You Only Need Less Attention at Each Stage in Vision Transformers
2406.00427
0
0

Abstract
The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
Create account to get full access
Overview
- This paper proposes a new approach to improving the efficiency of Vision Transformers (ViTs) called "You Only Need Less Attention at Each Stage" (YOLEAS).
- The key idea is to reduce the attention complexity in ViTs by decreasing the attention heads and dimensions at each stage of the network, while maintaining overall performance.
- The authors show that YOLEAS can achieve significant efficiency gains without sacrificing accuracy, making ViTs more practical for real-world applications.
Plain English Explanation
The paper introduces a new technique called YOLEAS to make Vision Transformers (ViTs) more efficient. ViTs are a type of deep learning model that uses attention mechanisms to process visual information, similar to how the human brain focuses on different parts of an image.
The main challenge with ViTs is that they can be computationally expensive, as the attention calculations require a lot of processing power. The YOLEAS approach addresses this by gradually reducing the complexity of the attention mechanisms as the model goes through its different stages.
Imagine you're trying to solve a complicated math problem. At first, you might need to focus on all the details and do a lot of calculations. But as you progress, you can start to simplify things and focus only on the most important parts. The YOLEAS method applies this same idea to ViTs, allowing them to become more efficient without losing their accuracy.
By reducing the number of attention heads (the parts of the model that focus on different aspects of the input) and the dimensionality of the attention itself, the authors show that ViTs can become much faster and more practical for real-world applications, such as image recognition or object detection, without sacrificing their performance.
Technical Explanation
The key innovation in this paper is the YOLEAS approach, which reduces the attention complexity in Vision Transformers (ViTs) at each stage of the network.
Typically, ViTs use a fixed number of attention heads and attention dimensions throughout the network. YOLEAS instead decreases these attention parameters as the model goes deeper, similar to the FasterViT and Nested-TNT approaches.
The authors hypothesize that earlier stages of the ViT can get by with more attention, while later stages can use less attention and still maintain performance. This is analogous to the intra-task mutual attention idea, where different parts of the network focus on different aspects of the input.
To test this, the authors conduct extensive experiments on ImageNet and other benchmark datasets, comparing YOLEAS-based ViTs to standard ViTs and other efficient variants like ViT-SAFE and Sparse Scan ViT. They demonstrate that YOLEAS can achieve significant efficiency gains (up to 2.3x faster inference) without sacrificing accuracy.
Critical Analysis
The YOLEAS approach presented in this paper is a promising step towards making Vision Transformers more practical and deployable in real-world applications. The authors provide a thorough evaluation and show impressive efficiency gains without compromising performance.
However, one potential limitation is that the reduction in attention complexity may not generalize well to all types of visual tasks or datasets. The authors primarily evaluate on ImageNet, and it would be valuable to see how YOLEAS performs on a broader range of computer vision benchmarks.
Additionally, while the authors discuss the intuition behind their approach, a deeper theoretical analysis of why gradually reducing attention complexity is effective could provide more insights and guide future work in this direction.
It would also be interesting to see how YOLEAS could be combined with other efficiency-enhancing techniques, such as ViT-SAFE's design techniques or the Sparse Scan ViT's sparse attention, to further push the boundaries of efficient Vision Transformers.
Conclusion
The "You Only Need Less Attention at Each Stage" (YOLEAS) approach proposed in this paper represents a significant advancement in making Vision Transformers more efficient and practical for real-world applications. By gradually reducing the attention complexity as the model goes deeper, the authors demonstrate substantial efficiency gains without sacrificing accuracy.
This work contributes to the ongoing efforts to make Vision Transformers more accessible and deployable, paving the way for their wider adoption in diverse computer vision tasks. The insights and techniques presented in this paper can inspire further research into efficient Transformer architectures and inspire the development of more powerful and cost-effective deep learning models for various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
FasterViT: Fast Vision Transformers with Hierarchical Attention
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov
0
0
We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy and image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
4/3/2024
👀
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Moein Heidari, Reza Azad, Sina Ghorbani Kolahi, Ren'e Arimond, Leon Niggemeier, Alaa Sulaiman, Afshin Bozorgpour, Ehsan Khodapanah Aghdam, Amirhossein Kazerouni, Ilker Hacihaliloglu, Dorit Merhof
0
0
Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}footnote{url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
4/1/2024
👀
Vision Transformer with Sparse Scan Prior
Qihang Fan, Huaibo Huang, Mingrui Chen, Ran He
0
0
In recent years, Transformers have achieved remarkable progress in computer vision tasks. However, their global modeling often comes with substantial computational overhead, in stark contrast to the human eye's efficient information processing. Inspired by the human eye's sparse scanning mechanism, we propose a textbf{S}parse textbf{S}can textbf{S}elf-textbf{A}ttention mechanism ($rm{S}^3rm{A}$). This mechanism predefines a series of Anchors of Interest for each token and employs local attention to efficiently model the spatial information around these anchors, avoiding redundant global modeling and excessive focus on local information. This approach mirrors the human eye's functionality and significantly reduces the computational load of vision models. Building on $rm{S}^3rm{A}$, we introduce the textbf{S}parse textbf{S}can textbf{Vi}sion textbf{T}ransformer (SSViT). Extensive experiments demonstrate the outstanding performance of SSViT across a variety of tasks. Specifically, on ImageNet classification, without additional supervision or training data, SSViT achieves top-1 accuracies of textbf{84.4%/85.7%} with textbf{4.4G/18.2G} FLOPs. SSViT also excels in downstream tasks such as object detection, instance segmentation, and semantic segmentation. Its robustness is further validated across diverse datasets. Code will be available at url{https://github.com/qhfan/SSViT}.
5/24/2024
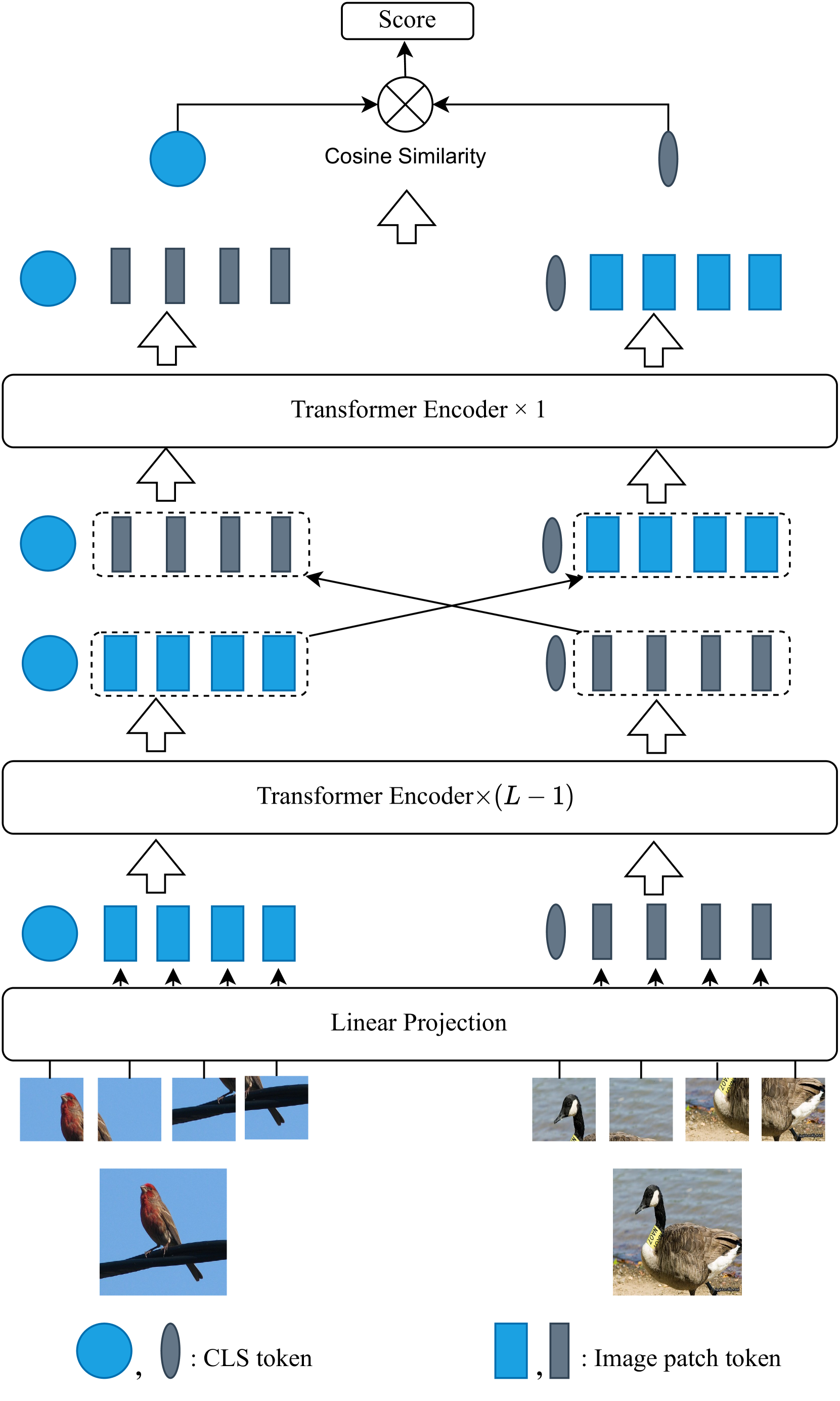
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024