Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
2404.00702
0
0
💬
Abstract
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Recommender systems aim to predict user interest based on historical data
- Typically designed as sequential pipelines requiring large datasets to train
- Challenging to scale to new domains
- Large Language Models (LLMs) have shown remarkable generalized capabilities
- Existing LLM-based recommender systems only use LLM for a single task in the pipeline
- Difficulty in presenting large-scale item sets to LLMs due to input length constraints
Plain English Explanation
Recommender systems are designed to predict what a user might be interested in based on their past behavior. Traditionally, these systems are built as a series of steps, each of which requires a lot of data to train. This makes them hard to adapt to new areas.
However, recent advancements in large language models (LLMs) have shown that a single model can handle a wide variety of tasks. The researchers wanted to leverage this capability to create a more efficient and versatile recommender system.
The key challenge they faced was how to present large catalogs of items to the LLM, since LLMs have limits on the amount of text they can process at once. To solve this, the researchers developed a way to organize all the items into a hierarchical tree structure that can be efficiently accessed by the LLM.
This new framework, called UniLLMRec, combines multiple recommendation tasks (like finding relevant items, ranking them, and refining the rankings) into a single LLM-powered process. The researchers found that UniLLMRec can make recommendations without any prior training, and does so much more efficiently than previous LLM-based recommenders, reducing the input needed by 86%.
Technical Explanation
The researchers introduce UniLLMRec, an LLM-based end-to-end recommendation framework that integrates multiple recommendation tasks (recall, ranking, re-ranking) through a "chain-of-recommendations" approach. To handle large-scale item sets, they propose structuring all items into an "item tree" that can be dynamically updated and efficiently retrieved.
UniLLMRec leverages the generalized capabilities of LLMs to tackle diverse recommendation tasks across different scenarios, in contrast to prior LLM-based recommenders that only used the LLM for a single task in the pipeline. The researchers demonstrate promising zero-shot results for UniLLMRec compared to conventional supervised models.
Crucially, UniLLMRec achieves high efficiency, reducing the input token requirement by 86% compared to existing LLM-based recommendation systems. This not only accelerates task completion but also optimizes resource utilization. The researchers have made the code publicly available to facilitate model understanding and reproducibility.
Critical Analysis
The paper presents a compelling approach to leveraging the power of LLMs for more efficient and versatile recommender systems. The key innovations, such as the item tree structure and the chain-of-recommendations design, appear to be well-reasoned and effectively address the challenges of applying LLMs to real-world recommendation tasks.
However, the paper does not delve deeply into the limitations or potential issues with the UniLLMRec framework. For example, it would be useful to understand how the performance and efficiency of UniLLMRec compare to other state-of-the-art recommender systems, beyond just conventional supervised models.
Additionally, the researchers mention the "zero-shot" capabilities of UniLLMRec, but more details on the specific zero-shot tasks and their evaluation would help readers better understand the broader applicability of the approach. Further research exploring the adaptability of UniLLMRec to new domains and datasets could also strengthen the claims about its generalized capabilities.
Conclusion
The UniLLMRec framework presented in this paper represents a promising step forward in leveraging the power of large language models for more efficient and versatile recommender systems. By integrating multiple recommendation tasks into a single LLM-based process and developing innovative strategies to handle large-scale item sets, the researchers have demonstrated a compelling approach to improving the scalability and performance of recommender systems.
While the paper leaves some questions unanswered, the core ideas and the publicly available code provide a solid foundation for further exploration and development in this area. As LLMs continue to expand their capabilities, the potential for using them to transform recommender systems and unlock new possibilities in personalized recommendation is an exciting area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
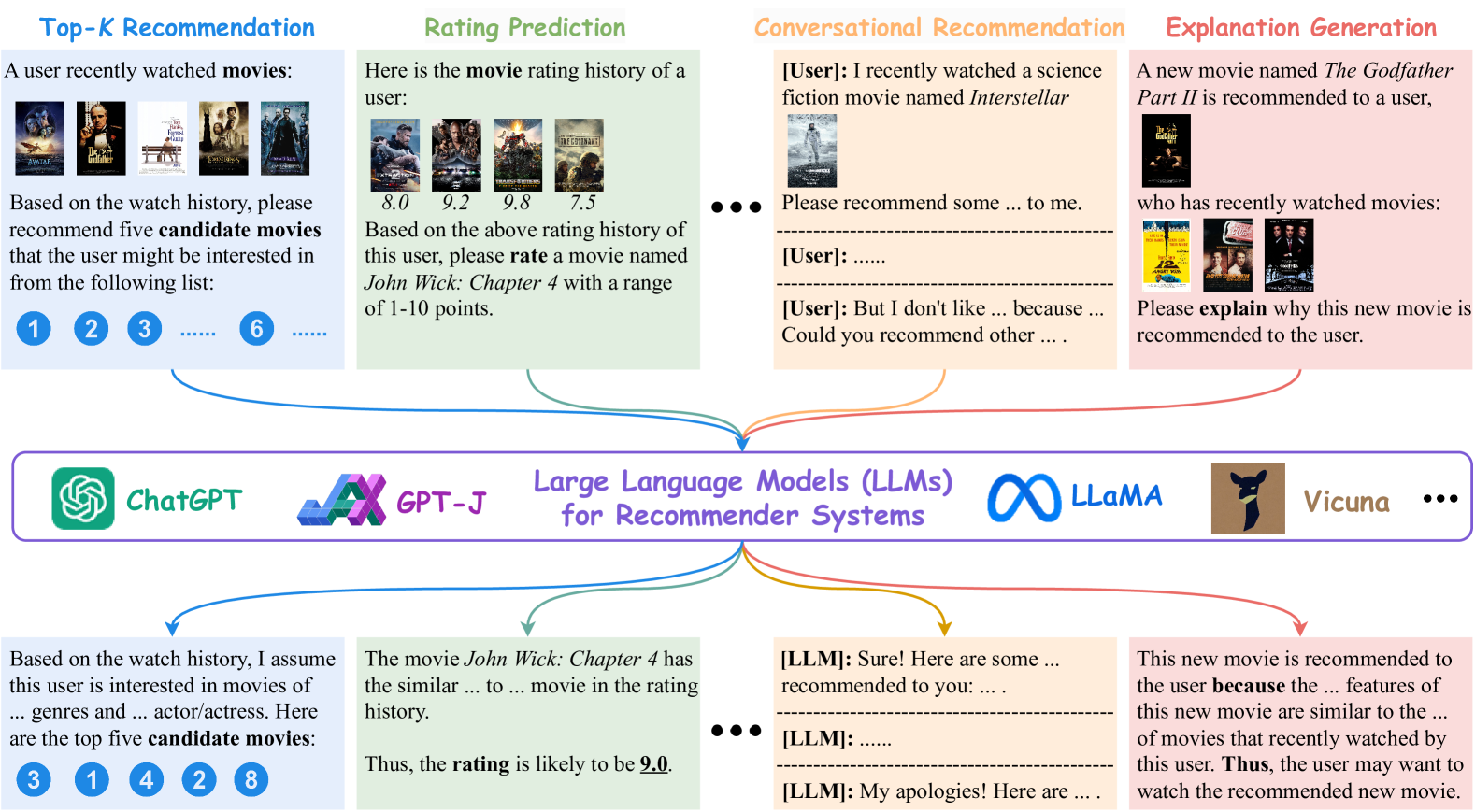
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
💬
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
0
0
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
4/22/2024

DynLLM: When Large Language Models Meet Dynamic Graph Recommendation
Ziwei Zhao, Fake Lin, Xi Zhu, Zhi Zheng, Tong Xu, Shitian Shen, Xueying Li, Zikai Yin, Enhong Chen
0
0
Last year has witnessed the considerable interest of Large Language Models (LLMs) for their potential applications in recommender systems, which may mitigate the persistent issue of data sparsity. Though large efforts have been made for user-item graph augmentation with better graph-based recommendation performance, they may fail to deal with the dynamic graph recommendation task, which involves both structural and temporal graph dynamics with inherent complexity in processing time-evolving data. To bridge this gap, in this paper, we propose a novel framework, called DynLLM, to deal with the dynamic graph recommendation task with LLMs. Specifically, DynLLM harnesses the power of LLMs to generate multi-faceted user profiles based on the rich textual features of historical purchase records, including crowd segments, personal interests, preferred categories, and favored brands, which in turn supplement and enrich the underlying relationships between users and items. Along this line, to fuse the multi-faceted profiles with temporal graph embedding, we engage LLMs to derive corresponding profile embeddings, and further employ a distilled attention mechanism to refine the LLM-generated profile embeddings for alleviating noisy signals, while also assessing and adjusting the relevance of each distilled facet embedding for seamless integration with temporal graph embedding from continuous time dynamic graphs (CTDGs). Extensive experiments on two real e-commerce datasets have validated the superior improvements of DynLLM over a wide range of state-of-the-art baseline methods.
5/14/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024