Token Turing Machines are Efficient Vision Models

0

Sign in to get full access
Overview
- Token Turing Machines (TTMs) are a new efficient vision model that outperforms existing models in performance and efficiency.
- TTMs leverage the power of Turing Machines to process visual information, achieving state-of-the-art results on various computer vision benchmarks.
- The research demonstrates TTMs' ability to learn robust visual representations while requiring fewer parameters and computations compared to other vision models.
Plain English Explanation
Token Turing Machines are Efficient Vision Models presents a novel approach to building vision models using the principles of Turing Machines. Traditional vision models, such as Convolutional Neural Networks (CNNs), process images by applying a series of mathematical operations. In contrast, Token Turing Machines treat the image as a sequence of "tokens" and use a Turing Machine-inspired architecture to process this sequence.
The key idea is that a Turing Machine, with its ability to read, write, and move along a tape, can be an effective way to understand and manipulate visual information. The researchers demonstrate that TTMs can learn powerful visual representations while requiring fewer parameters and computations compared to other state-of-the-art vision models. This makes TTMs an attractive option for applications where efficiency and performance are critical, such as on mobile devices or in resource-constrained environments.
The researchers evaluate TTMs on a range of computer vision benchmarks and show that they achieve competitive or better results than leading vision models, like Transformers and CNNs. This suggests that the Turing Machine-inspired approach can be a viable and efficient alternative to existing vision architectures.
Technical Explanation
Token Turing Machines are Efficient Vision Models proposes a novel vision model called the Token Turing Machine (TTM) that takes inspiration from the principles of Turing Machines. The key innovation is to treat an image as a sequence of "tokens" and use a Turing Machine-like architecture to process this sequence.
The TTM architecture consists of a Token Encoder that converts the input image into a sequence of tokens, a Turing Machine Core that processes the token sequence, and a Token Decoder that generates the final output. The Turing Machine Core is the heart of the model and is responsible for reading, writing, and moving along the token sequence, much like a Turing Machine.
The researchers evaluate TTMs on various computer vision benchmarks, including image classification, object detection, and semantic segmentation. They demonstrate that TTMs can achieve competitive or better performance compared to state-of-the-art vision models, such as Transformers and CNNs, while requiring fewer parameters and computations.
The efficiency of TTMs is attributed to their ability to learn powerful visual representations using the Turing Machine-inspired architecture. By processing the image as a sequence of tokens, TTMs can focus on the most relevant parts of the input, leading to more efficient and effective inference.
Critical Analysis
The research presented in Token Turing Machines are Efficient Vision Models is innovative and promising, but there are a few aspects that could be further explored or addressed.
One potential limitation is the lack of a detailed analysis of the Turing Machine Core's inner workings and the specific mechanisms that enable the efficient processing of visual information. A deeper dive into the architectural choices and design principles behind the Turing Machine Core could provide further insights into the model's strengths and weaknesses.
Additionally, while the paper showcases TTMs' performance on various benchmarks, it would be valuable to understand the model's robustness and generalization capabilities in more real-world and diverse settings. Evaluating TTMs on a wider range of tasks and datasets could help assess their broader applicability and potential limitations.
Another area for further research could be exploring the interpretability and explainability of TTMs. Understanding how the Turing Machine-inspired architecture processes and makes decisions about visual information could lead to valuable insights for the computer vision community.
Conclusion
Token Turing Machines are Efficient Vision Models presents a novel and promising approach to building efficient vision models using the principles of Turing Machines. The researchers demonstrate that TTMs can achieve state-of-the-art performance on various computer vision tasks while requiring fewer parameters and computations compared to existing models.
The Turing Machine-inspired architecture allows TTMs to learn powerful visual representations by processing images as sequences of tokens. This efficiency makes TTMs an attractive option for applications where resource constraints are a concern, such as on mobile devices or in edge computing environments.
Overall, the research showcases the potential of leveraging Turing Machine-based approaches for computer vision and opens up new avenues for exploring the synergies between theoretical computer science and practical machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Token Turing Machines are Efficient Vision Models
Purvish Jajal, Nick John Eliopoulos, Benjamin Shiue-Hal Chou, George K. Thiravathukal, James C. Davis, Yung-Hsiang Lu
We propose Vision Token Turing Machines (ViTTM), an efficient, low-latency, memory-augmented Vision Transformer (ViT). Our approach builds on Neural Turing Machines and Token Turing Machines, which were applied to NLP and sequential visual understanding tasks. ViTTMs are designed for non-sequential computer vision tasks such as image classification and segmentation. Our model creates two sets of tokens: process tokens and memory tokens; process tokens pass through encoder blocks and read-write from memory tokens at each encoder block in the network, allowing them to store and retrieve information from memory. By ensuring that there are fewer process tokens than memory tokens, we are able to reduce the inference time of the network while maintaining its accuracy. On ImageNet-1K, the state-of-the-art ViT-B has median latency of 529.5ms and 81.0% accuracy, while our ViTTM-B is 56% faster (234.1ms), with 2.4 times fewer FLOPs, with an accuracy of 82.9%. On ADE20K semantic segmentation, ViT-B achieves 45.65mIoU at 13.8 frame-per-second (FPS) whereas our ViTTM-B model acheives a 45.17 mIoU with 26.8 FPS (+94%).
Read more9/14/2024

0
LookupViT: Compressing visual information to a limited number of tokens
Rajat Koner, Gagan Jain, Prateek Jain, Volker Tresp, Sujoy Paul
Vision Transformers (ViT) have emerged as the de-facto choice for numerous industry grade vision solutions. But their inference cost can be prohibitive for many settings, as they compute self-attention in each layer which suffers from quadratic computational complexity in the number of tokens. On the other hand, spatial information in images and spatio-temporal information in videos is usually sparse and redundant. In this work, we introduce LookupViT, that aims to exploit this information sparsity to reduce ViT inference cost. LookupViT provides a novel general purpose vision transformer block that operates by compressing information from higher resolution tokens to a fixed number of tokens. These few compressed tokens undergo meticulous processing, while the higher-resolution tokens are passed through computationally cheaper layers. Information sharing between these two token sets is enabled through a bidirectional cross-attention mechanism. The approach offers multiple advantages - (a) easy to implement on standard ML accelerators (GPUs/TPUs) via standard high-level operators, (b) applicable to standard ViT and its variants, thus generalizes to various tasks, (c) can handle different tokenization and attention approaches. LookupViT also offers flexibility for the compressed tokens, enabling performance-computation trade-offs in a single trained model. We show LookupViT's effectiveness on multiple domains - (a) for image-classification (ImageNet-1K and ImageNet-21K), (b) video classification (Kinetics400 and Something-Something V2), (c) image captioning (COCO-Captions) with a frozen encoder. LookupViT provides $2times$ reduction in FLOPs while upholding or improving accuracy across these domains. In addition, LookupViT also demonstrates out-of-the-box robustness and generalization on image classification (ImageNet-C,R,A,O), improving by up to $4%$ over ViT.
Read more7/18/2024

2
An Image is Worth 32 Tokens for Reconstruction and Generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
Read more6/12/2024
0
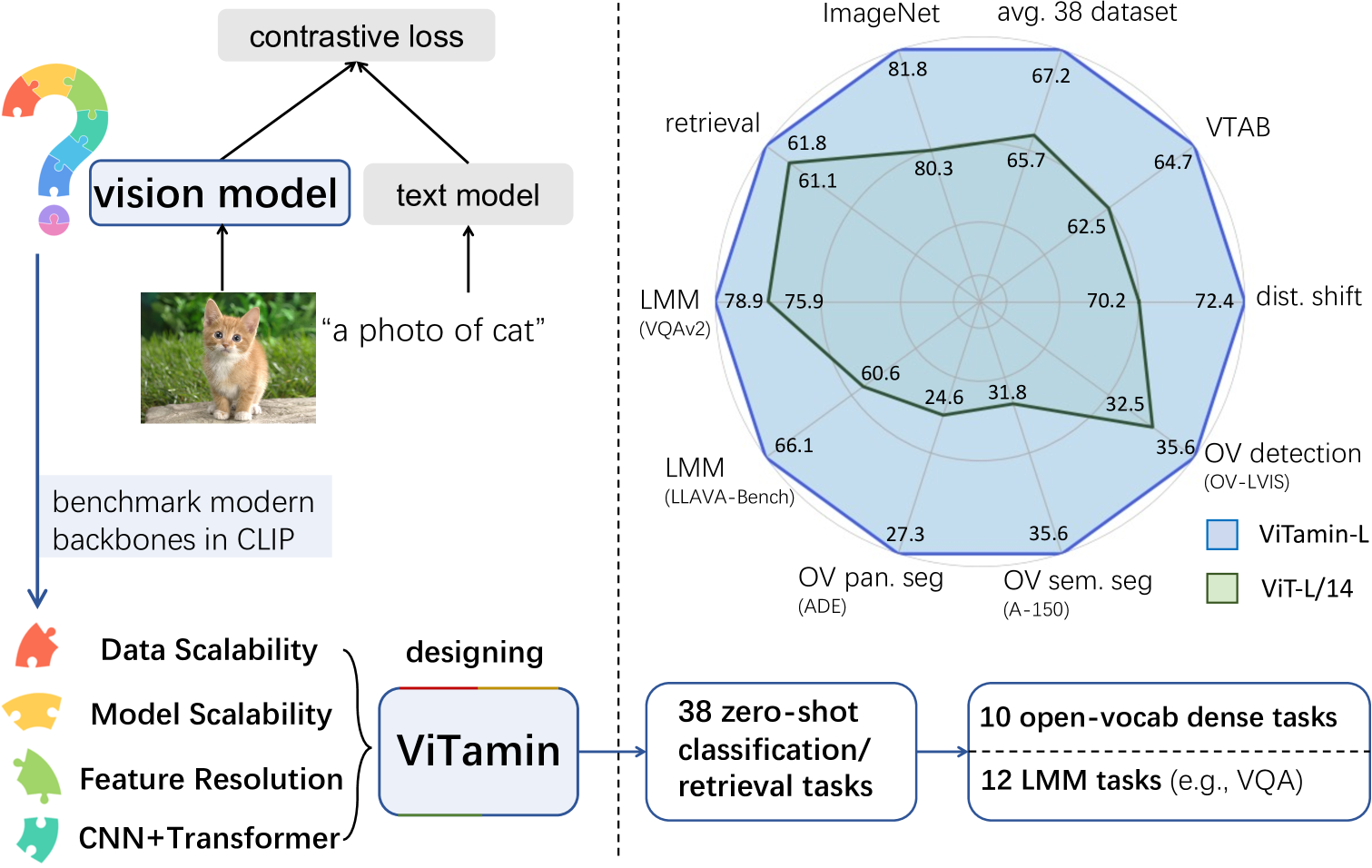
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
Read more4/5/2024