TiC: Exploring Vision Transformer in Convolution
2310.04134
0
0
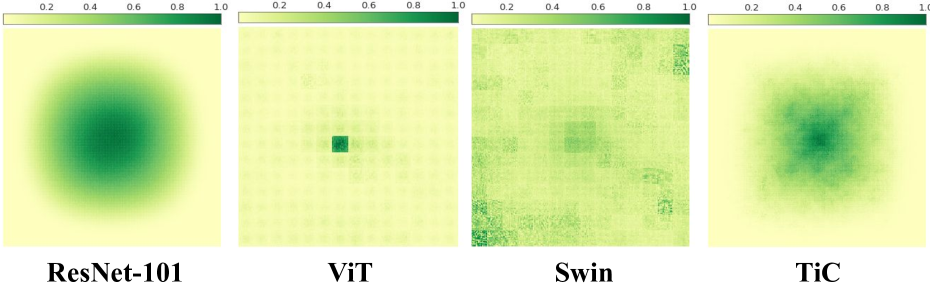
Abstract
While models derived from Vision Transformers (ViTs) have been phonemically surging, pre-trained models cannot seamlessly adapt to arbitrary resolution images without altering the architecture and configuration, such as sampling the positional encoding, limiting their flexibility for various vision tasks. For instance, the Segment Anything Model (SAM) based on ViT-Huge requires all input images to be resized to 1024$times$1024. To overcome this limitation, we propose the Multi-Head Self-Attention Convolution (MSA-Conv) that incorporates Self-Attention within generalized convolutions, including standard, dilated, and depthwise ones. Enabling transformers to handle images of varying sizes without retraining or rescaling, the use of MSA-Conv further reduces computational costs compared to global attention in ViT, which grows costly as image size increases. Later, we present the Vision Transformer in Convolution (TiC) as a proof of concept for image classification with MSA-Conv, where two capacity enhancing strategies, namely Multi-Directional Cyclic Shifted Mechanism and Inter-Pooling Mechanism, have been proposed, through establishing long-distance connections between tokens and enlarging the effective receptive field. Extensive experiments have been carried out to validate the overall effectiveness of TiC. Additionally, ablation studies confirm the performance improvement made by MSA-Conv and the two capacity enhancing strategies separately. Note that our proposal aims at studying an alternative to the global attention used in ViT, while MSA-Conv meets our goal by making TiC comparable to state-of-the-art on ImageNet-1K. Code will be released at https://github.com/zs670980918/MSA-Conv.
Create account to get full access
Overview
- This paper explores the integration of Vision Transformer (ViT) components into convolutional neural networks (CNNs) to create a hybrid model called TiC (Transformer in Convolution).
- The key ideas are to leverage the advantages of both ViT and CNN architectures to improve performance on visual recognition tasks.
- The paper proposes several variations of the TiC model and evaluates their performance on various benchmark datasets.
Plain English Explanation
The research paper explores a new type of deep learning model that combines the strengths of two popular approaches: Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs). The resulting hybrid model, called TiC (Transformer in Convolution), aims to take advantage of the ability of ViTs to capture long-range dependencies and the strong local feature extraction capabilities of CNNs.
The core idea is to integrate ViT components, such as self-attention mechanisms, into the convolutional layers of a CNN. This allows the model to learn both local and global visual features more effectively than using either ViT or CNN alone. The paper explores several variations of the TiC architecture and evaluates their performance on standard computer vision benchmarks.
By blending the strengths of these two prominent deep learning approaches, the researchers hope to create a more powerful and versatile model for tasks like image classification, object detection, and other visual recognition challenges. The goal is to develop a hybrid model that can outperform standalone ViT or CNN models while maintaining the efficiency and ease of use that have made these architectures so widely adopted.
Technical Explanation
The paper introduces the TiC (Transformer in Convolution) model, which aims to integrate the advantages of Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) into a single architecture. The key idea is to incorporate ViT components, such as the self-attention mechanism, into the convolutional layers of a CNN.
The proposed TiC framework consists of several variations, including:
- TiC-Conv: Replacing a convolutional layer with a transformer-based layer that performs self-attention within a local window.
- TiC-Parallel: Applying a transformer-based layer in parallel with a convolutional layer, allowing the model to learn both local and global features.
- TiC-Cascade: Stacking multiple TiC-Conv or TiC-Parallel layers to capture multi-scale visual representations.
The authors evaluate the performance of these TiC models on various computer vision benchmarks, such as ImageNet classification, COCO object detection, and Cityscapes semantic segmentation. The results show that the TiC models can outperform standalone ViT and CNN models, demonstrating the potential benefits of combining these two complementary approaches.
The paper also provides insights into the inner workings of the TiC models, analyzing the contributions of the ViT and CNN components and the role of multi-scale feature learning. The researchers discuss the trade-offs between model complexity, computational efficiency, and performance, suggesting that the TiC framework offers a promising direction for developing more effective and versatile deep learning models for visual recognition tasks.
Critical Analysis
The paper presents a compelling approach to integrating ViT and CNN components, which is a timely and relevant area of research in the deep learning community. The authors have carefully designed and evaluated several variations of the TiC model, providing a thorough exploration of the design space.
One strength of the paper is the comprehensive evaluation on multiple benchmark datasets, which helps to validate the generalizability of the TiC models. The performance improvements over standalone ViT and CNN models suggest that the hybrid approach can indeed capture both local and global visual features more effectively.
However, the paper does not fully address the potential limitations and trade-offs of the TiC models. For example, the increased model complexity and computational cost of the TiC-Cascade variant could be a concern for real-world deployment, especially on resource-constrained devices. The authors could have discussed potential strategies to mitigate these issues, such as exploring more efficient ViT architectures or hierarchical ViT designs.
Additionally, the paper does not provide a detailed analysis of the role of mutual attention between the ViT and CNN components, which could offer valuable insights into the synergies between these two architectural paradigms.
Overall, the paper presents a promising step towards developing more effective hybrid models for visual recognition tasks. However, further research is needed to address the potential limitations and explore the full potential of the TiC framework.
Conclusion
The TiC (Transformer in Convolution) paper explores a novel approach to combining the strengths of Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) into a hybrid deep learning model. By integrating ViT components, such as self-attention mechanisms, into the convolutional layers of a CNN, the researchers aim to create a more powerful and versatile architecture for visual recognition tasks.
The paper proposes several variations of the TiC model and evaluates their performance on standard computer vision benchmarks, demonstrating the potential benefits of this hybrid approach. The results suggest that the TiC models can outperform standalone ViT and CNN models, indicating that the integration of these two complementary architectures can lead to improved feature learning and overall model performance.
While the paper presents a promising direction for deep learning research, further work is needed to address the potential limitations and trade-offs of the TiC framework, such as model complexity and computational efficiency. Exploring more efficient ViT designs and hierarchical architectures could help to unlock the full potential of this hybrid approach and pave the way for more powerful and versatile deep learning models for visual recognition and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

You Only Need Less Attention at Each Stage in Vision Transformers
Shuoxi Zhang, Hanpeng Liu, Stephen Lin, Kun He
0
0
The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
6/4/2024

Multi-Modal Vision Transformers for Crop Mapping from Satellite Image Time Series
Theresa Follath, David Mickisch, Jan Hemmerling, Stefan Erasmi, Marcel Schwieder, Begum Demir
0
0
Using images acquired by different satellite sensors has shown to improve classification performance in the framework of crop mapping from satellite image time series (SITS). Existing state-of-the-art architectures use self-attention mechanisms to process the temporal dimension and convolutions for the spatial dimension of SITS. Motivated by the success of purely attention-based architectures in crop mapping from single-modal SITS, we introduce several multi-modal multi-temporal transformer-based architectures. Specifically, we investigate the effectiveness of Early Fusion, Cross Attention Fusion and Synchronized Class Token Fusion within the Temporo-Spatial Vision Transformer (TSViT). Experimental results demonstrate significant improvements over state-of-the-art architectures with both convolutional and self-attention components.
6/26/2024
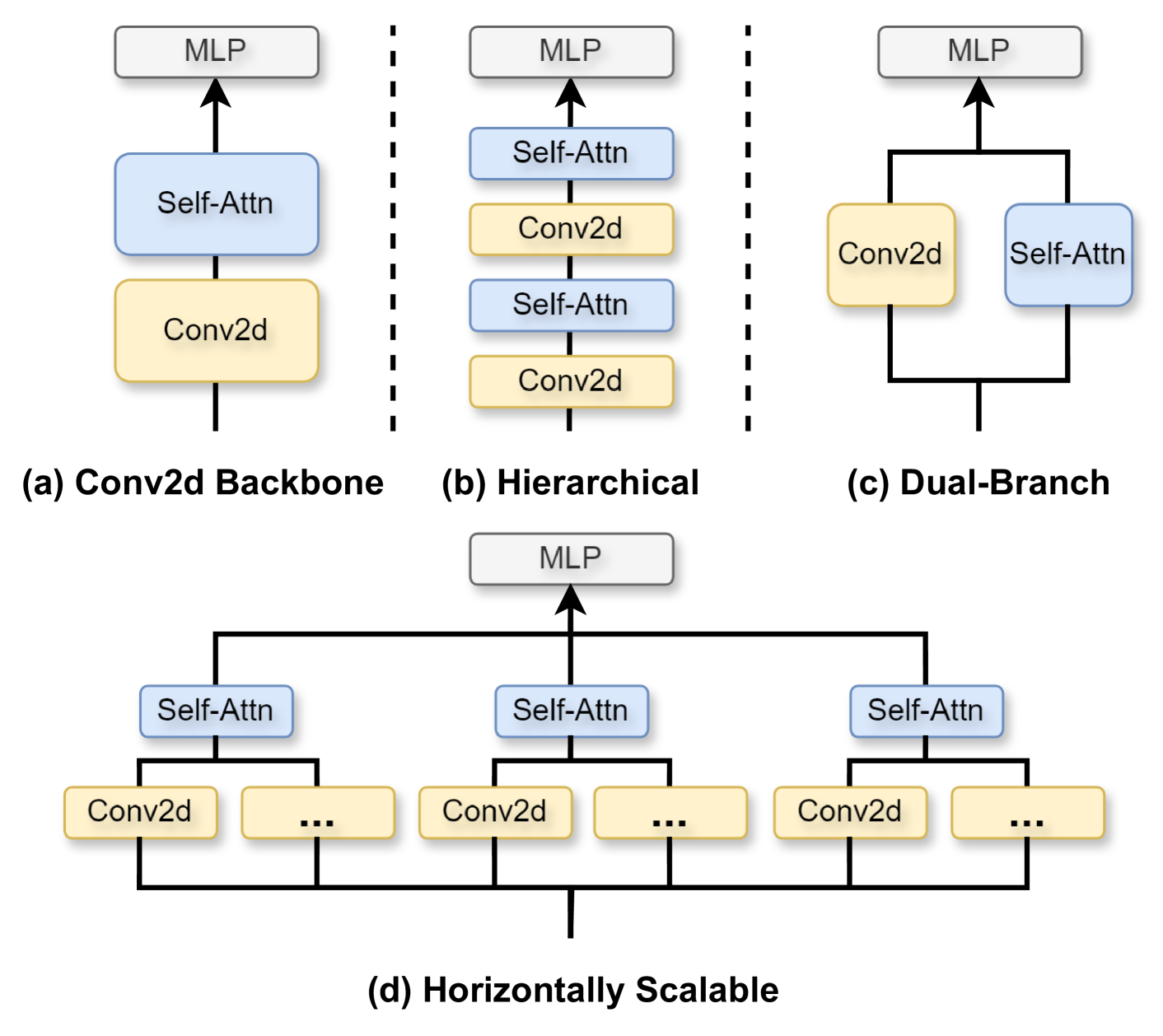
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
0
0
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
4/9/2024

ToSA: Token Selective Attention for Efficient Vision Transformers
Manish Kumar Singh, Rajeev Yasarla, Hong Cai, Mingu Lee, Fatih Porikli
0
0
In this paper, we propose a novel token selective attention approach, ToSA, which can identify tokens that need to be attended as well as those that can skip a transformer layer. More specifically, a token selector parses the current attention maps and predicts the attention maps for the next layer, which are then used to select the important tokens that should participate in the attention operation. The remaining tokens simply bypass the next layer and are concatenated with the attended ones to re-form a complete set of tokens. In this way, we reduce the quadratic computation and memory costs as fewer tokens participate in self-attention while maintaining the features for all the image patches throughout the network, which allows it to be used for dense prediction tasks. Our experiments show that by applying ToSA, we can significantly reduce computation costs while maintaining accuracy on the ImageNet classification benchmark. Furthermore, we evaluate on the dense prediction task of monocular depth estimation on NYU Depth V2, and show that we can achieve similar depth prediction accuracy using a considerably lighter backbone with ToSA.
6/14/2024