To Recommend or Not: Recommendability Identification in Conversations with Pre-trained Language Models
2403.18628
0
0
Abstract
Most current recommender systems primarily focus on what to recommend, assuming users always require personalized recommendations. However, with the widely spread of ChatGPT and other chatbots, a more crucial problem in the context of conversational systems is how to minimize user disruption when we provide recommendation services for users. While previous research has extensively explored different user intents in dialogue systems, fewer efforts are made to investigate whether recommendations should be provided. In this paper, we formally define the recommendability identification problem, which aims to determine whether recommendations are necessary in a specific scenario. First, we propose and define the recommendability identification task, which investigates the need for recommendations in the current conversational context. A new dataset is constructed. Subsequently, we discuss and evaluate the feasibility of leveraging pre-trained language models (PLMs) for recommendability identification. Finally, through comparative experiments, we demonstrate that directly employing PLMs with zero-shot results falls short of meeting the task requirements. Besides, fine-tuning or utilizing soft prompt techniques yields comparable results to traditional classification methods. Our work is the first to study recommendability before recommendation and provides preliminary ways to make it a fundamental component of the future recommendation system.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the task of identifying whether a given conversational response is "recommendable" or not, using pre-trained language models.
- The authors propose a new dataset and benchmark for this task, and investigate the performance of various language models on it.
- The findings provide insights into the challenges and opportunities in using large language models for conversational recommendation systems.
Plain English Explanation
The paper is focused on a specific challenge in conversational systems: determining whether a response is "recommendable" or not. In other words, is the response something that the system should recommend to the user, or should it avoid making a recommendation?
This is an important problem, as conversational systems are increasingly being used for tasks like product recommendations, information retrieval, and content curation. The ability to accurately identify when a response is "recommendable" can help these systems provide more relevant and useful information to users.
The authors of this paper have created a new dataset and benchmark to study this problem, and they've tested the performance of various pre-trained language models on the task. The findings suggest that while these models can be useful for conversational recommendation, there are still some challenges that need to be addressed, such as understanding the context and intent of the conversation.
Overall, this research represents an important step forward in improving the capabilities of conversational systems, and it could have significant implications for a wide range of applications, from personalized recommendation to content discovery.
Technical Explanation
The paper proposes a new task called "Recommendability Identification" (RI), which aims to determine whether a given conversational response is "recommendable" or not. The authors create a new dataset, called the Concept Evaluation Protocol for Conversation Recommender Systems (CEP-CR), to benchmark this task.
The dataset consists of conversational dialogues, where each response is labeled as either "recommendable" or "not recommendable". The authors then evaluate the performance of various pre-trained language models, such as BERT, GPT-2, and T5, on the RI task using this dataset.
The results show that while these models can achieve reasonably good performance on the task, there are still some challenges. For example, the models struggle to capture the contextual and pragmatic aspects of the conversation, which are crucial for accurately identifying whether a response is recommendable or not.
The authors also discuss several potential directions for future research, such as incorporating additional signals (e.g., user preferences, domain knowledge) to improve the models' understanding of the conversation and better identify recommendable responses.
Critical Analysis
The paper presents a novel and important task in the realm of conversational systems and recommender systems. The creation of the CEP-CR dataset is a valuable contribution, as it provides a standardized benchmark for evaluating the performance of language models on the RI task.
However, the paper also acknowledges some limitations of the current approach. For instance, the authors note that the models struggle to capture the contextual and pragmatic aspects of the conversation, which are crucial for accurately identifying recommendable responses. This suggests that further research is needed to develop more sophisticated language understanding capabilities in this domain.
Additionally, the paper does not explore the potential biases or fairness implications of the RI task and the models' performance. It would be important to investigate whether the models exhibit any demographic or other biases in their recommendations, and to consider ways to mitigate such issues.
Overall, this paper represents an important step forward in the field of conversational recommendation systems. The insights and challenges it identifies can serve as a valuable starting point for future research in this area, as researchers and practitioners work to develop more robust and reliable systems for providing users with helpful and relevant recommendations in conversational contexts.
Conclusion
This paper presents a novel task called "Recommendability Identification" (RI), which aims to determine whether a given conversational response is "recommendable" or not. The authors create a new dataset and benchmark for this task, and evaluate the performance of various pre-trained language models on it.
The findings provide valuable insights into the challenges and opportunities in using large language models for conversational recommendation systems. While the models can achieve reasonably good performance on the RI task, they still struggle to capture the contextual and pragmatic aspects of the conversation, which are crucial for accurately identifying recommendable responses.
The research in this paper represents an important step towards improving the capabilities of conversational systems, with potential applications in a wide range of areas, from personalized recommendation to content discovery. As the field continues to evolve, further research will be needed to address the challenges identified in this paper and develop more robust and reliable conversational recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
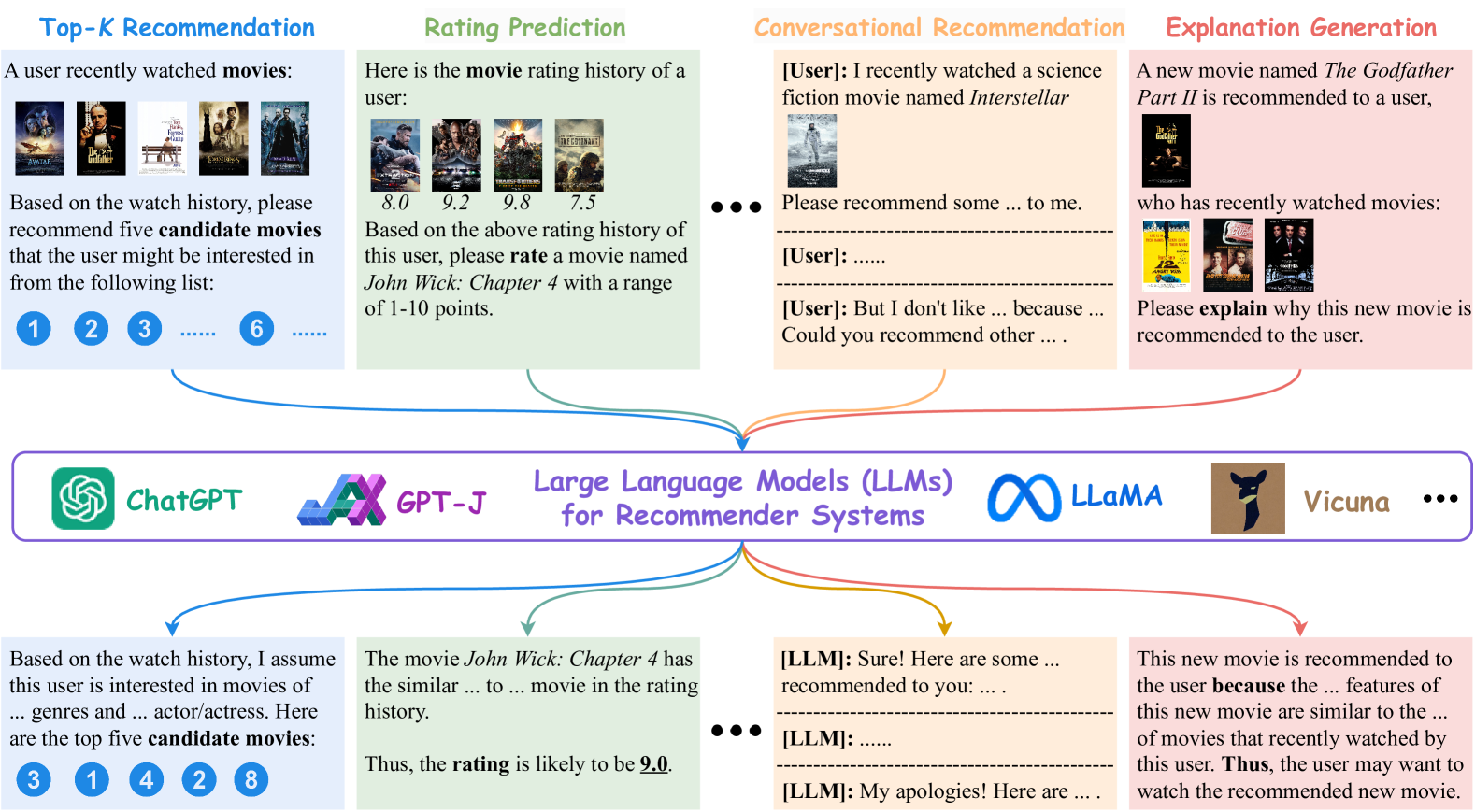
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang, Kun Gai
0
0
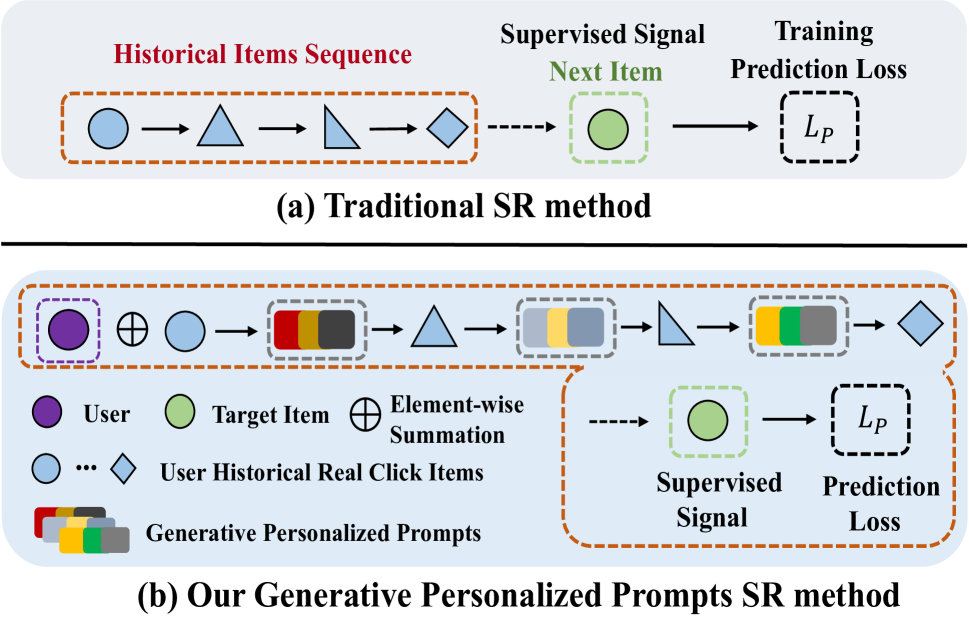
ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
4/16/2024
The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
Zekai Qu, Ruobing Xie, Chaojun Xiao, Xingwu Sun, Zhanhui Kang
0
0
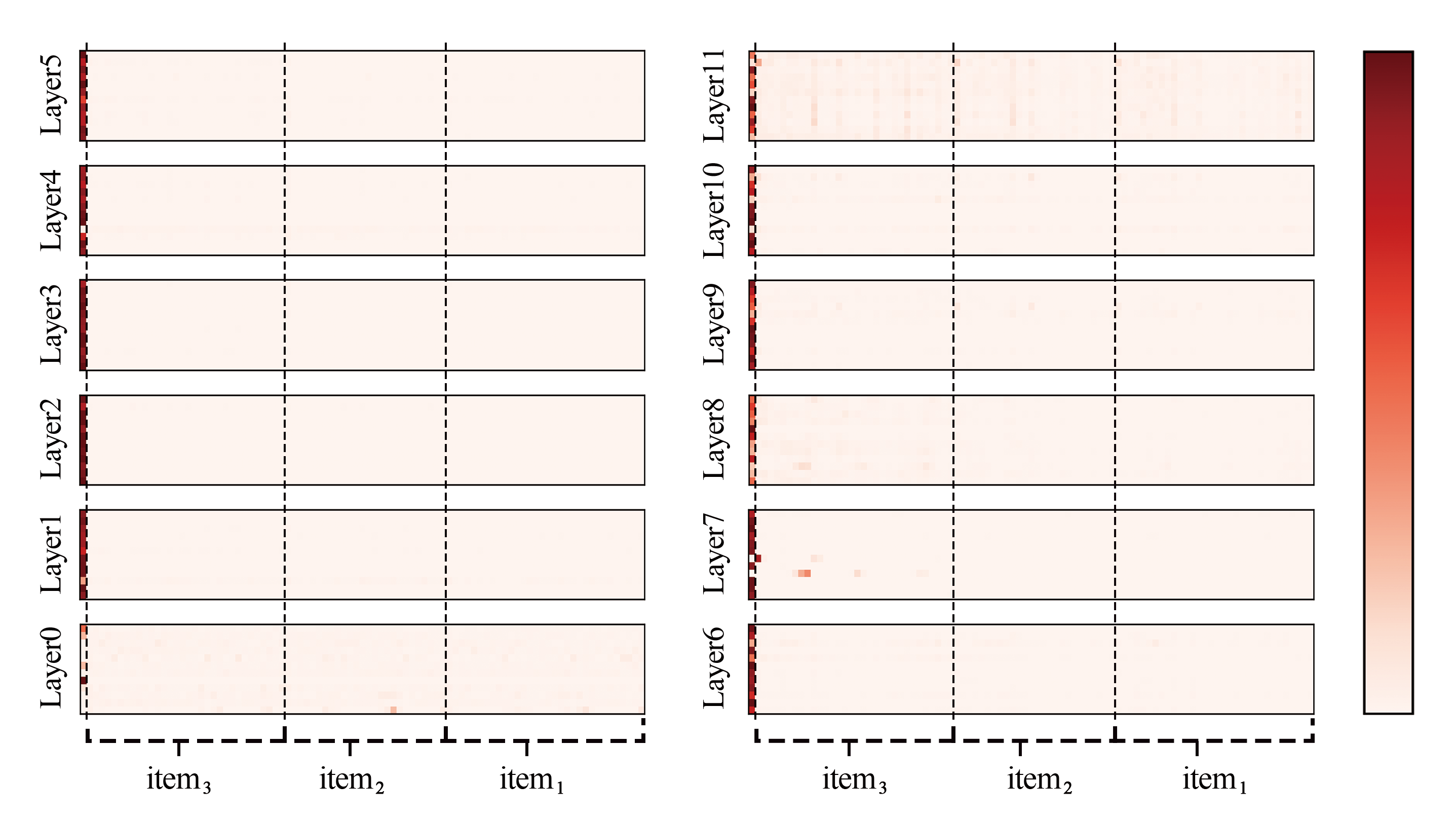
Sequential recommendation (SR) has seen significant advancements with the help of Pre-trained Language Models (PLMs). Some PLM-based SR models directly use PLM to encode user historical behavior's text sequences to learn user representations, while there is seldom an in-depth exploration of the capability and suitability of PLM in behavior sequence modeling. In this work, we first conduct extensive model analyses between PLMs and PLM-based SR models, discovering great underutilization and parameter redundancy of PLMs in behavior sequence modeling. Inspired by this, we explore different lightweight usages of PLMs in SR, aiming to maximally stimulate the ability of PLMs for SR while satisfying the efficiency and usability demands of practical systems. We discover that adopting behavior-tuned PLMs for item initializations of conventional ID-based SR models is the most economical framework of PLM-based SR, which would not bring in any additional inference cost but could achieve a dramatic performance boost compared with the original version. Extensive experiments on five datasets show that our simple and universal framework leads to significant improvement compared to classical SR and SOTA PLM-based SR models without additional inference costs.
4/16/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024