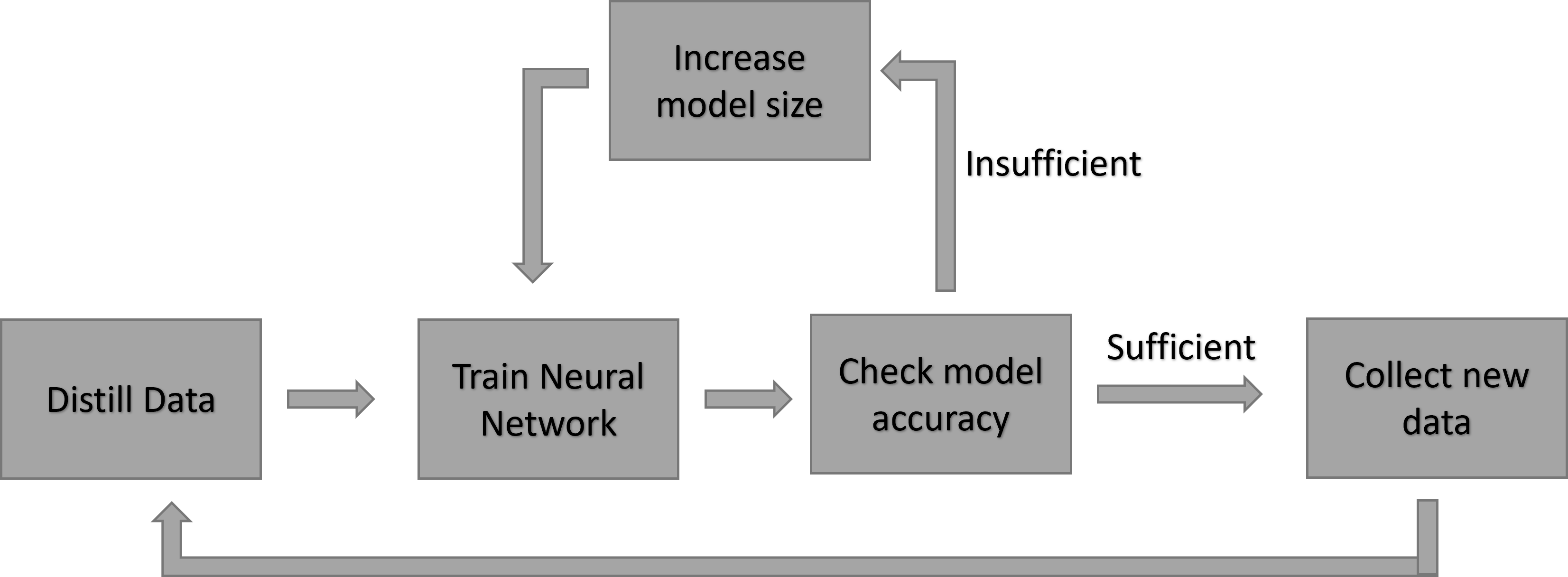
0
A Continual and Incremental Learning Approach for TinyML On-device Training Using Dataset Distillation and Model Size Adaption
Marcus Rub, Philipp Tuchel, Axel Sikora, Daniel Mueller-Gritschneder
A new algorithm for incremental learning in the context of Tiny Machine learning (TinyML) is presented, which is optimized for low-performance and energy efficient embedded devices. TinyML is an emerging field that deploys machine learning models on resource-constrained devices such as microcontrollers, enabling intelligent applications like voice recognition, anomaly detection, predictive maintenance, and sensor data processing in environments where traditional machine learning models are not feasible. The algorithm solve the challenge of catastrophic forgetting through the use of knowledge distillation to create a small, distilled dataset. The novelty of the method is that the size of the model can be adjusted dynamically, so that the complexity of the model can be adapted to the requirements of the task. This offers a solution for incremental learning in resource-constrained environments, where both model size and computational efficiency are critical factors. Results show that the proposed algorithm offers a promising approach for TinyML incremental learning on embedded devices. The algorithm was tested on five datasets including: CIFAR10, MNIST, CORE50, HAR, Speech Commands. The findings indicated that, despite using only 43% of Floating Point Operations (FLOPs) compared to a larger fixed model, the algorithm experienced a negligible accuracy loss of just 1%. In addition, the presented method is memory efficient. While state-of-the-art incremental learning is usually very memory intensive, the method requires only 1% of the original data set.
Read more9/12/2024
🗣️
0
Speech Understanding on Tiny Devices with A Learning Cache
Afsara Benazir (University of Virginia), Zhiming Xu (University of Virginia), Felix Xiaozhu Lin (University of Virginia)
This paper addresses spoken language understanding (SLU) on microcontroller-like embedded devices, integrating on-device execution with cloud offloading in a novel fashion. We leverage temporal locality in the speech inputs to a device and reuse recent SLU inferences accordingly. Our idea is simple: let the device match incoming inputs against cached results, and only offload inputs not matched to any cached ones to the cloud for full inference. Realization of this idea, however, is non-trivial: the device needs to compare acoustic features in a robust yet low-cost way. To this end, we present SpeechCache (or SC), a speech cache for tiny devices. It matches speech inputs at two levels of representations: first by sequences of clustered raw sound units, then as sequences of phonemes. Working in tandem, the two representations offer complementary tradeoffs between cost and efficiency. To boost accuracy even further, our cache learns to personalize: with the mismatched and then offloaded inputs, it continuously finetunes the device's feature extractors with the assistance of the cloud. We implement SC on an off-the-shelf STM32 microcontroller. The complete implementation has a small memory footprint of 2MB. Evaluated on challenging speech benchmarks, our system resolves 45%-90% of inputs on device, reducing the average latency by up to 80% compared to offloading to popular cloud speech recognition services. The benefit brought by our proposed SC is notable even in adversarial settings - noisy environments, cold cache, or one device shared by a number of users.
Read more5/9/2024