ToSA: Token Selective Attention for Efficient Vision Transformers
2406.08816
0
0

Abstract
In this paper, we propose a novel token selective attention approach, ToSA, which can identify tokens that need to be attended as well as those that can skip a transformer layer. More specifically, a token selector parses the current attention maps and predicts the attention maps for the next layer, which are then used to select the important tokens that should participate in the attention operation. The remaining tokens simply bypass the next layer and are concatenated with the attended ones to re-form a complete set of tokens. In this way, we reduce the quadratic computation and memory costs as fewer tokens participate in self-attention while maintaining the features for all the image patches throughout the network, which allows it to be used for dense prediction tasks. Our experiments show that by applying ToSA, we can significantly reduce computation costs while maintaining accuracy on the ImageNet classification benchmark. Furthermore, we evaluate on the dense prediction task of monocular depth estimation on NYU Depth V2, and show that we can achieve similar depth prediction accuracy using a considerably lighter backbone with ToSA.
Create account to get full access
Overview
- This paper introduces a new approach called \ours (Token Selective Attention for Efficient Vision Transformers) that aims to improve the efficiency of Vision Transformers (ViTs) by selectively attending to the most important tokens.
- The key idea is to identify a small subset of important tokens in each layer and only apply the full attention mechanism to those tokens, while the remaining tokens are processed with a more efficient alternative.
- This allows the model to focus its computational resources on the most relevant parts of the input, leading to significant speedups and memory savings without compromising performance.
Plain English Explanation
The paper presents a new technique called \ours that makes Vision Transformers (ViTs) more efficient. ViTs are a type of machine learning model that has been very successful in computer vision tasks, but they can be computationally expensive to run.
The main insight behind \ours is that not all the "tokens" (small patches of the input image) are equally important for the model's decision-making. By identifying the most crucial tokens and only applying the full attention mechanism to those, the model can achieve significant speedups and memory savings without sacrificing much performance.
The way \ours works is by first analyzing the input image and determining which tokens are the most important. It then focuses the bulk of its computational resources on processing those key tokens, while handling the remaining less important tokens in a more efficient but less sophisticated way. This allows the model to run faster and use less memory, which is especially valuable for deploying ViTs on resource-constrained devices like smartphones or embedded systems.
The paper demonstrates that \ours can achieve up to 2x speedups and 40% memory reductions on popular ViT models without losing much accuracy, making ViTs more practical for a wider range of real-world applications. This is an important advancement, as the efficiency of machine learning models is a critical factor in their widespread adoption and impact.
Technical Explanation
The key innovation in \ours is the Token Selective Attention module, which selectively applies the full attention mechanism only to the most important tokens in each layer of the ViT. This is in contrast to standard ViTs, which apply the computationally expensive attention operation uniformly across all tokens.
To identify the important tokens, \ours first passes the input image through a lightweight "importance prediction" network that outputs an importance score for each token. It then ranks the tokens by importance and applies the full attention mechanism only to the top-k most important ones, where k is a hyperparameter.
The remaining less important tokens are processed using a more efficient alternative, such as a simple linear transformation. This allows \ours to focus the model's capacity on the most relevant parts of the input, leading to significant efficiency gains.
The authors evaluate \ours on popular ViT models like DeiT and ViT, and show that it can achieve up to 2x speedups and 40% memory reductions on image classification tasks without compromising accuracy. They also demonstrate the versatility of \ours by applying it to other ViT-based architectures like You Only Need Less Attention at Each and TIC: Exploring Vision Transformer Convolution, achieving similar efficiency improvements.
Critical Analysis
The \ours approach is a clever way to improve the efficiency of ViTs, but it does come with some potential limitations. First, the accuracy of the importance prediction network is crucial, as errors in identifying the most important tokens could lead to a significant drop in performance. The authors do address this by exploring different importance prediction strategies, but more work may be needed to ensure robust and reliable token selection.
Additionally, the \ours approach may not be as effective on tasks where the importance of different tokens varies significantly across instances or during the course of inference. In such cases, a more dynamic or adaptive token selection mechanism might be more appropriate.
Another concern is the potential for the \ours approach to introduce additional hyperparameters, such as the number of important tokens (k) to select. Tuning these hyperparameters could be challenging and require additional computational resources, offsetting some of the efficiency gains.
Finally, the authors do not explore the generalization of \ours to other Vision Transformer-based architectures beyond the ones mentioned in the paper. Extending the approach to a wider range of ViT models and tasks would further demonstrate its versatility and impact.
Conclusion
The \ours approach presented in this paper is a promising step towards making Vision Transformers more efficient and practical for real-world applications. By selectively attending to the most important tokens, \ours can achieve significant speedups and memory savings without compromising much on performance.
This is an important advancement, as the efficiency of machine learning models is a critical factor in their widespread adoption and impact. \ours could help make ViTs more accessible for deployment on resource-constrained devices, opening up new opportunities for their use in various domains, from edge computing to mobile applications.
Overall, the \ours technique represents a valuable contribution to the ongoing efforts to improve the efficiency of Vision Transformers, and the insights from this work could inspire further advancements in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

You Only Need Less Attention at Each Stage in Vision Transformers
Shuoxi Zhang, Hanpeng Liu, Stephen Lin, Kun He
0
0
The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
6/4/2024
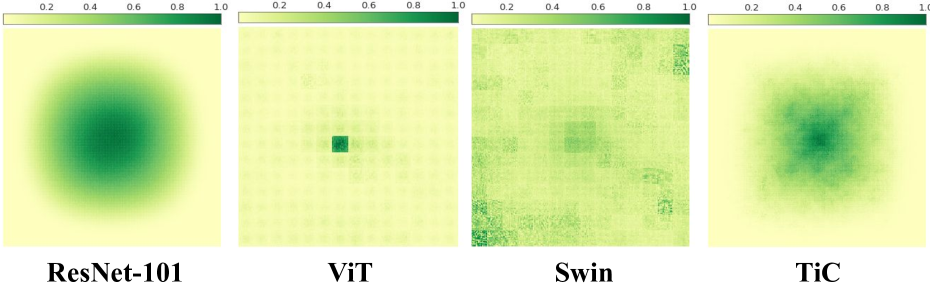
TiC: Exploring Vision Transformer in Convolution
Song Zhang, Qingzhong Wang, Jiang Bian, Haoyi Xiong
0
0
While models derived from Vision Transformers (ViTs) have been phonemically surging, pre-trained models cannot seamlessly adapt to arbitrary resolution images without altering the architecture and configuration, such as sampling the positional encoding, limiting their flexibility for various vision tasks. For instance, the Segment Anything Model (SAM) based on ViT-Huge requires all input images to be resized to 1024$times$1024. To overcome this limitation, we propose the Multi-Head Self-Attention Convolution (MSA-Conv) that incorporates Self-Attention within generalized convolutions, including standard, dilated, and depthwise ones. Enabling transformers to handle images of varying sizes without retraining or rescaling, the use of MSA-Conv further reduces computational costs compared to global attention in ViT, which grows costly as image size increases. Later, we present the Vision Transformer in Convolution (TiC) as a proof of concept for image classification with MSA-Conv, where two capacity enhancing strategies, namely Multi-Directional Cyclic Shifted Mechanism and Inter-Pooling Mechanism, have been proposed, through establishing long-distance connections between tokens and enlarging the effective receptive field. Extensive experiments have been carried out to validate the overall effectiveness of TiC. Additionally, ablation studies confirm the performance improvement made by MSA-Conv and the two capacity enhancing strategies separately. Note that our proposal aims at studying an alternative to the global attention used in ViT, while MSA-Conv meets our goal by making TiC comparable to state-of-the-art on ImageNet-1K. Code will be released at https://github.com/zs670980918/MSA-Conv.
5/28/2024
👀
Vision Transformer with Sparse Scan Prior
Qihang Fan, Huaibo Huang, Mingrui Chen, Ran He
0
0
In recent years, Transformers have achieved remarkable progress in computer vision tasks. However, their global modeling often comes with substantial computational overhead, in stark contrast to the human eye's efficient information processing. Inspired by the human eye's sparse scanning mechanism, we propose a textbf{S}parse textbf{S}can textbf{S}elf-textbf{A}ttention mechanism ($rm{S}^3rm{A}$). This mechanism predefines a series of Anchors of Interest for each token and employs local attention to efficiently model the spatial information around these anchors, avoiding redundant global modeling and excessive focus on local information. This approach mirrors the human eye's functionality and significantly reduces the computational load of vision models. Building on $rm{S}^3rm{A}$, we introduce the textbf{S}parse textbf{S}can textbf{Vi}sion textbf{T}ransformer (SSViT). Extensive experiments demonstrate the outstanding performance of SSViT across a variety of tasks. Specifically, on ImageNet classification, without additional supervision or training data, SSViT achieves top-1 accuracies of textbf{84.4%/85.7%} with textbf{4.4G/18.2G} FLOPs. SSViT also excels in downstream tasks such as object detection, instance segmentation, and semantic segmentation. Its robustness is further validated across diverse datasets. Code will be available at url{https://github.com/qhfan/SSViT}.
5/24/2024
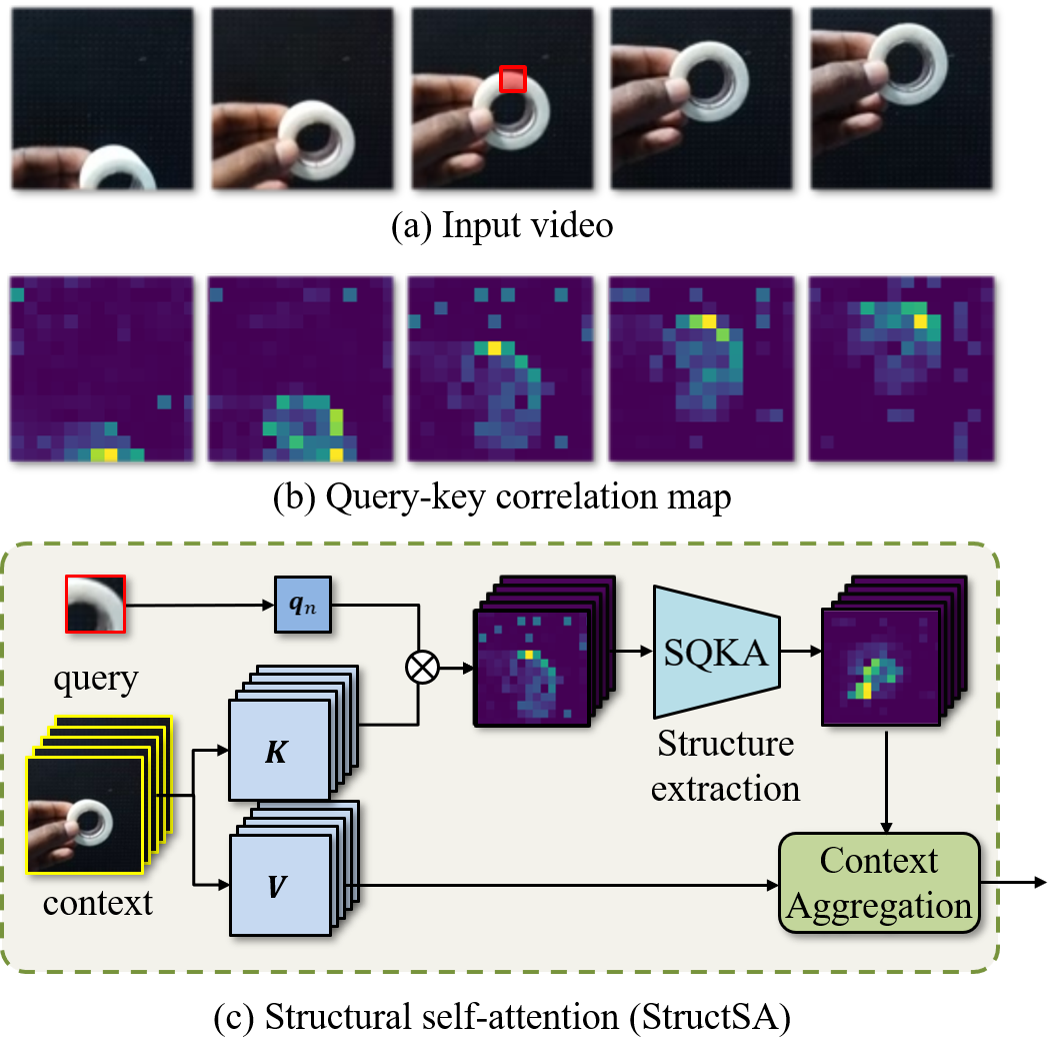
Learning Correlation Structures for Vision Transformers
Manjin Kim, Paul Hongsuck Seo, Cordelia Schmid, Minsu Cho
0
0
We introduce a new attention mechanism, dubbed structural self-attention (StructSA), that leverages rich correlation patterns naturally emerging in key-query interactions of attention. StructSA generates attention maps by recognizing space-time structures of key-query correlations via convolution and uses them to dynamically aggregate local contexts of value features. This effectively leverages rich structural patterns in images and videos such as scene layouts, object motion, and inter-object relations. Using StructSA as a main building block, we develop the structural vision transformer (StructViT) and evaluate its effectiveness on both image and video classification tasks, achieving state-of-the-art results on ImageNet-1K, Kinetics-400, Something-Something V1 & V2, Diving-48, and FineGym.
4/8/2024